- The paper introduces an end-to-end pipeline mapping depth images directly to low-level CTBR commands using gradient-driven RL.
- It integrates high-fidelity 6-DOF quadrotor dynamics with differentiable simulation to achieve robust, agile, and smooth collision avoidance.
- Experimental results demonstrate near-perfect success rates, low trajectory jerk, and effective zero-shot transfer from simulation to hardware.
End-to-End Quadrotor Control via High-Fidelity Differentiable Simulation
Introduction
The paper "Simple but Stable, Fast and Safe: Achieve End-to-end Control by High-Fidelity Differentiable Simulation" (2604.10548) advances vision-based collision avoidance for agile quadrotors by formulating an end-to-end pipeline that directly maps depth images to collective thrust and bodyrate (CTBR) commands using RL within a high-fidelity differentiable simulation. The design eliminates trajectory representation, mapping, and auxiliary controllers, handling system dynamics, smoothness, and perception constraints in a unified optimization. The method obviates the need for complex architectures such as LSTM, backbones, or action primitives, yet achieves superior generalization, flight stability, and safety over a wide range of benchmarks in both simulation and hardware.
Figure 1: Overview of the proposed method—policy training with BPTT through a differentiable high-fidelity simulation precisely aligned to real-world control responses.
Methodological Contributions
The key technical contribution is the direct integration of high-fidelity 6-DOF quadrotor dynamics and collision-based supervision into the differentiable simulation backpropagation pipeline. This approach fully exposes the policy network to all relevant system state transitions, actuator delays, and sensory feedback (depth maps), enabling gradient-driven reinforcement learning with analytical accuracy rather than critic approximation.
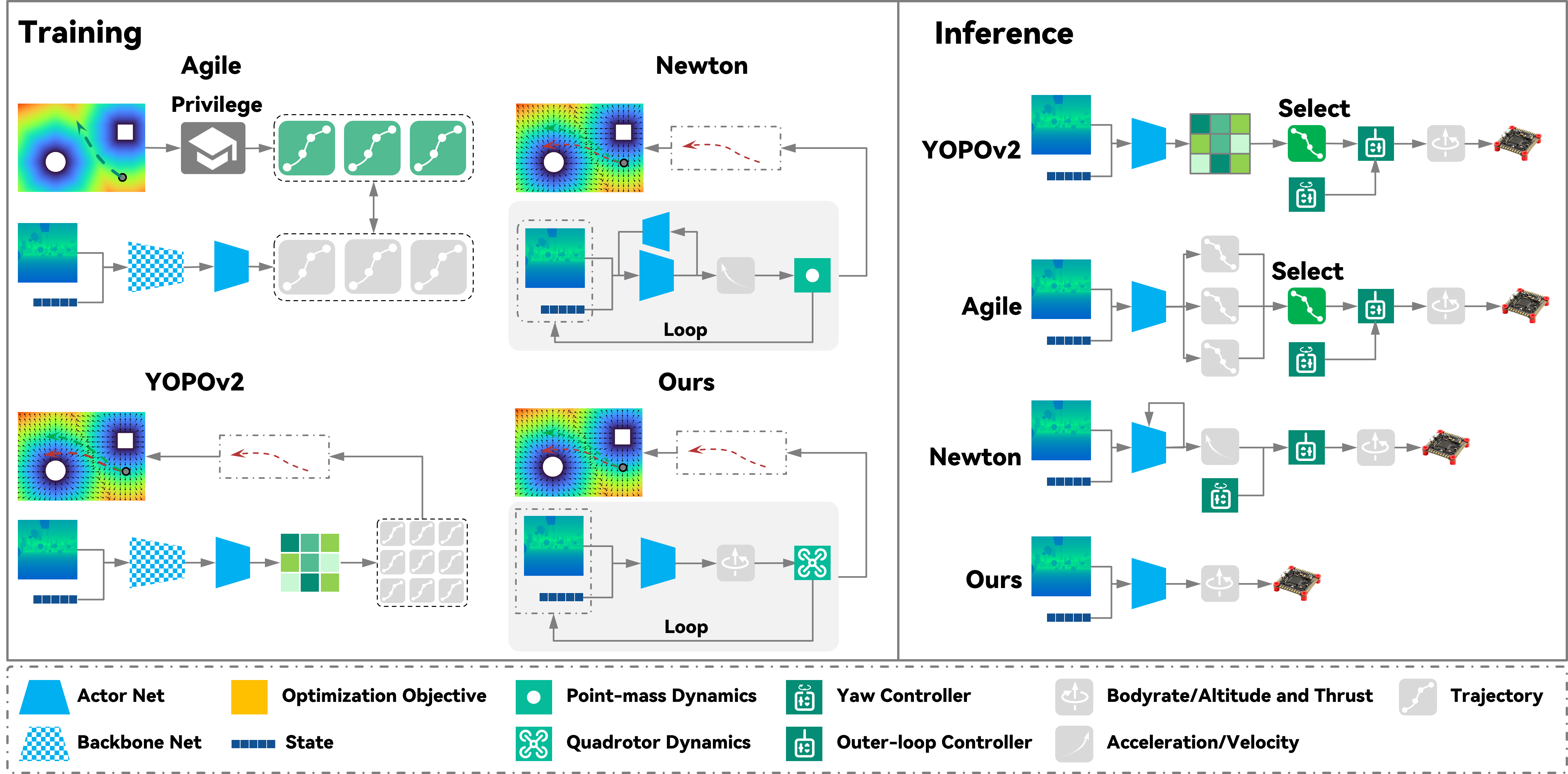
Figure 2: Training and inference pipeline achieves true end-to-end CTBR command output, removing trajectory/velocity abstraction and closing the perception-to-controller loop.
The pipeline avoids simplified kinematics or decoupled control stages, which tends to introduce dynamics-infeasibility and significant sim-to-real gaps in aggressive flight. It also utilizes a lightweight network (3-layer CNN + 2-layer MLP feature aggregator) without temporal recurrence, ensuring low-latency, resource-efficient onboard inference.
The reward structure incorporates velocity tracking, perception alignment, attitude stability, penalization of proximity to obstacles, and direct collision loss. Notably, the collision reward is implemented as a differentiable supervision over the predicted trajectory in the rollout, supporting robust and smooth avoidance behaviors.
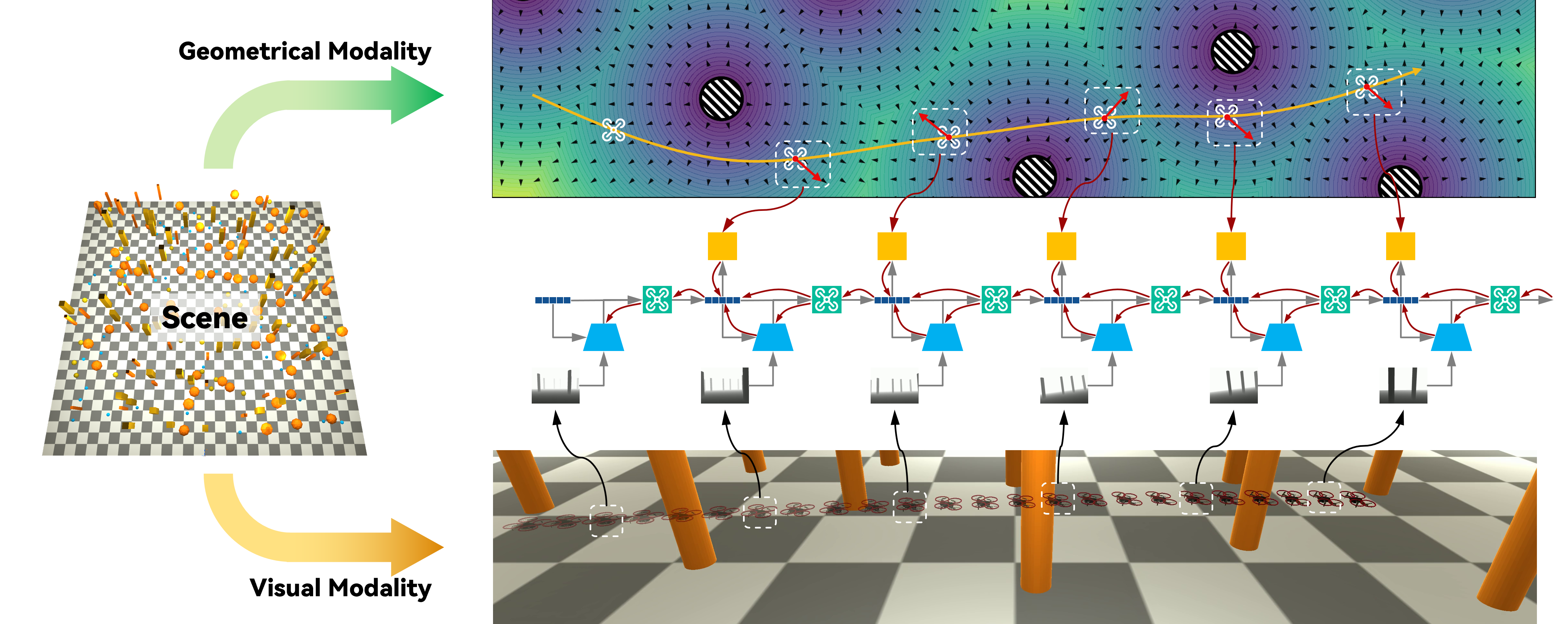
Figure 3: Multimodal representation supervision—gradient flow from geometrical (collision-based) reward is backpropagated through the differentiable simulation to graphical features extracted from images.
Analytical derivations and implementations in PyTorch ensure that backpropagation-through-time (BPTT) can be accomplished through long, highly nonlinear dynamical graph composed of motor allocation, actuation delay, and high-frequency state updates, without gradient explosion/vanishing within modest horizons.
Gradient Field Reshaping
A critical insight in the paper is the identification and mitigation of the "braking over avoidance" bias induced by Euclidean Signed Distance Field (ESDF) collision penalties in dense/complex clutter, which manifest as "death zones" in the gradient field. The authors present a targeted transformation of the local gradient by adaptively rotating the effect direction laterally as a function of proximity and approach angle, thus reshaping the field to promote active avoidance rather than excessive braking.
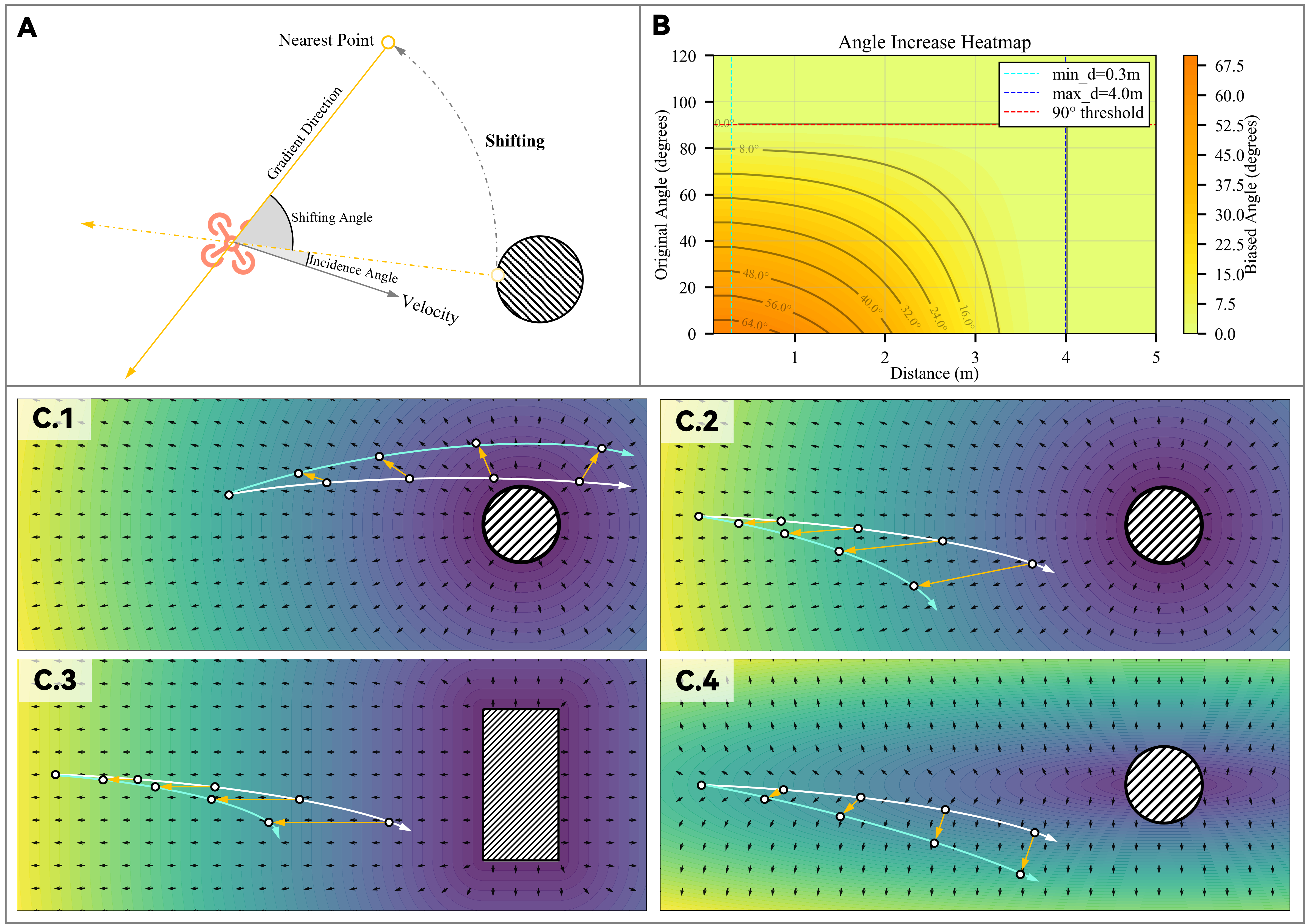
Figure 4: ESDF map reshaping—transforming the gradient field from dominance by braking (red zones) to avoidance by adaptive lateral shifting of collision supervision.
This enables superior forward progress and stability, especially in super-dense scenarios, without sacrificing collision penalties.
Experimental Results
Simulated Benchmarks
An extensive evaluation across benchmarks (large-scale forests with densities up to 0.08 obstacles/m² and super-dense settings at 0.25 obstacles/m²) demonstrates that the method consistently yields near-perfect success rates, completion, and the lowest jerk of all compared methods (including EGO-Planner, Agile, YOPOv2, Newton), over speeds up to 12 m/s. The superiority is especially pronounced as both density and speed increase, where modular or imitation-based approaches degrade rapidly due to perception-latency, planning lag, or controller tracking failure.

Figure 5: Large-scale forest environments at four obstacle densities, used for systematic performance evaluation.

Figure 6: Policy rollouts (successes and comparison to baseline failures) in one scene, highlighting smoothness and robustness of direct low-level control.
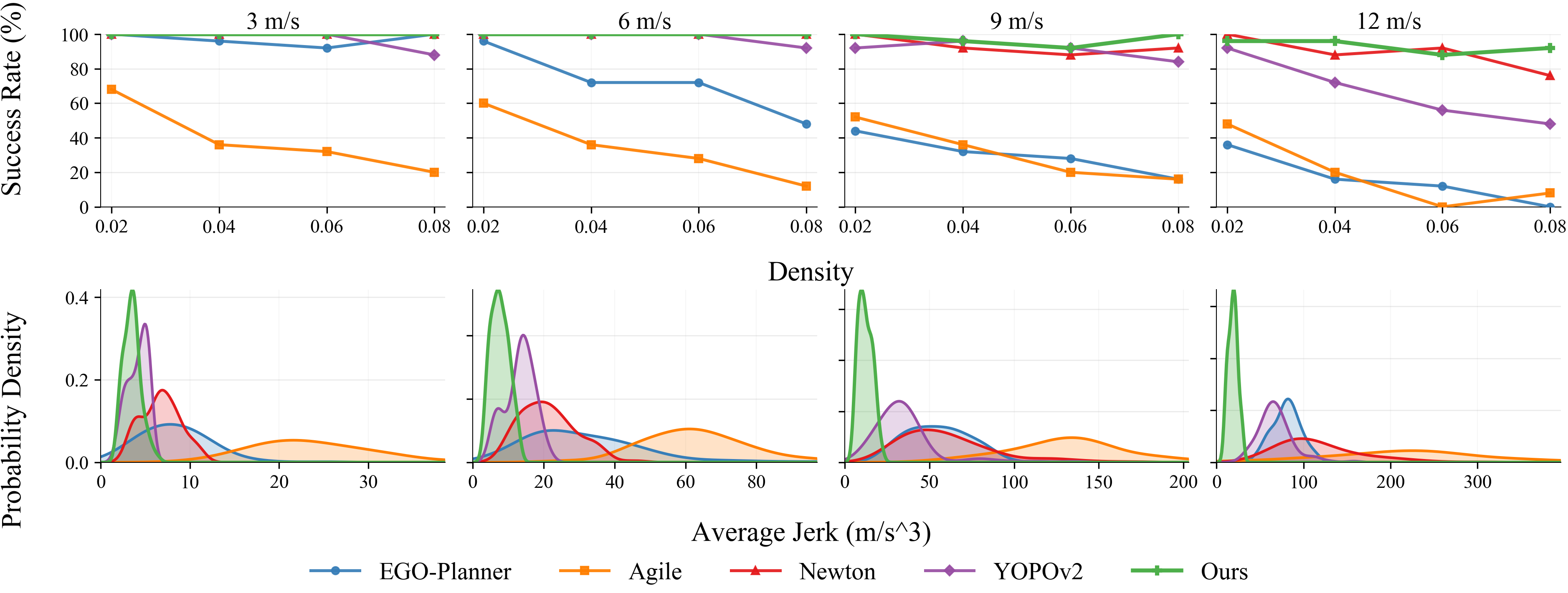
Figure 7: Top—success rates across densities and speeds; bottom—distribution of average jerk, demonstrating consistently smoother trajectories for the proposed method.
In super-dense cases, the method maintains full reliability and higher effective forward velocity than even Newton (differentiable physics + point-mass), which suffers from conservative braking and residual dynamics mismatch. The policy does not require privileged or curriculum learning, further demonstrating the effectiveness of precise gradient propagation through high-fidelity models.
Figure 8: Panoramic views of super-dense environments at highest tested densities.
Real-World Deployment
Zero-shot policy transfer is demonstrated on custom quadrotor hardware with onboard state estimation and depth sensing, in regular (0.1 m⁻²) and super-dense (∼1 m⁻²) forests, as well as diverse urban and wild scenes. The drone reliably maintains forward-looking perception and safe velocities, automatically adjusting speed in response to increased clutter. The system can attain up to 7.5 m/s in regular forest and 5 m/s in super-dense settings, with minimal oscillation or aggressive corrective maneuvers. In contrast, Newton-like methods experience perception loss due to unavoidable vertical oscillations stemming from misaligned dynamics/controls.
Figure 9: Real-world experiment—flight trajectory and first-person view in regular forest at high speeds (up to 7.5 m/s).
Figure 10: Real-world trajectory and first-person view in super-dense forest—robust velocity adaptation and collision avoidance.

Figure 11: Generalization tests in various wild and urban environments confirm broad deployment capability.
Theoretical and Practical Implications
This work rigorously demonstrates that direct, differentiable, high-fidelity RL pipelines can accomplish robust, agile flight control without complex architectures, handcrafted controllers, or multi-stage heuristics. Analytical gradients propagated through physical models are shown to scale in complexity to real-world, multi-module systems, extending beyond idealized kinematics to encompass perception, actuation, and collision. The approach decisively addresses the pervasive dynamics-infeasibility and perception instability of prior modular or surrogate models in high-speed, real-world settings.
The proposed pipeline is highly applicable to other complex robotic tasks where low-level control and perception are tightly integrated, and where the sim-to-real gap is dominated by unmodeled or misrepresented dynamics.
Limitations and Future Directions
While the approach is unrivaled for generic collision avoidance and safety control, it does not explicitly encode global planning competency for non-convex environments (e.g., mazes), and may require high-level directional goals for full autonomy in such scenarios. The lack of recurrency, while beneficial for stability and latency, might limit adaptability in longer-horizon, heavily occluded, or multi-agent contexts. Integration with lightweight global planners or hierarchical RL is a natural avenue for future exploration.
Conclusion
By employing high-fidelity differentiable simulation and BPTT-driven RL, the paper achieves state-of-the-art stable, agile UAV control with the simplest known end-to-end pipeline—eschewing complex architectures and supporting robust zero-shot deployment in both simulated and real-world dense environments. This research sets a reference for the efficient exploitation of analytical gradients and high-fidelity modeling in robotic learning, with substantial implications for deployable, computation-aware aerial autonomy.

