- The paper demonstrates a differentiable simulation pipeline that trains a vision-based control policy for precise UAV gap traversal.
- It employs a recurrent network with bimodal initialization and a Stop-Gradient operator to maintain policy stability and rapid post-traversal recovery.
- Experimental results validate strong sim-to-real transfer, with robust performance in both simulated and real-world scenarios involving irregular and occluded gaps.
Vision-Based End-to-End Learning for UAV Traversal of Irregular Gaps via Differentiable Simulation
Introduction
This paper introduces a vision-based, end-to-end control framework for quadrotor UAVs to traverse narrow and irregular gaps using differentiable simulation. Existing methods for UAV gap traversal either rely on explicit perception and geometric priors, which limits robustness and generalization, or assume regular gap shapes, restricting practical applicability. The presented system directly maps raw depth images to control commands and operates fully in the SE(3) space, enabling both position and orientation control. The approach leverages differentiable simulation, a Stop-Gradient (SG) operator, and a Bimodal Initialization Distribution (BIO) to achieve robust and stable traversal, including through multiple consecutive gaps and in previously unseen environments.
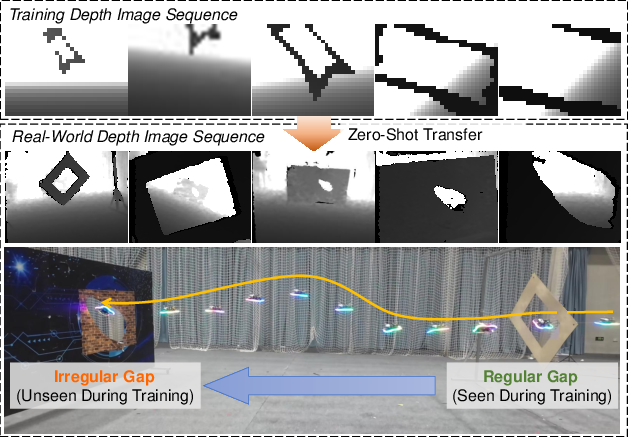
Figure 1: Visualization of the training and real-world evaluation pipeline, demonstrating domain transfer from simulation to real world and generalization from regular to irregular gap structures.
Methodology
Differentiable Simulation Environment
The core of the framework is a differentiable simulation pipeline with a mesh-based, CUDA-accelerated depth renderer capable of producing high-throughput depth images from procedurally generated mesh gaps. Domain randomization is extensively used by varying gap shapes, tilt, and occlusion properties, which forces the policy to generalize beyond specific geometric priors.
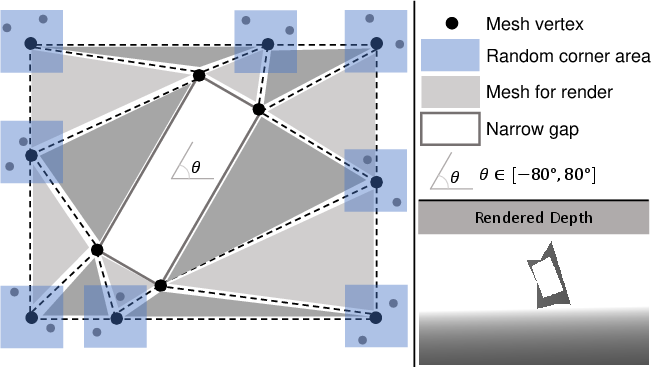
Figure 2: The mesh-based depth renderer efficiently generates diverse synthetic depth images for various gap geometries by randomizing vertices and angles.
Quadrotor dynamics are modeled using a differentiable Collective Thrust and Body Rate (CTBR) model. This enables backpropagation of task losses through visual perception and state transition, achieving true end-to-end learning and allowing optimization via Backpropagation Through Time (BPTT). The objective combines terms for position and attitude at gap traversal, forward direction alignment, velocity tracking, and smoothness in both action and jerk.
Policy Architecture and Optimization
The control policy is a recurrent neural network using a CNN encoder for single-channel inverse depth images and a GRU core. Inputs include the processed depth image, partial quadrotor state, and a modulated target velocity with substantial random perturbations, making the latter more of a guidance than a reference.
At training time, a bimodal initialization distribution exposes the policy to both stable and high-velocity states, corresponding to pre- and post-traversal flight, addressing the challenge of rapid stabilization after aggressive maneuvers. The SG operator is used strategically in key loss terms to block spurious gradients, ensuring stable optimization even for high tilt and large-angle gaps.
Auxiliary Prediction Modules
Two lightweight auxiliary modules operate on the policy’s recurrent hidden state: a gap-crossing classifier, which enables hidden state reset after each successful traversal facilitating continuous multi-gap navigation, and a traversability predictor, which provides a scalar estimate of whether passage through the gap is feasible, serving as a proactive safety mechanism.
Experimental Evaluation
Simulation Experiments
The approach is evaluated extensively in both the custom differentiable simulator and AirSim. Experiments include single-gap, multi-gap, and wall-mounted gap scenarios with varying gap tilts, offsets, and occlusions.

Figure 3: AirSim simulation scenarios include single-gap, multi-gap, and wall-mounted gap traversals, allowing controlled study of policy generalization and robustness.
Baseline comparisons include a PPO-based RL agent with an explicit edge detection preprocessor and a state-of-the-art vision-based policy. The presented approach achieves higher success rates, notably under perception noise (SGM-computed depth), where front-end-based methods fail. Performance ablations indicate that absence of the SG operation results in severe position and attitude errors, especially for high-tilt gaps. Bimodal initialization is shown to be critical for minimizing error accumulation in multi-gap traversals.
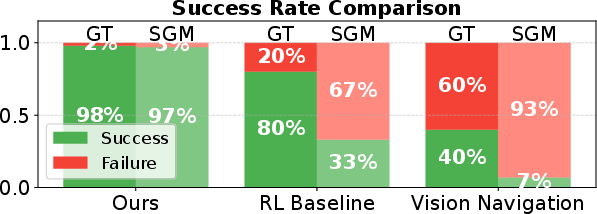
Figure 4: Baseline comparison in AirSim shows the end-to-end policy significantly outperforms PPO+explicit perception and previous vision-based policies, especially under degraded input conditions.
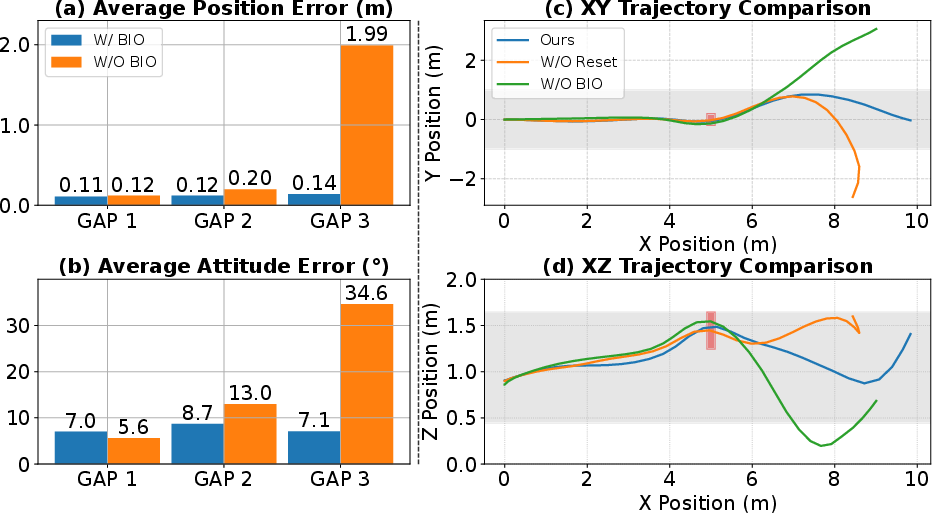
Figure 5: Ablation results showing that the combination of bimodal initialization and gap-crossing state reset is necessary for maintaining low error across sequences of consecutive gaps.
Real-World Deployment
The trained policy is evaluated on a small form-factor quadrotor equipped with a depth camera and onboard edge compute. Without any fine-tuning, the policy generalizes to real-world gaps—both regular and irregular (e.g., occluded, non-rectangular, partial obstacles)—achieving high success rates even in cases far outside the training distribution.

Figure 6: Real-world trajectory results display robust gap traversal—including highly irregular and partially occluded scenarios—with high success rates per environment.
The traversability prediction module reliably triggers emergency stops when safe traversal is not possible, validating its safety utility in practical deployments.
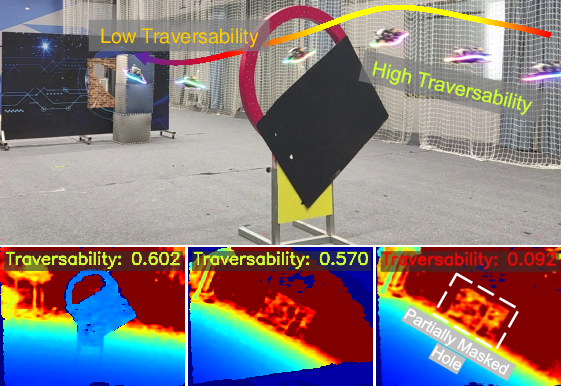
Figure 7: The traversability score falls sharply when the UAV is presented with an occluded gap, resulting in a preemptive abort and improved operational safety.
Additional Analyses
Experiments demonstrate that substantial perturbations to the target direction input do not prevent successful traversal as long as the gap enters the field of view in time. The traversability predictor’s performance saturates with increasing hidden layer size, with only marginal gains beyond a moderate network width.
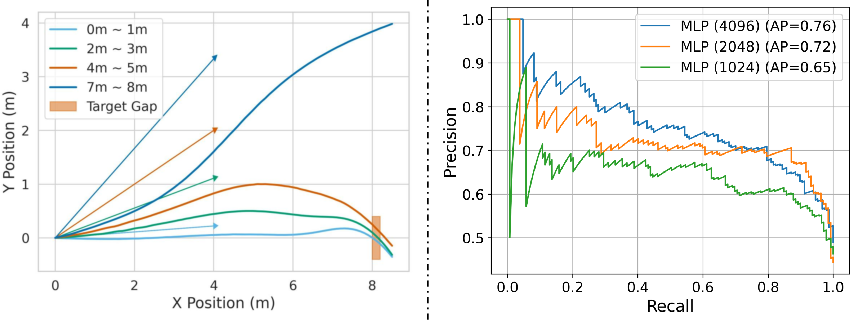
Figure 8: (Left) Average trajectories under increased target direction noise remain robust except at extreme perturbations. (Right) PR curves showing the saturating performance of the traversability module across increasing MLP sizes.
Discussion and Implications
The proposed method demonstrates that a carefully designed differentiable simulation-based training protocol—leveraging mesh-based randomized rendering, robust dynamics modeling, and proper loss engineering—enables direct sim-to-real transfer for safety-critical, vision-based UAV navigation in highly unstructured and unseen environments. The use of auxiliary modules based solely on recurrent state evidence represents a minimal overhead approach that maintains system reactivity and safety.
Implications for future research include potential integration with global obstacle avoidance, adaptive online estimation of traversability for dynamic or deformable gaps, and further reductions in onboard computation via model compression. The presented architecture is a direct candidate for field-deployable UAVs in search-and-rescue, infrastructure inspection, and other applications where environment geometry cannot be assumed or supervised a priori.
Conclusion
This work establishes an effective framework for dynamic, vision-based UAV gap traversal grounded in differentiable simulation and principled policy design. The system achieves robust sim-to-real transfer and strong generalization to irregular and occluded gaps, minimizes reliance on explicit perception modules, and sustains real-time computation onboard compact UAVs. The demonstrated effectiveness and scalability suggest broad applicability, and future enhancements may further close the gap toward fully autonomous vision-based UAV navigation in unconstrained environments.

