Dynamic Low-Rank Sparse Adaptation for Large Language Models
Abstract: Despite the efficacy of network sparsity in alleviating the deployment strain of LLMs, it endures significant performance degradation. Applying Low-Rank Adaptation (LoRA) to fine-tune the sparse LLMs offers an intuitive approach to counter this predicament, while it holds shortcomings include: 1) The inability to integrate LoRA weights into sparse LLMs post-training, and 2) Insufficient performance recovery at high sparsity ratios. In this paper, we introduce dynamic Low-rank Sparse Adaptation (LoSA), a novel method that seamlessly integrates low-rank adaptation into LLM sparsity within a unified framework, thereby enhancing the performance of sparse LLMs without increasing the inference latency. In particular, LoSA dynamically sparsifies the LoRA outcomes based on the corresponding sparse weights during fine-tuning, thus guaranteeing that the LoRA module can be integrated into the sparse LLMs post-training. Besides, LoSA leverages Representation Mutual Information (RMI) as an indicator to determine the importance of layers, thereby efficiently determining the layer-wise sparsity rates during fine-tuning. Predicated on this, LoSA adjusts the rank of the LoRA module based on the variability in layer-wise reconstruction errors, allocating an appropriate fine-tuning for each layer to reduce the output discrepancies between dense and sparse LLMs. Extensive experiments tell that LoSA can efficiently boost the efficacy of sparse LLMs within a few hours, without introducing any additional inferential burden. For example, LoSA reduced the perplexity of sparse LLaMA-2-7B by 68.73 and increased zero-shot accuracy by 16.32$\%$, achieving a 2.60$\times$ speedup on CPU and 2.23$\times$ speedup on GPU, requiring only 45 minutes of fine-tuning on a single NVIDIA A100 80GB GPU. Code is available at https://github.com/wzhuang-xmu/LoSA.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about making big LLMs—like LLaMA—run faster and use less computer power, without hurting their accuracy too much. The authors introduce a new method called LoSA (Dynamic Low-rank Sparse Adaptation) that combines two ideas: pruning (removing unneeded parts) and lightweight fine-tuning (small fixes), so the model stays fast and still performs well.
What questions did the researchers ask?
The team focused on three simple questions:
- How can we prune a LLM heavily (to make it faster) but still keep its accuracy high?
- How can we add small fine-tuning adjustments that can be merged back into the pruned model, so there’s no slowdown during use?
- How can we decide which parts of the model to prune more or fine-tune more, based on how important each part is?
How did they approach the problem?
Think of an LLM like a huge machine with many layers (like steps in a recipe), each full of numbers (weights) that affect how it works. The authors mix three ideas to keep the model fast and smart:
Key ideas explained simply
- Sparsity: This means setting many weights to zero (like turning off switches) to make the model lighter and faster. Imagine decluttering a backpack by removing items you don’t need.
- LoRA (Low-Rank Adaptation): Instead of changing the whole model, LoRA adds two small helper parts to each layer—like tiny adjustable knobs—to correct the model’s behavior with much fewer extra parameters.
- Layer importance: Not all layers are equally important. Some layers do more “thinking” than others. The team uses a quick score to measure how similar each layer’s internal features are to other layers (Representation Mutual Information, estimated using a method called normalized HSIC). If a layer looks too similar to many others, it’s less special and can be pruned more.
The LoSA steps
To make this work smoothly and efficiently, LoSA does the following:
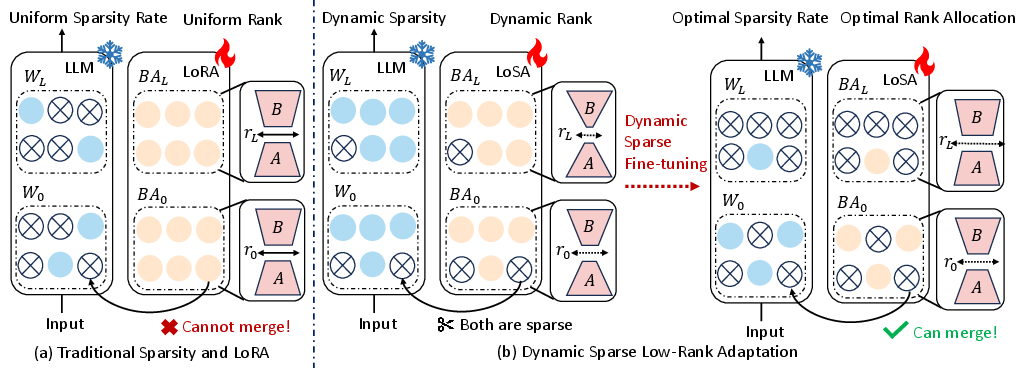
- Make pruning and fine-tuning compatible: When LoRA adds small helper weights, LoSA “sparsifies” them too so they match the pruning pattern. This means those helper weights can be merged back into the pruned model, keeping it fast at inference time.
- Pick smarter pruning per layer: LoSA measures how important each layer is. More important layers keep more weights; less important layers lose more.
- Give more help where it’s needed: LoSA checks how far the pruned layer’s output is from the original layer’s output (this difference is the reconstruction error). Layers that struggle more get a higher “rank” (more helper capacity), while easy layers get less.
- Do it dynamically: LoSA increases sparsity step by step (using a schedule) and adjusts helper ranks along the way. This is like tightening screws gradually while re-checking which ones need extra support.
You can think of the whole process as carefully trimming a tree while adding small braces where branches need reinforcement, and doing it in rounds to avoid damaging the tree.
What did they find?
The team tested LoSA on several popular models (LLaMA-1/2/3, LLaMA-3.1, OPT, Vicuna) from 7B to 70B parameters. Highlights:
- For LLaMA-2-7B at 70% sparsity (keeping only 30% of weights), LoSA greatly improved performance compared to standard pruning:
- Perplexity dropped by about 68.73 points (lower is better).
- Zero-shot accuracy (across tasks like HellaSwag, ARC, BoolQ, etc.) increased by about 16.32%.
- Speedups without extra lag:
- On CPU: up to about 2.60× faster.
- On GPU: up to about 2.23× faster.
- Short fine-tuning time:
- About 45 minutes on a single NVIDIA A100 80GB GPU for LLaMA-2-7B.
- Works across different sparsity styles:
- Even with N:M patterns (like “2 out of every 8 weights kept”), LoSA improves both accuracy and perplexity.
- Better than using LoRA alone on sparse models:
- Standard LoRA can’t merge neatly into sparse weights, which adds inference delay. LoSA fixes this by making the LoRA helpers sparse too, so they merge cleanly.
Why this is important: Heavy pruning usually makes models much worse. LoSA shows you can prune a lot and still keep strong accuracy, and you don’t pay a penalty in speed when you deploy the model.
Why does it matter?
- Practical deployment: Big LLMs are costly to run. LoSA helps them run faster and cheaper, making them more accessible.
- No extra inference delay: Because the fine-tuning helpers are merged into the pruned model, using the model stays fast.
- Smarter resource use: LoSA automatically decides where to prune more and where to fine-tune more, saving time and compute and improving results.
- Broad usefulness: It works across different models and pruning methods (like SparseGPT and Wanda), and across different sparsity levels.
Takeaway and impact
LoSA is a careful, smart way to slim down huge LLMs while keeping them sharp. By:
- dynamically choosing how much to prune per layer,
- allocating more helper capacity to layers that need it,
- and ensuring fine-tuning additions can be merged back,
LoSA makes large models faster and cheaper to run, with surprisingly little loss in quality—and often, clear gains after fine-tuning. This can help more people and organizations deploy capable AI models on smaller hardware, making advanced language technology more widely available.
Collections
Sign up for free to add this paper to one or more collections.