- The paper introduces LessIsMore, a training-free sparse attention mechanism that unifies token selection across heads using global spatial and recency locality.
- The methodology aggregates top-k tokens globally and reserves a stable recency window, effectively reducing compounded selection errors during long-sequence reasoning.
- Empirical results demonstrate lossless accuracy and improved decoding speed, outperforming existing sparse attention baselines on multiple reasoning benchmarks.
LessIsMore: Training-Free Sparse Attention with Global Locality for Efficient Reasoning
Introduction
The paper introduces LessIsMore, a training-free sparse attention mechanism tailored for efficient and accurate reasoning in LLMs. The motivation arises from the computational inefficiency of full attention during long-sequence generation in reasoning tasks, where the input is short but the output derivation is extensive. Existing sparse attention methods either require high token retention rates or retraining, and suffer from accuracy degradation due to accumulated selection errors over long generations. LessIsMore leverages intrinsic global locality patterns in attention—both spatial (across attention heads) and temporal (recency)—to enable unified token selection, thereby improving both efficiency and accuracy without retraining.
Limitations of Existing Sparse Attention in Reasoning
Sparse attention mechanisms reduce computational cost by attending to a subset of tokens. However, in reasoning tasks, selection errors accumulate over thousands of decoding steps, leading to degraded attention recall and cascading accuracy loss. Empirical analysis demonstrates that selection-based methods (e.g., TidalDecode) and eviction-based methods (e.g., StreamingLLM) exhibit substantial recall degradation on reasoning benchmarks such as AIME-24, with selection-based approaches reaching only 75% recall and eviction-based approaches falling below 65% under a 4K token budget.
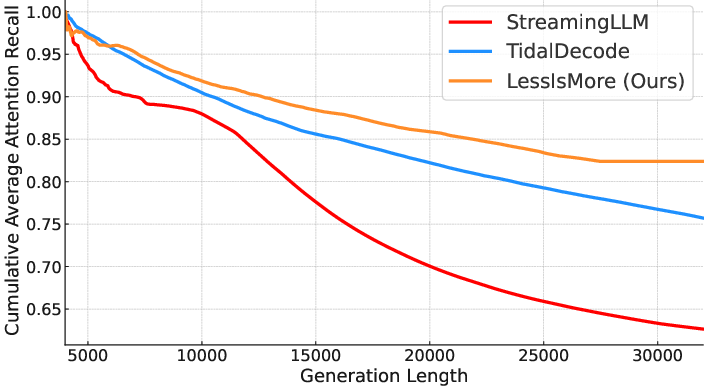
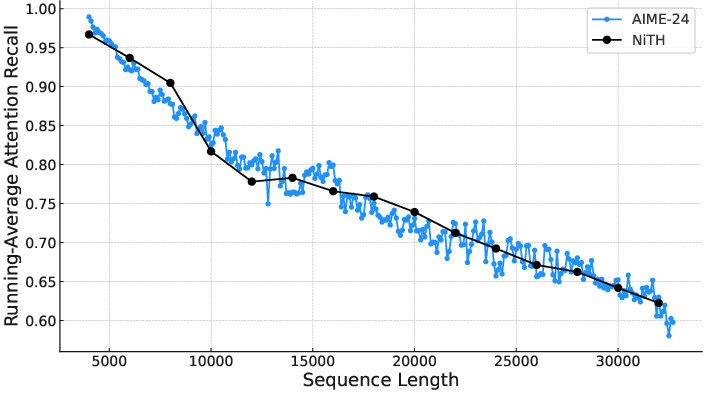
Figure 1: Attention recall of different approaches using 4K token budget on an AIME problem.
This degradation is exacerbated by the length of the generation sequence, as errors compound over time, highlighting the need for a selection strategy that captures globally critical tokens rather than relying on local, head-specific optimizations.
Attention Locality Observations
Spatial Locality
Contrary to the conventional assumption that attention heads require distinct token subsets due to specialized roles, the analysis reveals substantial overlap in token-importance rankings across heads within the same decoding layer, especially in Grouped Query Attention (GQA) frameworks. This suggests that per-head top-k selection is suboptimal and that a unified global selection can better capture critical tokens.

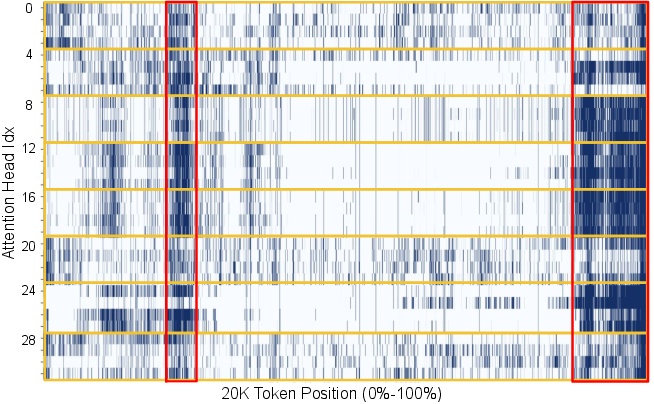
Figure 2: The distribution of the ground-truth top-4K tokens across all attention heads at 20K-th decoding step at Layer 4 on AIME-24 with Qwen3-8B. Highly overlapped areas within kv groups and across heads are highlighted.
Recency Locality
Tokens that receive high attention in one decoding step tend to continue attracting substantial attention in subsequent steps. The size of the "recency window"—the set of most recent tokens receiving high attention—remains stable throughout decoding, reflecting the iterative nature of reasoning.

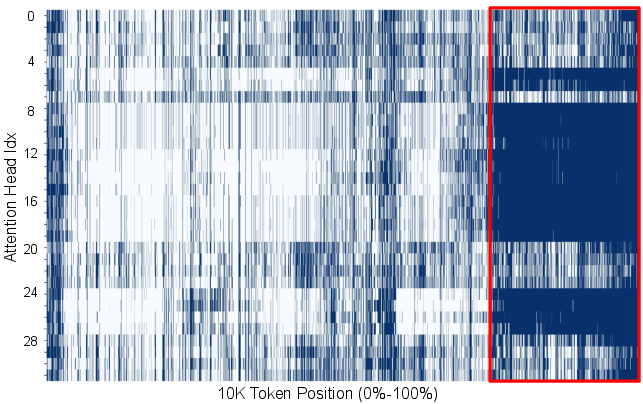
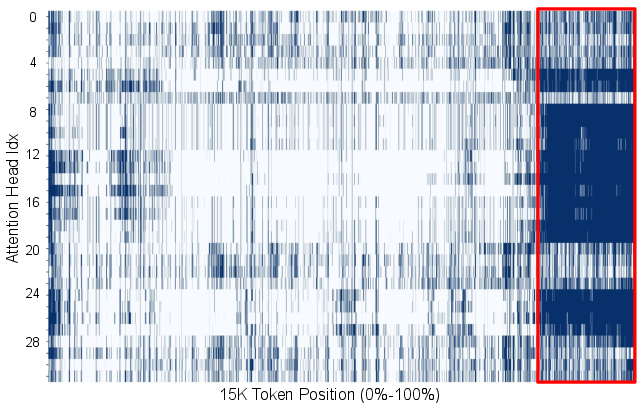
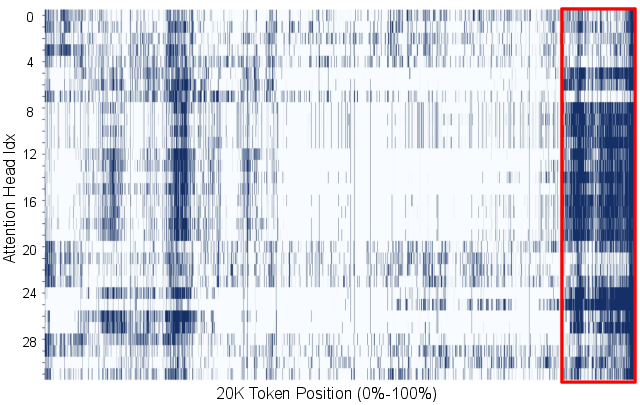
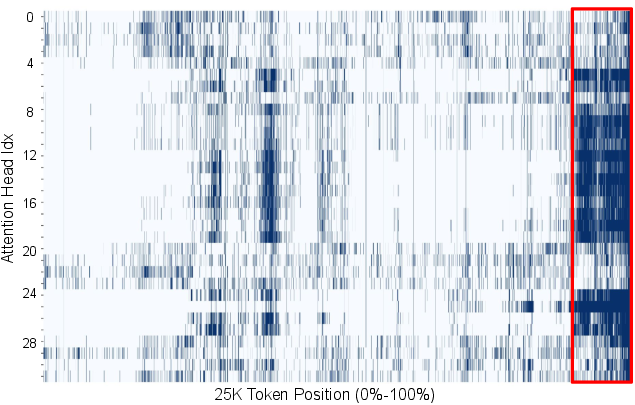
Figure 3: 10K-th decoding step.
LessIsMore: Methodology
LessIsMore integrates two key techniques:
- Unified Attention Head Selection: Each attention head selects its top-k tokens, which are then aggregated and globally ranked. The highest-ranked tokens are retained, ensuring all heads attend to the same critical subset.
- Stable Recency Window: A fixed proportion of the token budget is reserved for the most recent tokens, maintaining reasoning coherence.
The selection process is formalized as follows:
- For each selection layer, compute attention scores for all heads.
- Exclude the most recent tokens from the initial selection.
- Aggregate and globally sort the top-k tokens from all heads.
- Concatenate the globally top-ranked tokens with the most recent tokens to form the final set for sparse attention.
This approach is implemented as a plug-and-play module and does not require retraining.
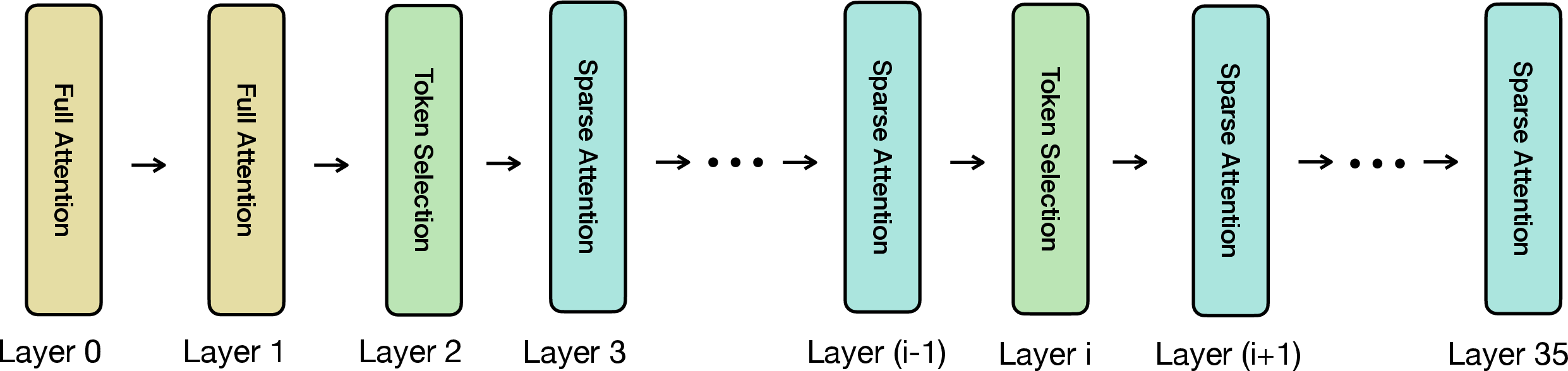
Figure 4: Walkthrough of a single decoding step of the selection-based approach TidalDecode, illustrating the integration of LessIsMore's selection strategy.
Experimental Results
Accuracy
LessIsMore consistently matches or exceeds the accuracy of full attention across diverse reasoning tasks (AIME-24/25, GPQA-Diamond, MATH500) and models (Qwen3-8B, Qwen3-4B), even under stringent token budgets (1K–2K). Competing sparse attention baselines (Quest, TidalDecode, SeerAttention-r) suffer notable accuracy drops at low budgets, while LessIsMore maintains lossless performance.
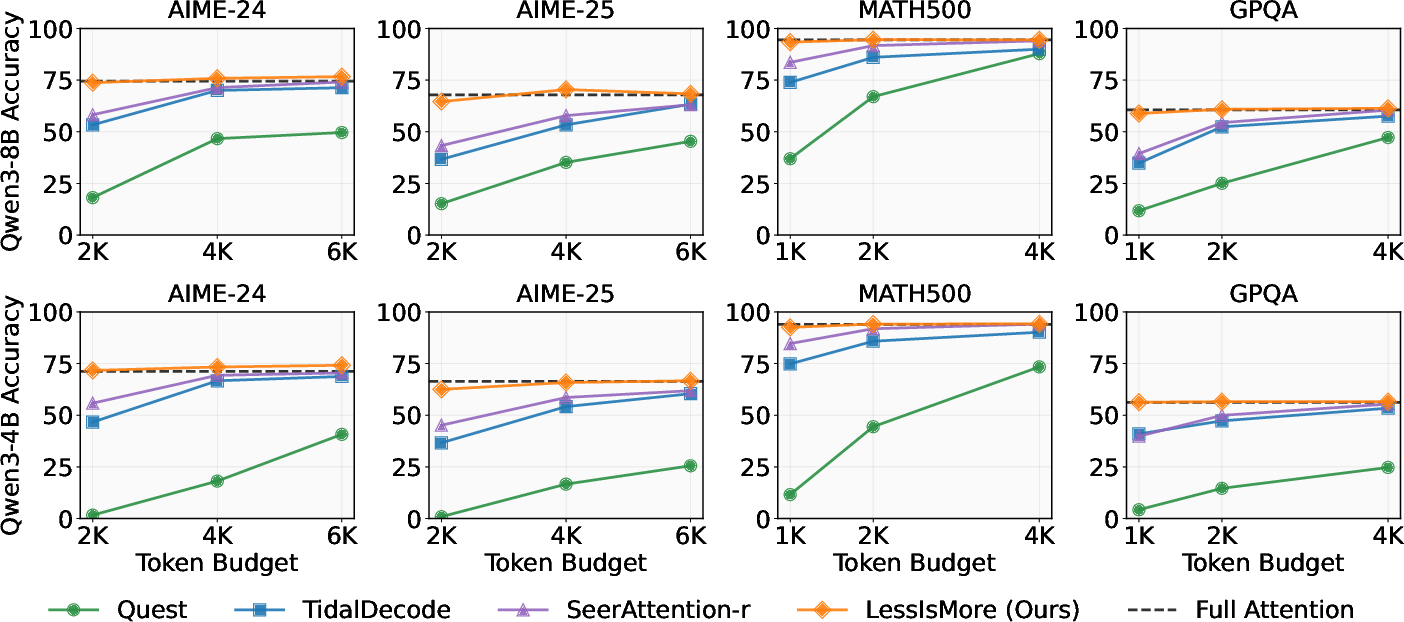
Figure 5: Accuracy results of LessIsMore, Quest, TidalDecode, SeerAttention-r, and Full Attention across multiple reasoning tasks. LessIsMore achieves lossless accuracy with small token budgets, outperforming all baselines.
Efficiency
LessIsMore achieves a 1.1× average decoding speed-up over full attention and a 1.13× end-to-end speed-up over state-of-the-art sparse attention methods, attending to 2× fewer tokens without increasing generation length.
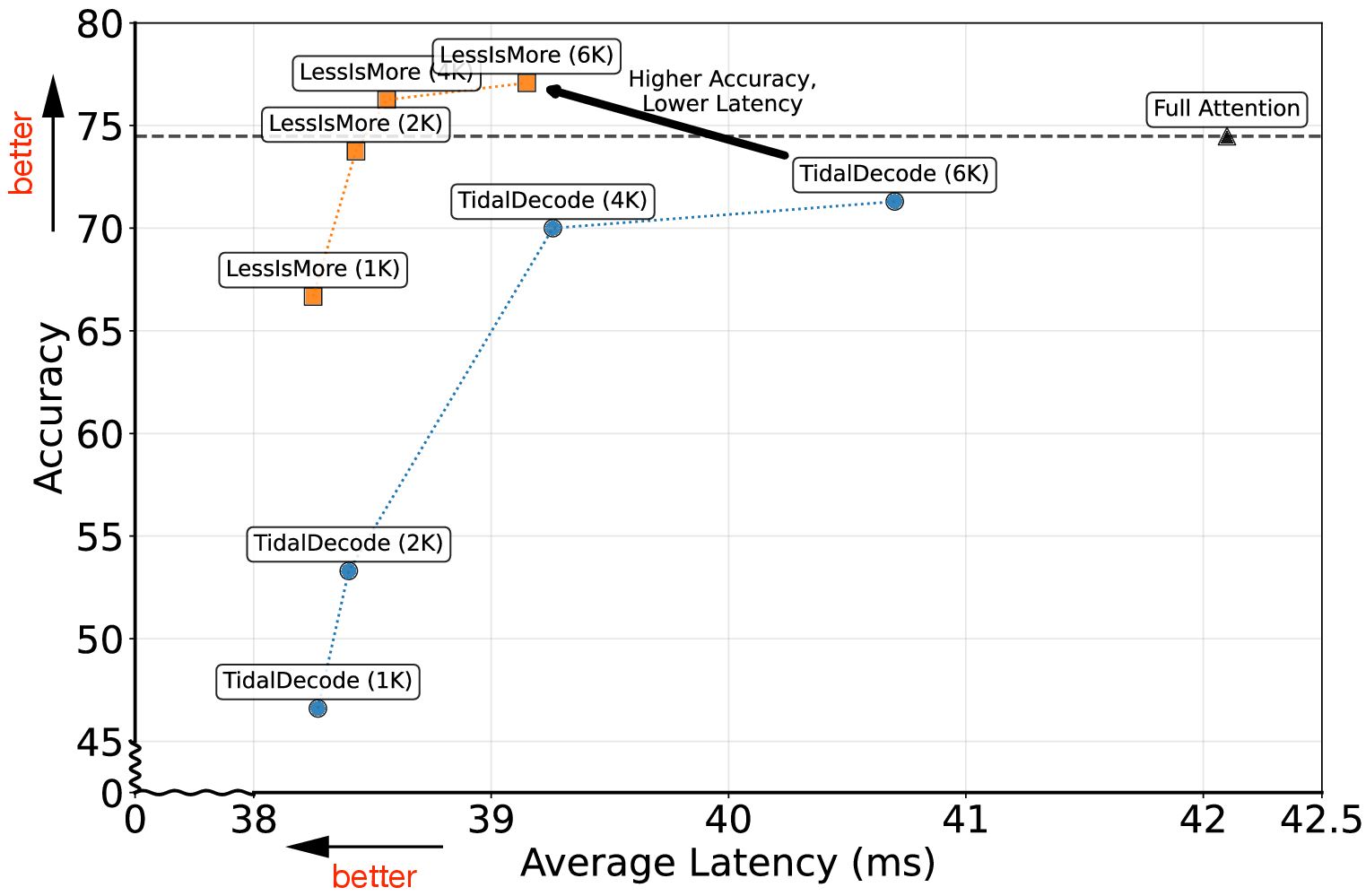
Figure 6: Efficiency-accuracy tradeoff comparison on AIME-24 using LLama-3.1-8B. LessIsMore achieves higher accuracy and lower latency than TidalDecode across all token budgets.
Ablation and Generalization
Unified global selection outperforms local head-specific selection, especially when selection frequency is reduced. LessIsMore maintains generation lengths comparable to full attention, whereas other sparse methods extend reasoning sequences due to accumulated selection errors. The optimal recency window ratio is empirically found to be 25%, balancing attention recall and answer correctness.

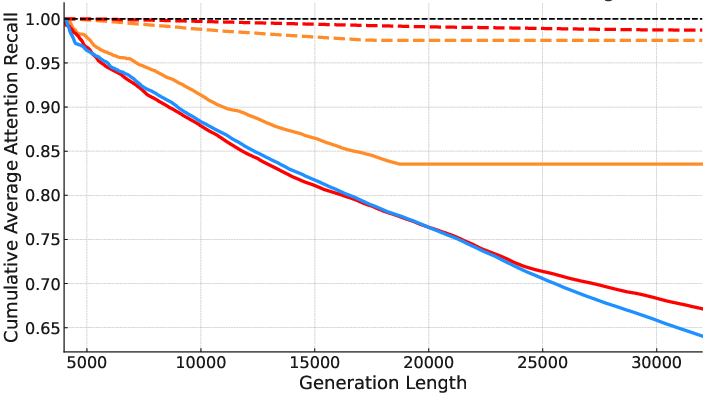
Figure 7: The Top-4K attention recall of different selection schemes applied only on Layer 2 or all decoding layers. LessIsMore's unified selection yields superior recall.
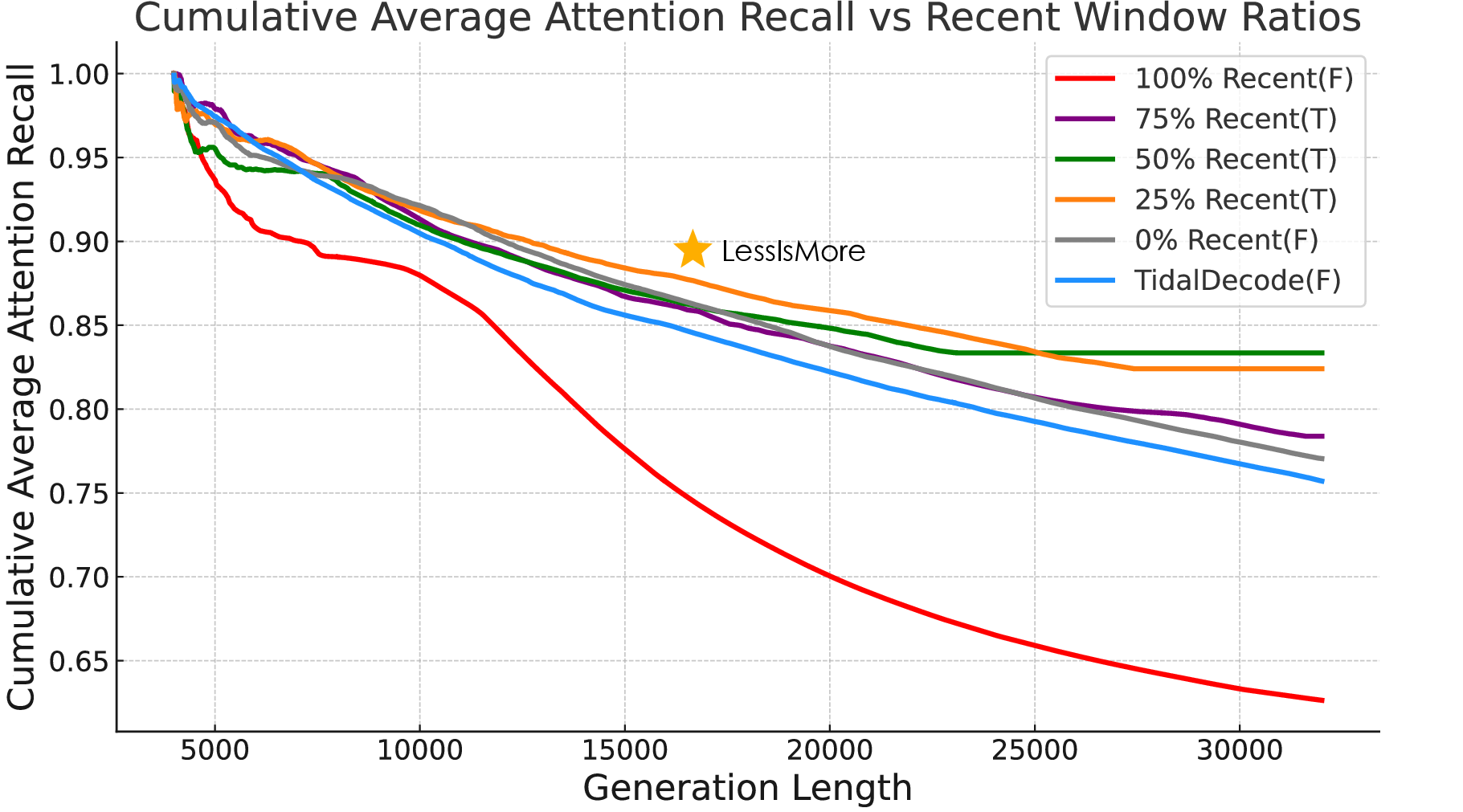
Figure 8: Ablation paper on the impact of varying the recent window ratio in LessIsMore on the AIME-24 reasoning task. Only configurations with a recency window and unified selection succeed in solving the task.
Implications and Future Directions
LessIsMore demonstrates that global locality patterns in attention can be exploited for efficient, training-free sparse attention in reasoning tasks. The approach challenges the paradigm of head-wise local optimization and provides a principled method for token selection that generalizes across models and tasks. Future work should focus on adaptive determination of token budgets and recency ratios, extending the methodology to architectures beyond GQA, and integrating memory-saving strategies to further reduce resource requirements. Incorporating LessIsMore principles into pretraining and exploring intra-layer hybrid attention mechanisms are promising avenues for further research.
Conclusion
LessIsMore provides a robust, training-free sparse attention mechanism that leverages global spatial and recency locality patterns to achieve high accuracy and efficiency in reasoning-intensive LLMs. It consistently outperforms existing sparse attention baselines, maintaining lossless accuracy with minimal token budgets and reduced computational overhead. The results underscore the importance of global token selection strategies and open new directions for efficient long-sequence reasoning in large-scale models.