- The paper introduces a sparse parameterization method that reduces redundant token computation in MDMs, yielding up to 2.84× acceleration in tasks like text-to-image synthesis.
- It employs dedicated register tokens and a novel step-causal attention mask to maintain bidirectional context and compositional generation during sparse inference.
- Empirical evaluations across text-to-image, image editing, and visual reasoning tasks demonstrate efficiency improvements without sacrificing performance metrics.
Sparse-LaViDa: Efficient Sparse Parameterization for Multimodal Discrete Diffusion LLMs
Overview
The "Sparse-LaViDa" framework (2512.14008) addresses a central bottleneck in Masked Discrete Diffusion Models (MDMs): the computational inefficiency incurred by processing large numbers of redundant masked tokens during both training and inference. By introducing a sparse parameterization—paired with a novel regime for attention masking and the usage of register tokens—Sparse-LaViDa reduces computational cost while strictly preserving the multimodal generative modeling flexibility and quality of standard MDMs. The result is a 1.95–2.84× acceleration in major tasks such as text-to-image synthesis, visual reasoning, and image editing, all without sacrificing performance metrics.
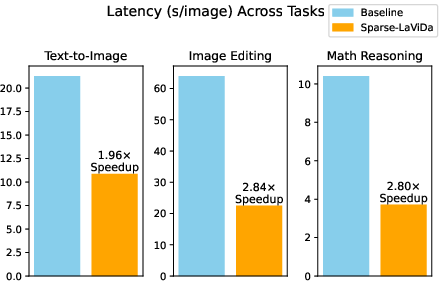
Figure 1: The Sparse-LaViDa approach provides substantial speedups over the baseline LaViDa-O on text-to-image generation, image editing, and visual math reasoning.
Motivation and Prior Work
MDMs have recently achieved state-of-the-art results in unified vision-language understanding and generation by treating both images and texts as discrete token sequences and modeling the masked-to-unmasked sequence transition as a discrete diffusion process. Unlike autoregressive (AR) approaches, MDMs support parallel decoding and bidirectional context, enabling controlled generation and efficient infilling. However, MDMs still materialize all tokens (masked and unmasked) at each step, leading to repeated and unnecessary computation, especially as sequence lengths scale with image resolution.
Existing approaches to improve efficiency—such as block-causal attention in Block Diffusion—truncate tokens but restrict decoding order (usually left-to-right) and destroy bidirectional context, disproportionately harming image generation/editing quality. Heuristic or training-free KV-caching methods lack reliability or generalization. Sparse-LaViDa proposes an alternative, fundamentally compatible with arbitrary decoding order, full bidirectionality, and cross-modal compositionality.
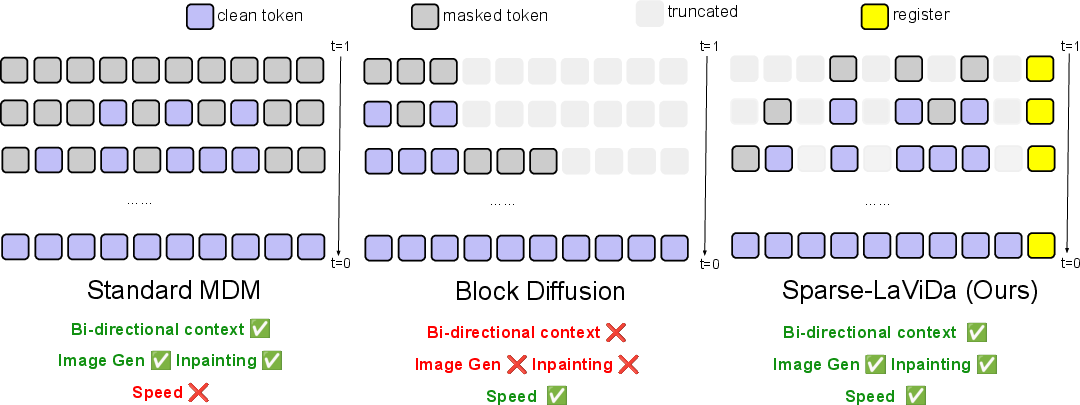
Figure 2: Sparse-LaViDa (right) preserves bidirectional context and arbitrary-order truncation unlike block-causal (middle) or vanilla MDMs (left), with special register tokens enabling efficient compression.
Sparse Parameterization and Model Design
Sparse Representation
The key insight is that, under the conditional independence assumption in MDMs, predictions are only required for a sparse subset C of positions at any diffusion step. Rather than forwarding all positions—including redundant masked tokens—the model forwards only prompts, previously decoded tokens, the current to-be-decoded masked tokens, and a constant-size set of register tokens as compressed surrogates for truncated masked regions. This leads to drastic sequence length compression.
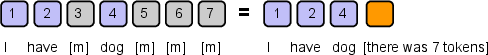
Figure 3: Sparse representation uniquely encodes a partially masked sequence by non-masked tokens, their locations, and a count of total tokens.
Register Tokens
Elimination of masked tokens reduces representational capacity, particularly for large context images. To mitigate this, Sparse-LaViDa introduces a pool of dedicated register tokens, with distinct positional embeddings, that act as proxies for the truncated masked regions. The optimal count (empirically 64) is modest relative to total sequence length (e.g., 3–6% for typical image generation), and they are sufficient for maintaining attention flows and local/global context integrity.
Sparse Sampling and KV-Cache Compatibility
Sparse-LaViDa supports general decoding orders: precomputed 2D stratified random samplers for image tasks and dynamic confidence-based blockwise sampling for language, without imposing left-to-right restrictions. At each diffusion step, only relevant tokens for generation, prompt, and registers participate in the attention computation, and previously decoded tokens are cached. The attention mask is designed so that cached tokens contribute context, whereas newly decoded tokens cannot attend to upcoming or register tokens in the same step.
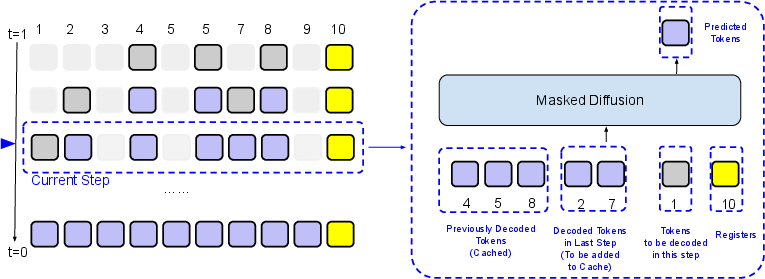
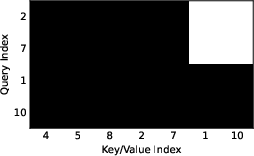
Figure 4: Inference pipeline—at each sampling step, distributed token types are handled distinctively by the attention mask to ensure proper cache updates and isolation of prediction targets.
Step-Causal Training: Matching Training to Sparse Inference
To avoid a training-inference mismatch, Sparse-LaViDa introduces a step-causal attention mask. During training, blocks (prompt, clean tokens, masked tokens, registers) are allocated in correspondence to their role/timestep in the sparse inference process. Clean tokens attend only up to their block, masked tokens/registrations attend within their block and to all prompt/clean blocks, ensuring that the range of dependency and cache dynamics mirrors the inference setup.

Figure 5: The step-causal attention mask enforces access patterns during training to induce correct KV-cache and masking behavior at inference.
Empirical Evaluation
The Sparse-LaViDa model is initialized from LaViDa-O and fine-tuned with the proposed sparse pipeline on high-quality mixtures of image-text pairs, editing, and understanding data. Evaluation across primary multimodal tasks demonstrates pronounced efficiency improvements without performance regression.
- Text-to-Image Generation: On GenEval, DPG, and MJHQ-30k, accuracy matches or slightly exceeds LaViDa-O, with a 1.95× speedup in end-to-end latency.
- Image Editing: Sparse-LaViDa surpasses LaViDa-O by +0.08 in aggregate GPT-4 judged ImgEdit scores and accomplishes a 2.83× acceleration.
- Visual Math Reasoning: On MathVista, Sparse-LaViDa attains equivalent accuracy (56.7% vs 56.9%) yet reduces latency by 2.8× compared to standard masking.
- Image Understanding and QA: Marginal speedups are observed on short-output QA tasks due to block-size constraints, but performance is competitive.
- Bidirectionality and Inpainting: Unlike Block Diffusion and similar semi-AR modifications, Sparse-LaViDa maintains the capability for inpainting/outpainting and k-shot compositional grounding.

Figure 6: Qualitative results show that bidirectional context is preserved for infilling, inpainting, grounding, and constrained captioning tasks.

Figure 7: Side-by-side comparisons with LaViDa-O show indistinguishable generation quality for both text-to-image and image editing with dramatically reduced inference time.
Ablations and Model Analysis
- Token Caching and Truncation: Caching prompt/decoded tokens and aggressive truncation of masked tokens each independently confer speedups; their combination yields maximum gains.
- Register Token Count: Fewer than 32 yields utility drops in fine-grained perceptual scores, confirming their necessary role.
- Step-Causal Mask: Omission leads to both quality and generalization reductions, emphasizing the necessity of training-inference behavioral alignment.
- No Fine-Tuning: Applying sparse masking to non-finetuned weights causes severe degeneration, underscoring that parameterization change is not training-free.
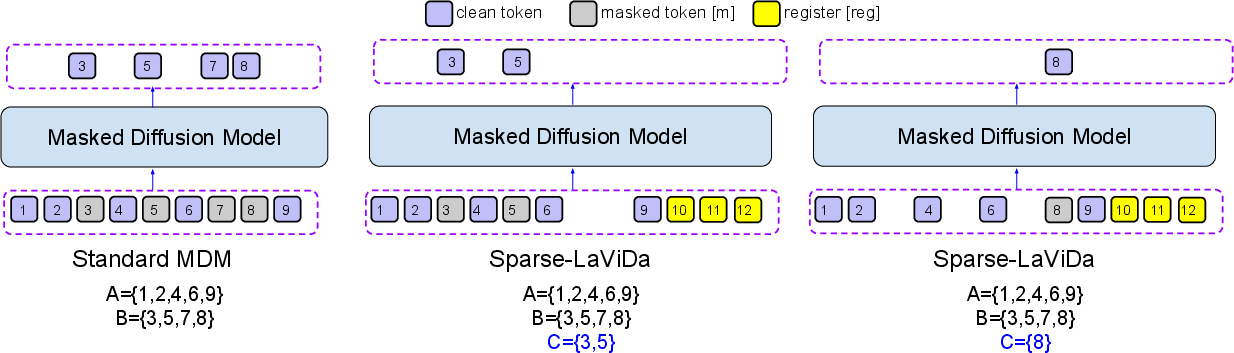
Figure 8: Sparse-LaViDa drastically reduces the number of token positions needed at each diffusion step compared to standard MDMs by leveraging clean tokens, a subset of masked positions, and a small set of registers.
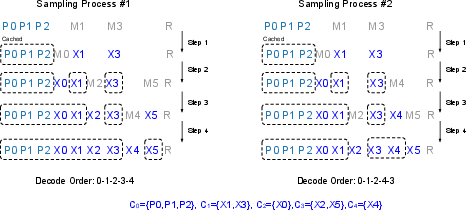
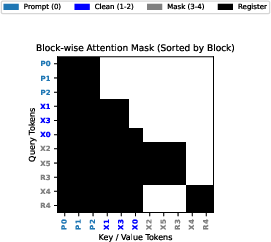
Figure 9: The step-causal attention mask enables the simultaneous training of different sampling processes by judiciously partitioning attention across blocks and registers.
Implications and Future Directions
Sparse-LaViDa sets a precedent for architectural and algorithmic advances in the acceleration of unified multimodal diffusion models. The explicit dissociation from block-ordered inference allows full expressiveness in bidirectional and compositional generation scenarios, a property not shared by block or AR surrogates. Practically, this efficiency translates to lower hardware requirements, cost savings, and broader applicability for production-scale multimodal systems.
Theoretically, the preservation of equivalence with the standard dense MDM objective provides a route to integrate sparse parameterization at the pretraining stage, potentially yielding even greater efficiency gains as model and dataset scales rise. Open questions include generalization to other forms of diffusion processes, further optimized register design, and adaptive sparse representations learned end-to-end.
Conclusion
Sparse-LaViDa demonstrates that equivalently powerful MDMs can be realized with order-of-magnitude reductions in computational requirements by leveraging a sparse input parameterization, judicious use of register tokens, and precisely matched attention masking. These innovations yield substantial acceleration on high-value generative tasks, broadening the versatility and deployability of unified multimodal diffusion modeling paradigms.