- The paper introduces an online framework combining differentiable simulation with residual dynamics learning to rapidly adapt robotic policies to unmodeled disturbances.
- It demonstrates an 81% error reduction in state-based hovering and rapid policy updates within 5–10 seconds in real-world quadrotor experiments.
- The method efficiently bridges the sim-to-real gap using a hybrid model and alternating optimization, outperforming conventional baselines in agility and sample efficiency.
Rapid Policy Adaptation via Differentiable Simulation: An Expert Analysis
This essay provides a technical analysis of "Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation" (2508.21065), focusing on the methodology, empirical results, and implications for adaptive robotic control. The work introduces a unified framework for online policy adaptation that leverages residual dynamics learning and differentiable simulation, enabling real-time adaptation of control policies to unmodeled disturbances in both state-based and vision-based settings.
The sim-to-real gap remains a persistent challenge in deploying learning-based controllers on physical robotic systems. Traditional approaches such as domain randomization and Real2Sim2Real pipelines either fail to generalize to out-of-distribution disturbances or require extensive offline retraining, which is impractical for rapid adaptation. The paper addresses this by proposing an online framework that continuously refines both the dynamics model and the control policy using real-world data, with the goal of achieving adaptation within seconds.
System Architecture and Methodology
The proposed system consists of three interleaved components: (1) real-world policy deployment and data collection, (2) residual dynamics learning, and (3) policy adaptation via differentiable simulation. These components operate in parallel, exchanging parameters through ROS nodes for efficient real-time operation.
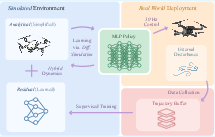
Figure 1: Overview of the key components in the proposed approach, highlighting the interplay between real-world deployment, residual dynamics learning, and differentiable simulation-based policy adaptation.
Differentiable Hybrid Dynamics
The quadrotor is modeled as a discrete-time dynamical system with a hybrid dynamics model fhybrid that combines a low-fidelity analytical model with a learned residual component. The residual model, parameterized as an MLP, predicts the discrepancy between the analytical model and real-world measurements, specifically targeting acceleration errors. The hybrid model is fully differentiable, enabling gradient-based policy optimization via BPTT.
Policy Optimization
Policy learning is formulated as the maximization of cumulative task reward over N-step rollouts. The differentiable simulation allows for the computation of first-order analytical gradients with respect to policy parameters, which are updated using standard optimizers (e.g., Adam). Notably, the framework restricts gradient backpropagation to the analytical model, freezing the residual network during policy updates to improve runtime efficiency without sacrificing performance.
Alternating Optimization Scheme
A key innovation is the alternating optimization between residual dynamics learning and policy adaptation. Real-world data is used to update the residual model, which in turn refines the simulation dynamics for subsequent policy updates. This interleaving ensures that both components are continuously improved using the most recent data, enabling rapid adaptation to changing conditions.
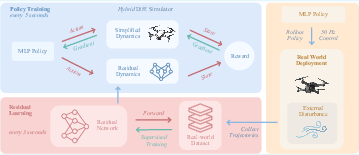
Figure 2: Information flow between the three interleaved components, illustrating parallel execution and data exchange via ROS nodes.
Experimental Evaluation
The framework is evaluated on agile quadrotor control tasks, including stabilizing hover and trajectory tracking, under various disturbance regimes in both simulation and real-world settings. The experiments systematically compare the proposed method against state-of-the-art baselines: Deep Adaptive Tracking Control (DATT, PPO-based), L1-MPC, and a non-adaptive base policy.
Rapid Real-World Adaptation
The system demonstrates the ability to adapt policies within 5–10 seconds of real-world training, significantly outperforming baselines in the presence of large, out-of-distribution disturbances. For state-based hovering, the method achieves an average error of $0.105$ m, representing an 81% reduction over L1-MPC and 55% over DATT.

Figure 3: Real-world policy adaptation for trajectory tracking, showing rapid compensation for sim-to-real gap within two updates (10 seconds).
Robustness to Disturbances
The method maintains stable flight and accurate tracking under payload changes, wind disturbances, and significant model mismatches. In vision-based control, the framework adapts policies without explicit state estimation, a scenario where classical controllers are inapplicable.
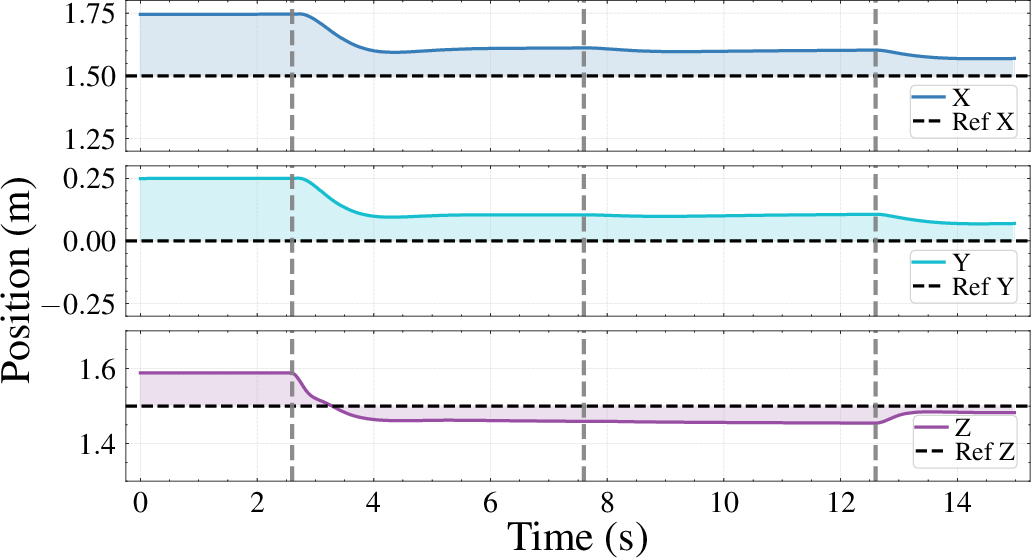
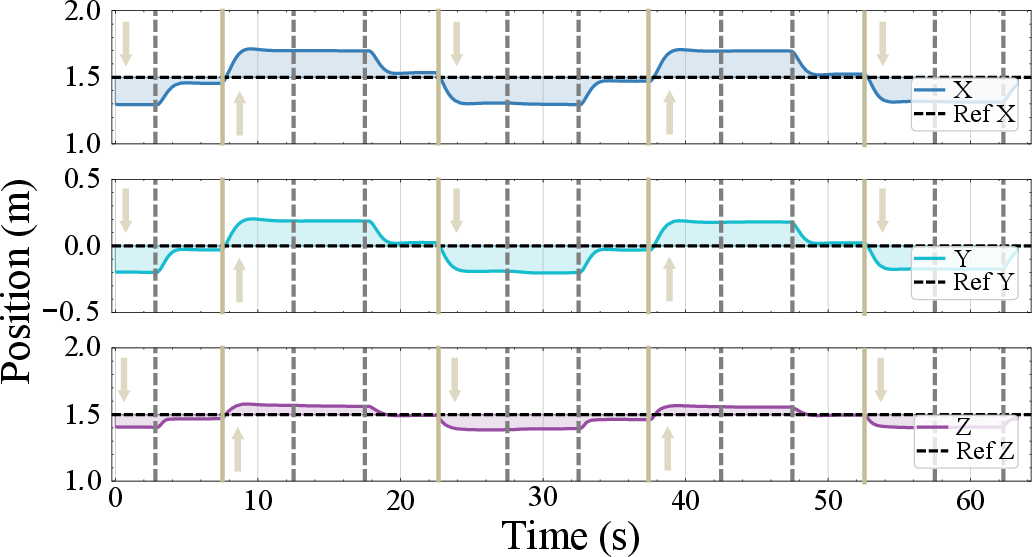
Figure 4: State-based hovering adaptation to a constant large disturbance, demonstrating rapid reduction in error after each policy update.
Sample and Computational Efficiency
The approach achieves high sample efficiency due to the use of first-order gradients from differentiable simulation. Policy pretraining requires only 4.5 million simulation steps (15 seconds wall time), and online adaptation converges within a few seconds. In contrast, DATT requires 20 million steps and two hours of training. The design choice to use a low-fidelity analytical model and restrict backpropagation to this model yields a 2x speedup in training time with negligible impact on final policy performance.
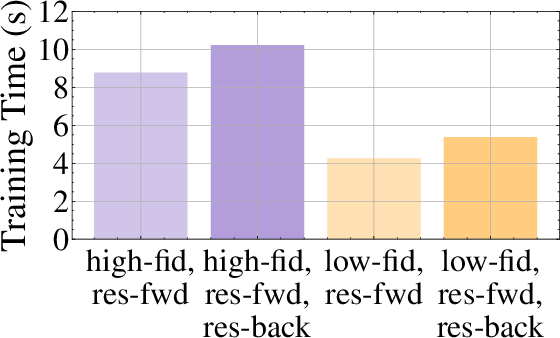
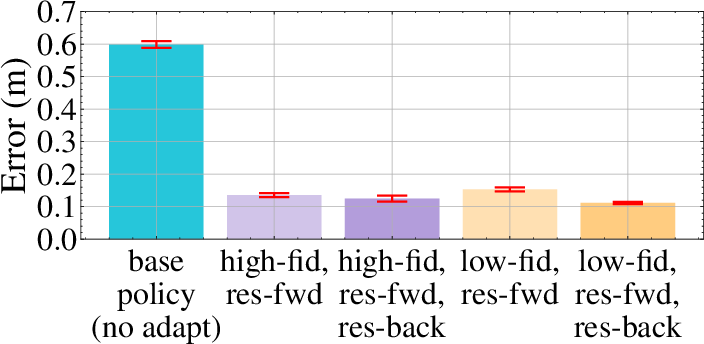
Figure 5: Comparison of policy training times for different simulation configurations, highlighting the efficiency of the proposed design choices.
Design Choices and Ablations
The paper provides a thorough ablation of key design decisions:
- Low-Fidelity vs. High-Fidelity Analytical Models: Low-fidelity models offer significant runtime advantages with minimal loss in policy quality.
- Backpropagation Scope: Restricting gradients to the analytical model (excluding the residual network) accelerates training without degrading performance.
- Full vs. Low-Rank Adaptation (LoRA): Low-rank adaptation achieves comparable performance to full adaptation, suggesting parameter-efficient fine-tuning is viable in this context.
Real-World Validation
The framework is validated on two physical quadrotor platforms with varying mass and inertia. The system adapts to abrupt changes in payload and wind, maintaining stable hover and accurate trajectory tracking. The adaptation process remains robust even under severe sim-to-real gaps and complex, state-dependent disturbances.
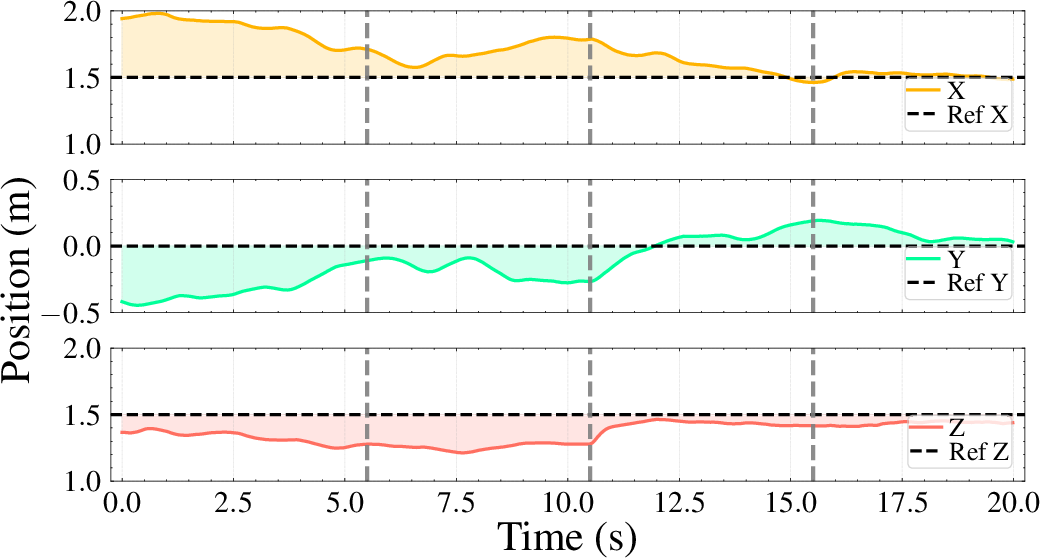
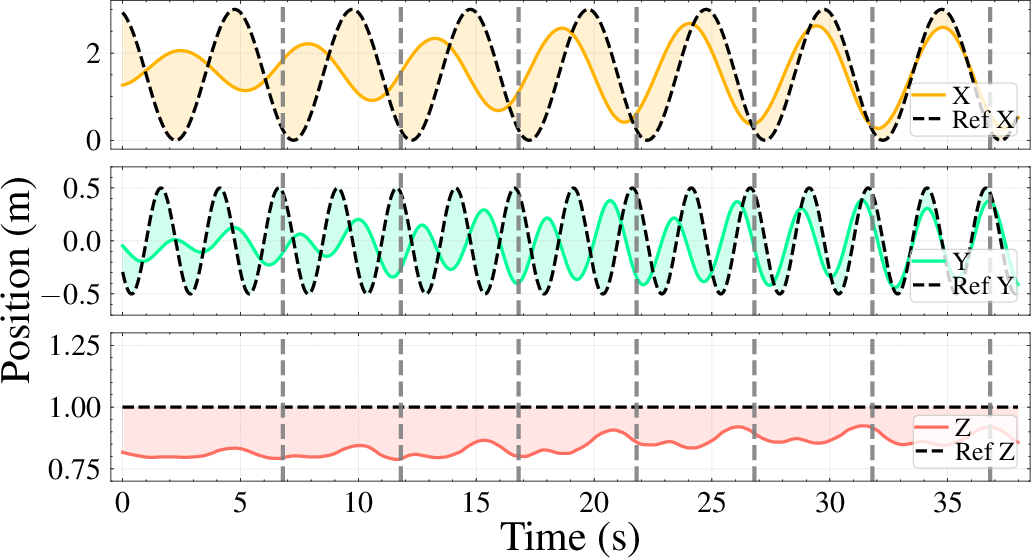
Figure 6: State-based hovering with added mass and wind, showing rapid adaptation and stabilization in the real world.
Implications and Future Directions
This work demonstrates that online residual dynamics learning, when combined with differentiable simulation, enables real-time policy adaptation to unmodeled disturbances, reducing reliance on domain randomization and extensive offline retraining. The approach is applicable to both state-based and vision-based control, broadening its utility in scenarios where state estimation is unreliable or unavailable.
The tightly coupled nature of data collection and policy learning introduces dependencies that may affect convergence under biased or noisy residual models. Future research should explore uncertainty-aware data collection and active exploration strategies to further improve adaptation robustness and sample efficiency.
Conclusion
The paper establishes a practical and efficient framework for rapid policy adaptation in robotics, leveraging differentiable simulation and online residual dynamics learning. The empirical results substantiate strong claims regarding adaptation speed, robustness to out-of-distribution disturbances, and sample efficiency. The methodology is extensible to other domains where real-time adaptation to unmodeled dynamics is critical, and the design choices provide a blueprint for scalable, efficient deployment of learning-based controllers in the real world.

