- The paper introduces a locality-aware sparse attention mechanism (LoSA) that targets the KV Inflation problem in block-wise diffusion LMs.
- It dynamically selects active tokens based on MSE changes and reuses cached outputs for stable tokens, reducing computation and memory traffic.
- LoSA achieves up to 4.14× speedup and a +9% accuracy boost compared to existing sparse attention methods under aggressive sparsity.
LoSA: Locality-Aware Sparse Attention for Block-Wise Diffusion LMs
Introduction
This work addresses a critical inefficiency in block-wise diffusion LLMs (DLMs): despite supporting non-autoregressive generation within blocks (thus unlocking parallelism), these models remain bottlenecked by KV cache access during prefix attention—particularly in long-context inference. The authors identify a previously unaddressed KV Inflation phenomenon, where the union of all queries' prefix attention indices in a block significantly inflates the KV access cost, almost nullifying the practical benefits of sparse attention methods as previously designed for autoregressive LLMs. They propose LoSA, which leverages the strong locality of hidden-state changes across denoising steps in DLMs, and applies sparse attention only to the small subset of tokens that change significantly, while reusing cached attention outputs for the remainder. This enables substantial reductions in KV memory traffic and attention latency while retaining near-dense attention quality.
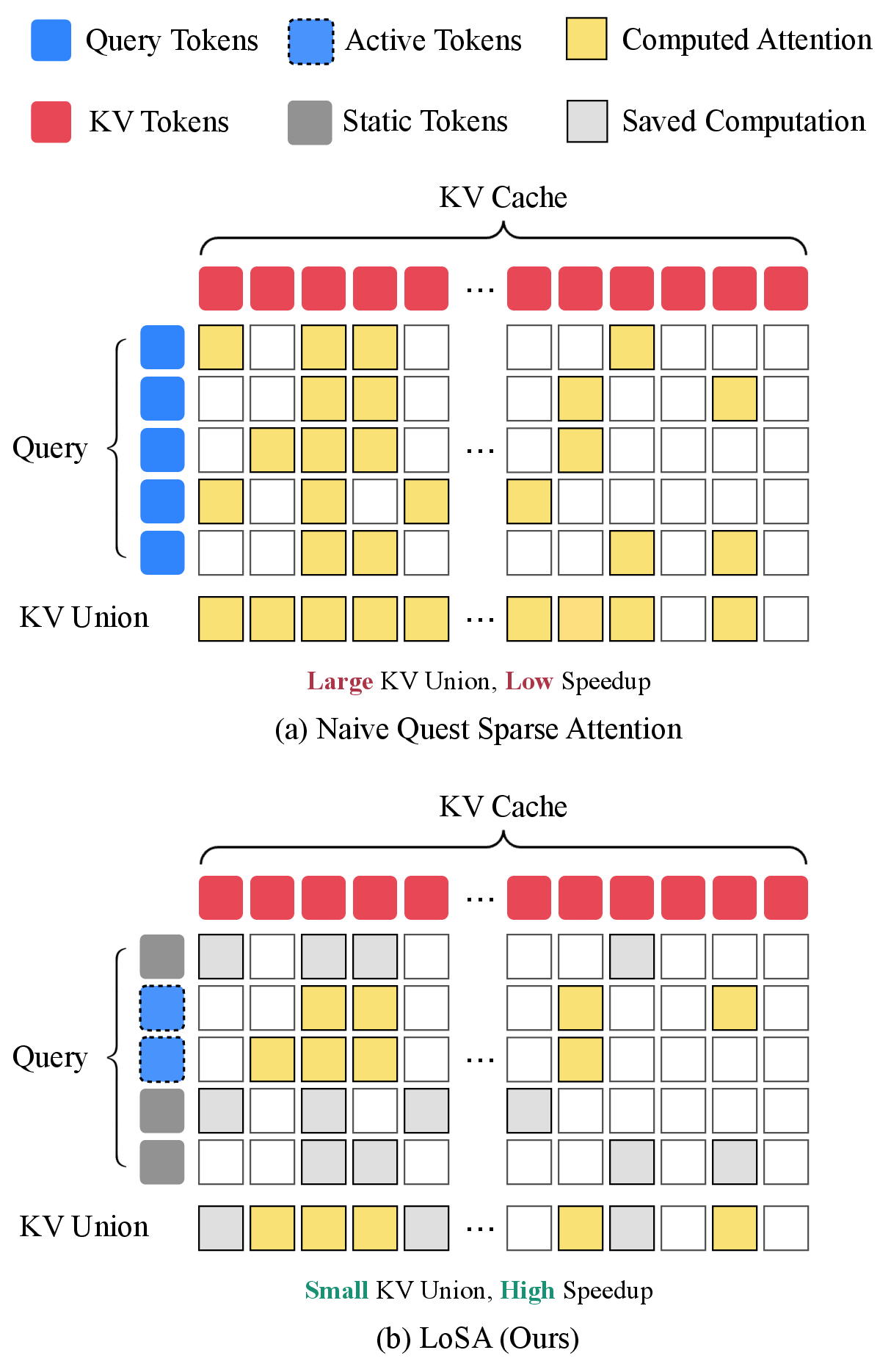
Figure 1: The KV-union effect: in block diffusion, the union of all queries' selected prefix KV positions determines actual memory cost; LoSA reduces this by restricting sparse attention computation to active, changing tokens and reusing cached results for the rest.
Motivation and Problem Analysis
Block-Wise DLMs and the KV Inflation Problem
Unlike standard autoregressive generation, block-wise DLMs generate multiple tokens in parallel blocks via iterative denoising, using a shared prefix KV cache for context. Sparse attention, which provides consistent speedups in autoregressive LLMs, is significantly less efficient in this regime due to the union effect: the union of per-query selected indices often approaches the block size times the per-token budget, greatly increasing required KV memory traffic. The union size, not individual query sparsity, determines runtime and memory bottlenecks.
Locality of Representation Changes
A pivotal empirical observation is that across consecutive denoising steps, only a minority of block tokens undergo substantial changes in their query, key, and value representations ("active" tokens). Most tokens remain almost unchanged and hence their attention outputs can be reused via caching. This token-level locality structure is visualized by tracking per-token MSE changes between steps. Most MSE changes are highly concentrated on a few positions, and the layerwise distribution is also non-uniform, which motivates a dynamic, token-level adaptive attention strategy.
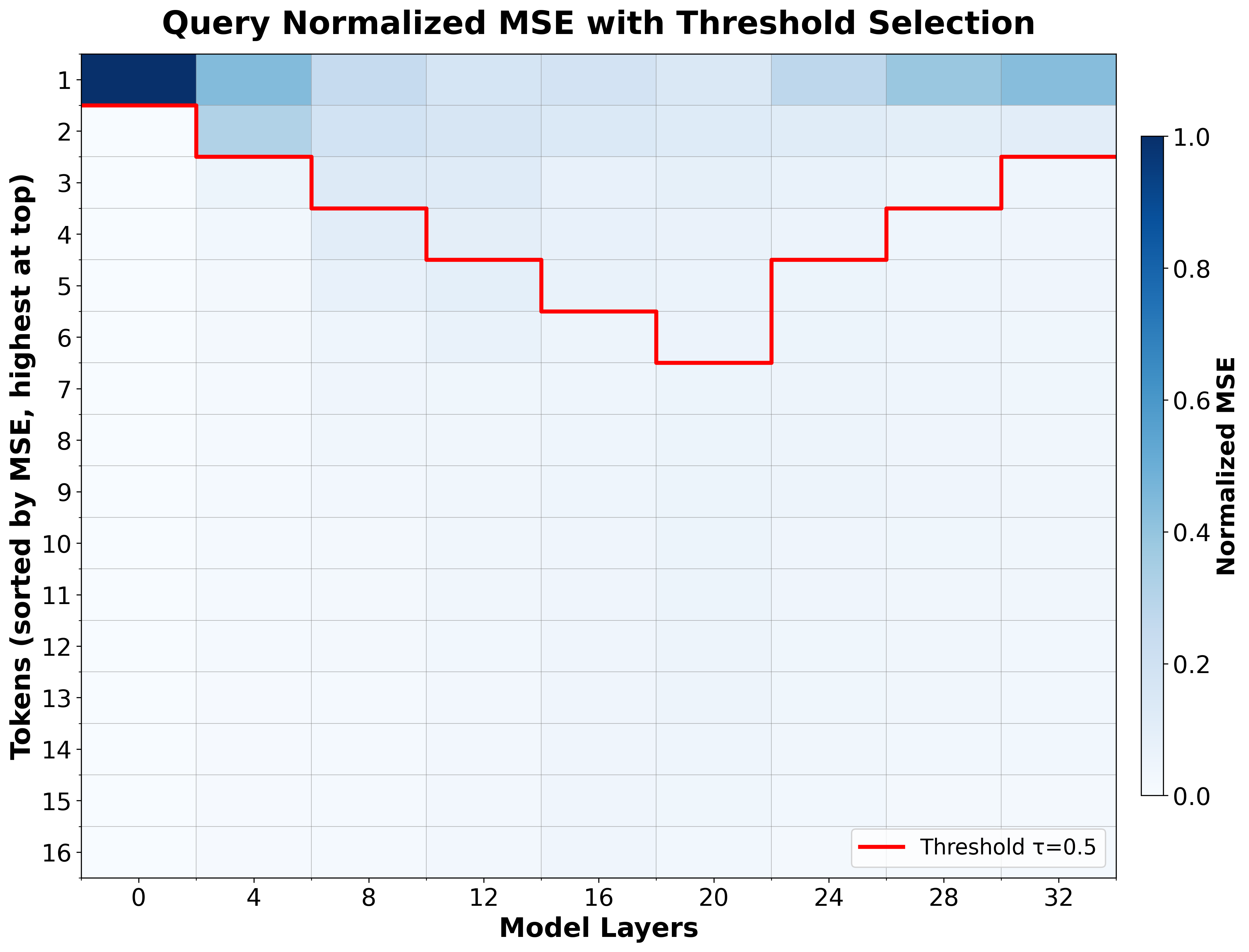
Figure 2: Layerwise heatmap of per-token MSE changes in query representations; only a small fraction of tokens account for most representation change, highlighting strong locality.
Methodology
Locality Pruning and KV Union Reduction
LoSA operationalizes the above insights via the following pipeline:
- At each denoising step, for each token in the block, compute the MSE change in query, key, and value representations relative to the previous step.
- Rank tokens and select the "active" set (those above a chosen threshold).
- For active tokens, apply a sparse attention selector (e.g., QUEST) to identify the relevant prefix KV indices. For stable tokens, reuse cached prefix attention outputs from the previous step, bypassing both sparse selector computation and KV fetch.
- Compute the union of all selected KV positions across active tokens only (not all tokens), which, due to typically high overlap, is much smaller than naive per-query union.
- Run dense (bidirectional) block attention and merge prefix and block outputs using online softmax.
This reduces the participating queries in sparse attention from B to ∣A∣, leading to a smaller KV index union and thus a tangible reduction in memory traffic and latency.
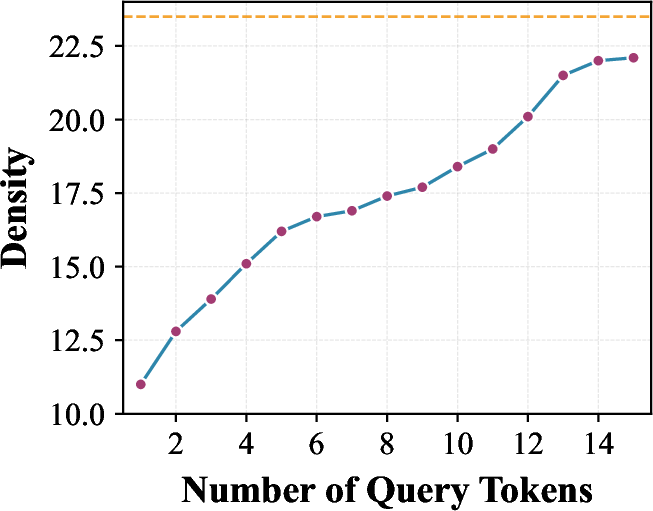
Figure 3: As active query count decreases, KV cache load drops sharply with LoSA, demonstrating practical benefit over naive per-block sparse attention.
The initial denoising step for a block defaults to dense attention for accurate cache initialization, while subsequent steps capitalize on locality-aware reuse.
Implementation and Complexity
LoSA introduces marginal FLOPs and memory overhead for locality pruning (per-token MSE computation and ranking) and for storing cached attention outputs. This overhead is negligible (O(B×d) per head) compared to savings from reduced KV cache traffic. Reuse via cache requires storing B(d+1) additional scalars per head.
Experimental Results
Accuracy and Latency on Long-Context Benchmarks
LoSA is evaluated on several block-diffusion LMs (Trado-8B-Instruct, Trado-4B-Instruct, SDAR-8B-Chat) across LongBench datasets and commonsense reasoning tasks. Compared to adapted QUEST and other DLM-specific efficient attention baselines (e.g., SparseD, Sparse-dLLM), LoSA exhibits large accuracy gains at aggressive sparsity (up to +9% over QUEST at budget 128, and +9.01% over SparseD in average accuracy), while maintaining much lower KV-access density (1.54× lower than QUEST). These accuracy improvements demonstrate that attention output reuse for stable tokens prevents the degradation seen in direct sparse selection.
Latency breakdown on RTX A6000 and 5090 GPUs shows LoSA achieves up to 4.14× wall-clock prefix attention speedup over dense attention (vs 3.26× for QUEST), with the trend holding across hardware generations. Speedup is attributable to the dramatic reduction in KV fetches, not a gain in arithmetic intensity or compute parallelism.

Figure 4: Latency profile—LoSA achieves greater total attention speedup compared to QUEST by reducing the number of active (non-reused) queries.
Qualitative Visualization of Token Selection
Heatmaps of QKV representation changes with threshold-based token selection illustrate the dynamic sparsity mechanism and the concentration of adaptation at a minority of tokens. These visualizations corroborate LoSA's efficacy in focusing computational resources where model states actually change.
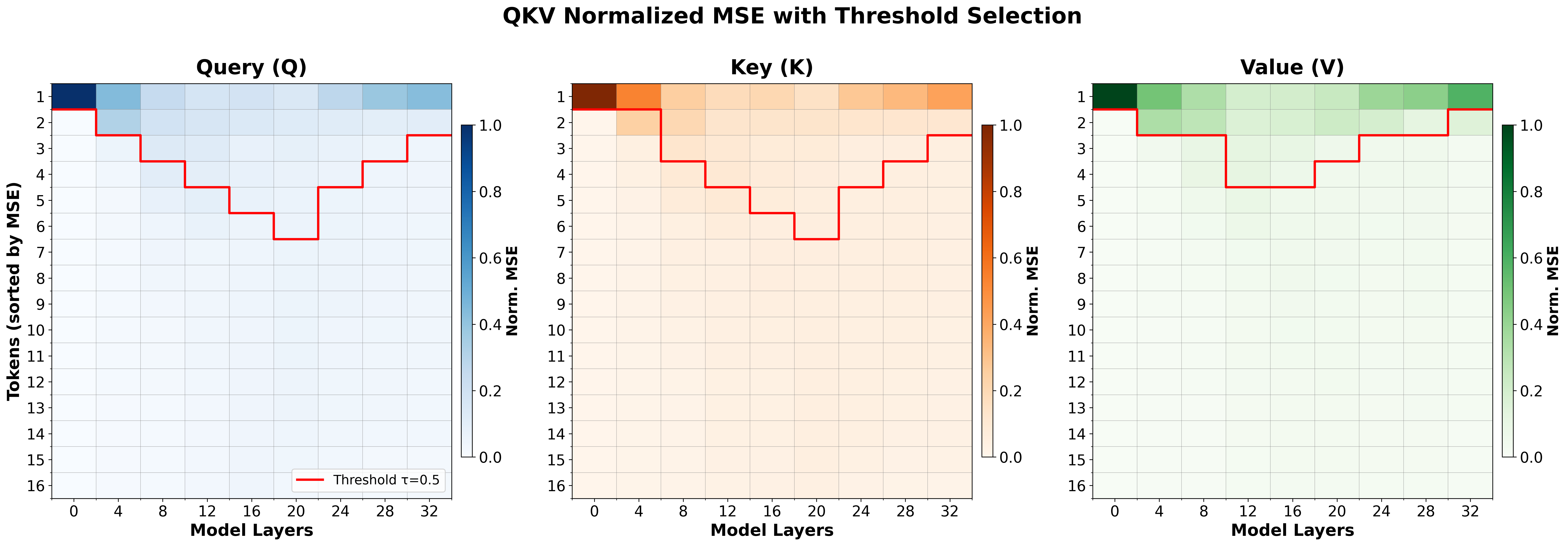
Figure 5: Example heatmap: tokens with top 50% normalized MSE changes are selected for fresh attention; others are dimmed and use cached outputs.
Implications and Future Directions
LoSA demonstrates that classic sparse attention approaches are fundamentally suboptimal for DLMs due to the blockwise union penalty. By exploiting the fine-grained local stability of representations produced by the iterative denoising mechanism, LoSA converts attention sparsity into actual inference efficiency while preserving or improving accuracy at low cost. This method is generally applicable to block-wise and diffusion-based generative architectures, and its reliance on token-level locality suggests potential for adaptive compute in other sequence modeling settings.
Practically, LoSA enables fast and memory-efficient long-context DLM inference without model retraining or major kernel re-engineering. Its design is compatible with next-generation serving backends and can be integrated with further quantization or KV compression strategies.
From a theoretical perspective, LoSA highlights the importance of modeling and leveraging intra-block representation dynamics in blockwise generation. Further research may explore batch-level aggregation, adaptation to other modalities (e.g., code, audio), and automated locality thresholds.
Conclusion
The paper convincingly establishes the limitations of naive sparse attention for blockwise diffusion LMs, chiefly due to the KV Inflation phenomenon, and introduces a principled, locality-aware strategy that materially improves both efficiency and accuracy. By focusing computation on genuinely changing tokens and reusing results for stable positions, LoSA sets a new standard for practical, long-context DLM inference, with reported up to 4.14× attention speedup and up to +9% accuracy improvement at aggressive sparsity. This work has wide implications for deploying diffusion models under memory and latency constraints and opens new avenues for adaptive computation in large-scale generative architectures (2604.12056).

