- The paper introduces an integrated system for end-to-end quadrotor autonomy, achieving high sample efficiency and zero-shot sim-to-real transfer.
- It leverages a high-performance differentiable simulation with VisFly and BPTT optimization to outperform traditional PPO in convergence speed and training efficiency.
- The system ensures robust policy validation and deployment via sim-to-sim and hardware-in-the-loop pipelines while incorporating domain randomization, precise system identification, and latency compensation.
E2E-Fly: An Integrated System for Robust End-to-End Quadrotor Autonomy
Introduction
E2E-Fly presents a unified, technically comprehensive workflow for end-to-end quadrotor autonomy, from task specification and training to validation and sim-to-real policy transfer. The platform consolidates high-performance differentiable simulation, rigorous reward design, validated cross-simulator and hardware-in-the-loop (HIL) testing pipelines, and physical quadrotor deployment. E2E-Fly addresses persistent issues—sample efficiency, reward engineering, alignment, and reproducibility—by offering a stack that integrates precise system identification, latency compensation, domain randomization, and noise modeling. The architecture is intended to streamline reproducible research in agile flight, vision-based perception, and reinforcement learning (RL)/differentiable simulation-based control for aerial robotics.
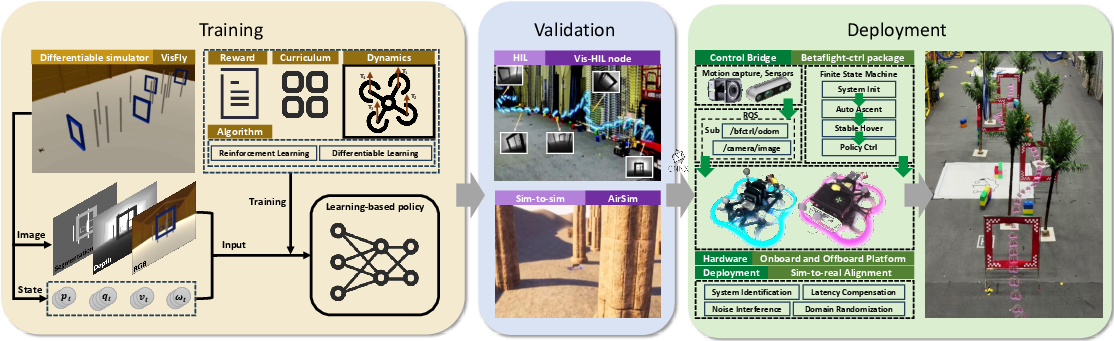
Figure 1: Overview of the E2E-Fly architecture, showing data flow from perception and reward design in VisFly through cross-platform evaluation and real-world deployment, mediated by betaflight-ctrl.
System Architecture and Components
Simulator and Policy Training
Core training utilizes VisFly, a high-throughput, parallelizable simulator with both analytical gradients and accurate physical dynamics. VisFly supports multi-modal sensing (e.g., RGB, depth, segmentation, IMU) at up to 6000 FPS at modest resolutions, and supports four control interfaces, with a focus on collective thrust plus body rates (CTBR), shown to be highly effective for direct policy output in quadrotor tasks [CTBR1] [CTBR2] [CTBR3].
Differentiable simulation (DS) is enabled via implementation of the complete dynamics model and reward function in PyTorch. This provides the analytic gradients required for Back-Propagation Through Time (BPTT) optimization. Simultaneously, the architecture supports black-box RL algorithms, with Proximal Policy Optimization (PPO) as the baseline. The comparative study demonstrates that BPTT, leveraging the physical model’s differentiability, achieves significantly superior convergence speed and sample efficiency compared to PPO, given equivalent computational resources.
Validation: Sim-to-Sim and Hardware-in-the-Loop
The validation stage introduces rigorous policy verification before any real-world deployment. First, a sim-to-sim transfer interface connects VisFly-trained policies to AirSim, exposing them to an alternative physics/renderer stack to highlight overfitting and simulator-specific artifacts. Second, a hardware-in-the-loop (HIL) framework places a real quadrotor in a motion capture system and injects it into a photorealistic virtual environment, preserving true dynamics and proprioceptive sensing but safely supporting high-aggression perception tasks.
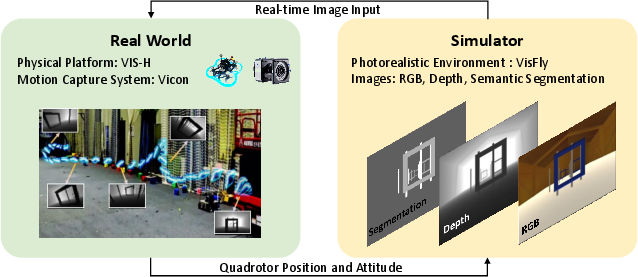
Figure 2: Hardware-in-the-loop architecture: real quadrotor in motion capture, real-time virtual perception pipeline, and cross-modal validation in diverse scenes.
Two physical platforms are introduced: VIS-R (real-time inference onboard, with Intel N100 + D435i RGB-D) and VIS-H (offboard control via wireless link, optimized for HIL and safe aggressive maneuvers).
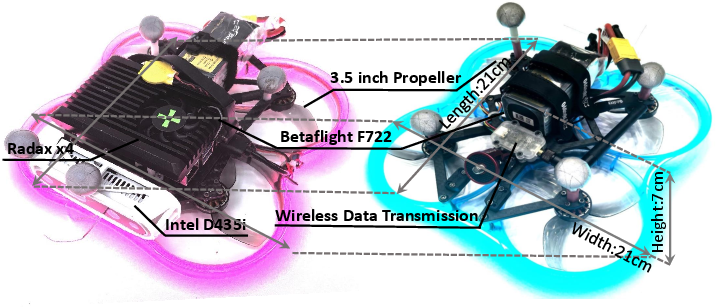
Figure 3: VIS-R and VIS-H platforms, detailing sensor, compute, and communication strategies for real-world experiments.
Deployment is supported by betaflight-ctrl, which mediates between the high-level policy and Betaflight-compatible flight controllers and provides online state feedback, telemetry, and controlled failover mechanisms. It supports multiple command modes and robust real-time diagnostics.
Sim-to-Real Alignment
A robust sim-to-real methodology is crucial for successful policy transfer. E2E-Fly integrates four core alignment techniques:
- System Identification: Rigorous mass, inertia, thrust, drag, and motor system identification via precise modeling (digital twin for inertia, physical test stands for propulsion mapping).
(Figure 4, Figure 5)
Figure 4: Digital prototype for accurate inertia estimation.
Figure 5: Motor system identification on LY-5KGF bench for parameter extraction.
- Latency Compensation: Empirical measurement of end-to-end actuation and comms latency (typically 30–90 ms, action-frame compensated) by step-response matching across sim and hardware. Residual mismatch after compensation is rendered negligible for closed-loop performance.

Figure 6: Step-response alignment between simulation and hardware for angular rates and thrust.

Figure 7: Policy output response closely aligned post-latency compensation.
- Domain Randomization: Task-specific randomization of initial state, environment geometry, and sensory noise, informed by empirical studies on overfitting and generalization. Randomization is minimized for intrinsic system parameters—made unnecessary by accurate system identification—maximizing training efficiency without degrading transferability.
- Noise Modeling: Injection of task-appropriate sensor and actuator noise (e.g., Gaussian, speckle, Redwood depth model for D435i), essential for robust perception-based policy transfer.
All four stages are tightly coupled in a streamlined pipeline, minimizing sim-to-real performance gaps without extensive real-world retraining.
Reward Design and Curriculum Learning
E2E-Fly contributes a systematized reward-design framework covering dense shaping appropriate for differentiable simulation, sparse terminal rewards for RL, and composite structures for hybrid scenarios. Dense rewards cover canonical progress, smoothness, orientation, linear and angular velocity regularization, and safety-critical collision avoidance, with explicit parameter guidelines for each class of benchmark task. Curriculum learning is harnessed for complex, long-horizon or high-speed tasks, progressing from trivialized subgoals to dense, randomized environments, ensuring tractable optimization and robust ultimate behavior.
Experimental Results
Sample Efficiency and Policy Quality
Comprehensive experiments across six canonical tasks—hovering, landing, tracking, racing, visual landing, and racing with obstacles—validate the system’s efficacy. For all state-based (proprioceptive) tasks, differentiable simulation converges to optimal policies with less than 20% of the samples and training time compared to PPO, at essentially identical computational cost (see Figure 8).

Figure 8: Comparative reward curves—BPTT achieves rapid, robust convergence compared with PPO.

Figure 9: Representative simulation scenarios confirming successful policy attainment.
Ablation experiments confirm the necessity of each reward component for stability, safety, and agility (see Figures 8 and 9).

Figure 10: PPO reward ablation; removing velocity, progress, or smoothness terms degrades performance.

Figure 11: BPTT reward component ablation—dense reward structure critical for differentiable policy success.
Visual Policy Generalization
In vision-based tasks (landing using only segmentation, aggressive racing with depth), both PPO and BPTT achieve robust zero-shot generalization across unseen environment variations. The sample efficiency of BPTT for vision-landing is particularly strong—task completion in 1×106 steps without explicit target knowledge (Figures 10, 11, 12).
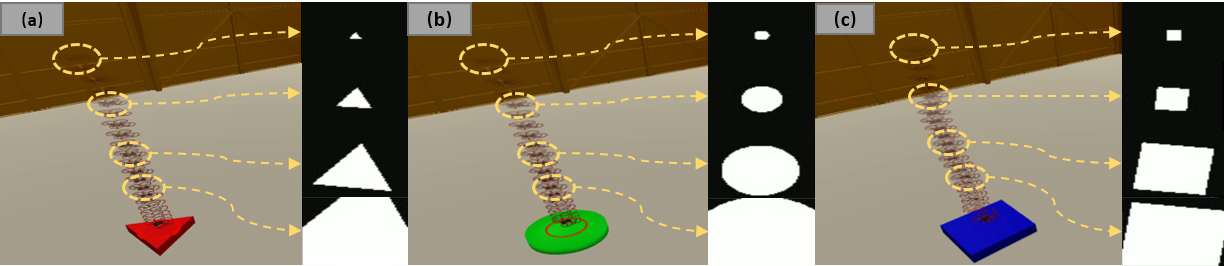
Figure 12: Vision-based landing—identical policy deploys successfully across multiple landing pad geometries.

Figure 13: Obstacle-avoidant aggressive racing with vision-based cues on diverse track topologies.

Figure 14: Reward and success rate trajectories for visual tasks.
Zero-Shot Sim-to-Real Transfer
After alignment, policies are deployed directly (zero-shot) to both VIS-R and VIS-H quadrotors. Step-response and full closed-loop task behavior are matched with high fidelity between simulation and hardware (Figures 15, 1, 14), with hardware-in-the-loop serving as an additional safeguarding stage.

Figure 15: Zero-shot sim-to-real transfer—sim-trained policy deployed with identical functional performance on real hardware.
Theoretical and Practical Implications
E2E-Fly rigorously exposes the trade-offs and complementarities between RL and differentiable simulation. BPTT exhibits overwhelming benefit for continuous, short-horizon, reward-dense problems—enabling high sample efficiency and stable convergence. It is, however, hampered by gradient instability for long-horizon or non-smooth/sparse-reward problems. RL (PPO), while less efficient, is robust to model errors, noise, and sparse terminal rewards. This motivates future research into hierarchical or hybrid frameworks, where RL is used for exploration and high-level decision making, and differentiable simulation refines low-level continuous control.
The platform standardizes evaluation, system identification practice, reward shaping, and sim-to-real alignment, thereby advancing reproducibility and accelerating iterative development cycles for autonomous aerial robotics. Its efficacy for vision-based, perception-limited, and aggressive tasks is particularly critical for domains such as agile inspection, high-speed search, and collaborative aerial manipulation.
Future Directions
E2E-Fly’s modularity allows further seamless integration of independent task curricula, meta-learning, transfer learning strategies, and adaptive reward shaping for long-horizon tasks. Integration with advanced vision pipelines (SWIR, event-based cameras), multi-agent coordination, and real-time adaptation/optimization will further reduce the sim-to-real barrier. The comprehensive dataset of policies, trajectories, and domain parameters produced is valuable for benchmarking, open challenge formulation, and transferability studies.
Conclusion
E2E-Fly constitutes an advanced, extensible reference architecture and methodology for robust, efficient end-to-end quadrotor training-to-deployment. Through the convergence of differentiable simulation, systematic reward design, structured validation, and robust alignment, the framework realizes high-performance, reproducible zero-shot sim-to-real transfer across a spectrum of canonical and vision-based aerial robot tasks. This foundation will facilitate both algorithmic research and applied robotics deployment in agile, perception-driven autonomy.
Paper Reference: "E2E-Fly: An Integrated Training-to-Deployment System for End-to-End Quadrotor Autonomy" (2604.12916).

