- The paper introduces AdaSpa, a training-free adaptive sparse attention method that speeds up long video generation in Diffusion Transformers.
- It leverages hierarchical block sparsity and cached LSE invariance to perform precise online search for optimal attention masks.
- Experimental results show up to 1.78× speedup with minimal quality loss, making AdaSpa a practical plug-and-play module for DiTs.
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
Introduction
The paper introduces AdaSpa, a training-free and adaptive sparse attention mechanism designed to accelerate long video generation in Diffusion Transformers (DiTs) without compromising output quality. The motivation stems from the prohibitive computational cost of full attention in DiTs, especially for high-resolution, long-duration videos, where attention operations dominate the total FLOPs (Figure 1).
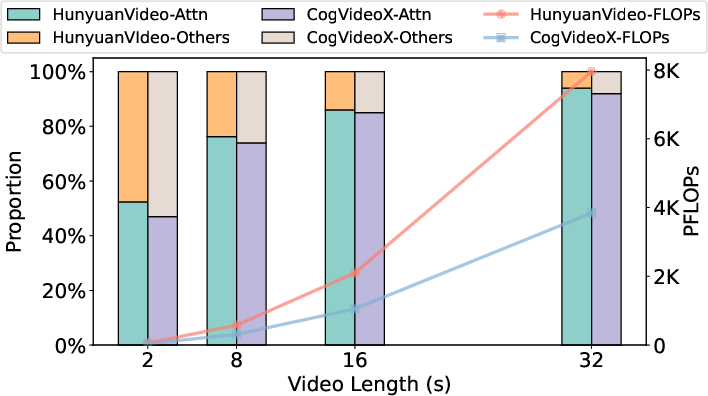
Figure 1: The total FLOPs required and the proportion of attention when generating 720p videos with different video lengths (16FPS).
AdaSpa leverages the hierarchical and blockified sparsity patterns inherent in DiTs and exploits the invariance of sparse patterns and Log-Sum-Exp (LSE) statistics across denoising steps. The method combines dynamic pattern recognition with online precise search, enabling real-time identification of optimal sparse indices with minimal overhead. AdaSpa is implemented as a plug-and-play module, requiring no model retraining or dataset profiling.
Sparse Attention Patterns in DiTs
Sparse attention mechanisms reduce computational complexity by masking low-importance token interactions. Existing approaches fall into static and dynamic pattern categories (Figure 2):
- Static Patterns: Predefined masks (e.g., sliding window, sink) applied uniformly, lacking adaptability to input or model state.
- Dynamic Patterns: Masks determined via offline or online search, offering flexibility but incurring search overhead and often relying on approximations.
AdaSpa advances beyond these by proving that blockified patterns best capture DiT sparsity and by enabling online, precise search for optimal block indices.
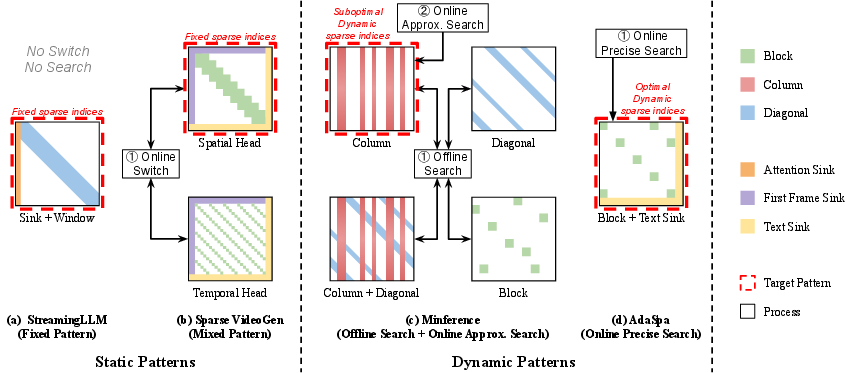
Figure 2: Different types of Sparse Pattern recognition methods, highlighting AdaSpa's dynamic blockified pattern and online precise search.
Empirical analysis reveals that DiT attention matrices exhibit hierarchical structure, with distinct blocks corresponding to video frames and text tokens (Figure 3, Figure 4). Within each block, local patterns (e.g., column, diagonal) may exist, but global continuity is disrupted by modality boundaries and inter-frame sparsity.
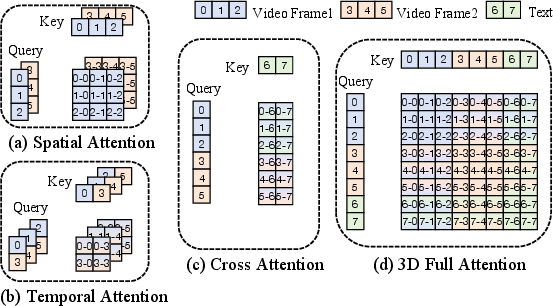
Figure 3: Different Attention Mechanisms in DiTs.
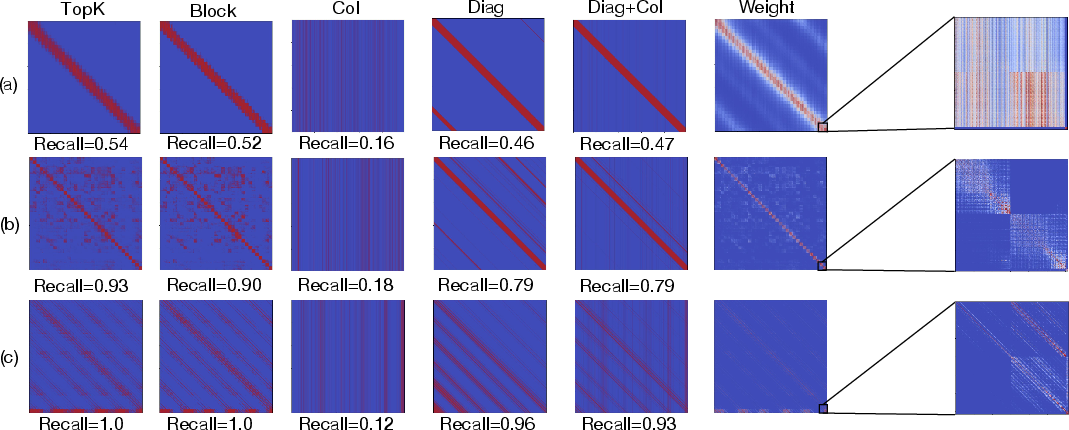
Figure 4: Typical attention weight maps from HunyuanVideo, showing hierarchical and blockified sparsity.
Key observations include:
- Hierarchical Block Structure: Attention weights are organized into frame-wise and modality-wise blocks, making continuous patterns suboptimal.
- Input, Layer, and Head Adaptivity: Sparse patterns vary with input prompt, layer, and attention head, but remain invariant across denoising steps (Figure 5).
- LSE Invariance: The distribution of LSE values is stable across denoising steps, enabling cache reuse for efficient online search.
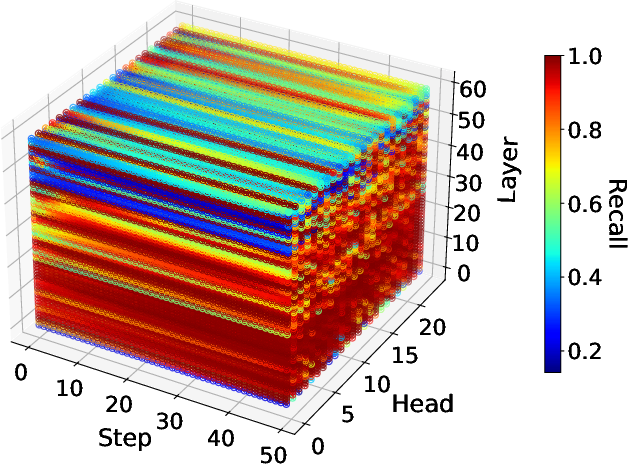
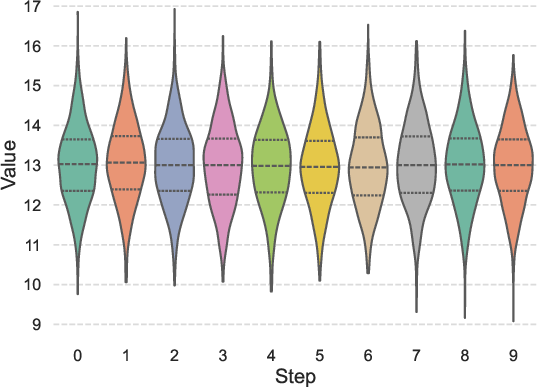
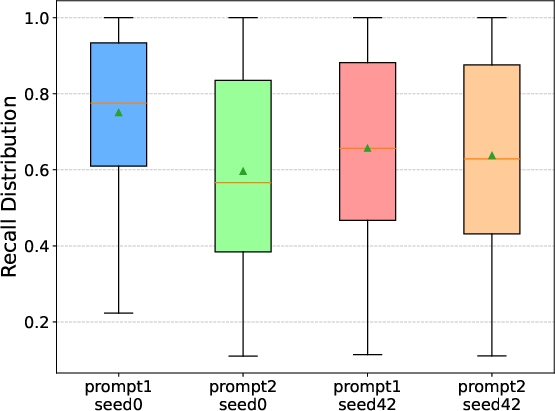
Figure 5: Sparse pattern's Recall changes with head and layer, but invariant step.
AdaSpa: Methodology
AdaSpa is designed to efficiently search and apply blockified sparse attention masks in DiTs. The method consists of two main components:
- Fused LSE-Cached Online Search: During designated warmup steps, full attention is computed and LSE statistics are cached. Subsequent steps use cached LSE to perform block-wise top-k selection of attention weights, identifying optimal blocks for sparse attention with minimal recomputation.
- Head-Adaptive Hierarchical Block Sparse Attention: Sparsity is adapted per attention head based on recall statistics, balancing computational load and accuracy. Heads with high recall are assigned higher sparsity, while those with low recall receive lower sparsity, maintaining overall efficiency and quality.
The AdaSpa pipeline is illustrated in Figure 6.
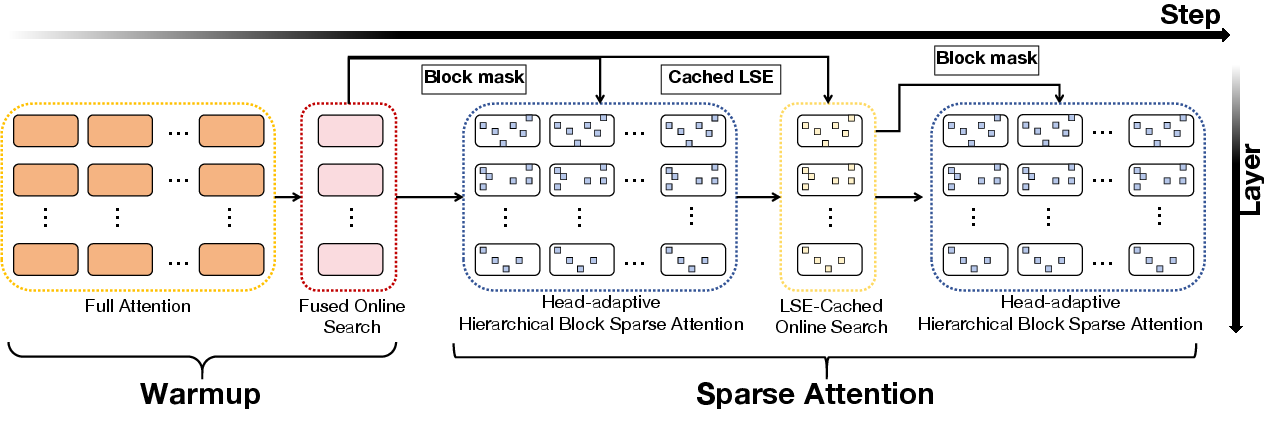
Figure 6: Overview of AdaSpa, showing warmup, online search, and head-adaptive block sparse attention.
Implementation is provided via a minimal handler interface (Figure 7), requiring only a single line change to enable AdaSpa in existing DiT codebases. The method is orthogonal to other acceleration techniques such as quantization and parallelization.

Figure 7: Minimal usage of AdaSpa.
Experimental Results
AdaSpa is evaluated on HunyuanVideo (13B) and CogVideoX1.5-5B, generating 720p videos of 8–10 seconds. Metrics include VBench Score, PSNR, SSIM, LPIPS, latency, and speedup. AdaSpa consistently outperforms static (Sparse VideoGen) and dynamic (MInference) baselines in both quality and efficiency.
- HunyuanVideo: AdaSpa achieves a speedup of 1.78× with negligible quality loss (VBench: 80.13% vs. 80.10% full attention).
- CogVideoX1.5-5B: AdaSpa delivers a speedup of 1.66× and the highest quality metrics.
Ablation studies demonstrate the importance of head-adaptive sparsity and LSE caching. AdaSpa maintains high video quality across increasing sparsity levels, whereas baselines suffer significant degradation (Figure 8).
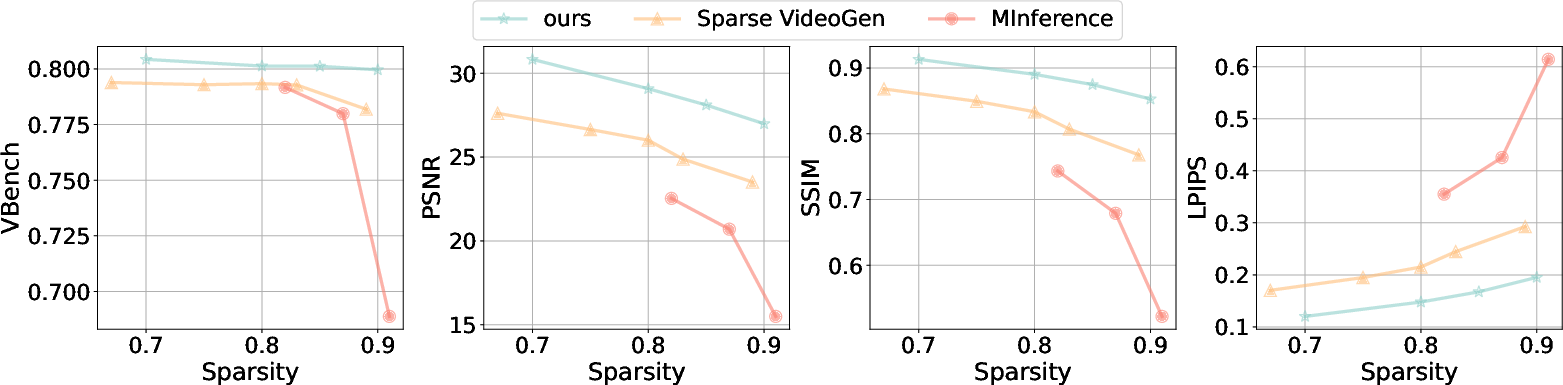
Figure 8: Quality-Sparsity trade off.
Warmup analysis shows that initial full attention steps improve similarity to dense attention outputs, but have limited impact on overall video quality (Figure 9).
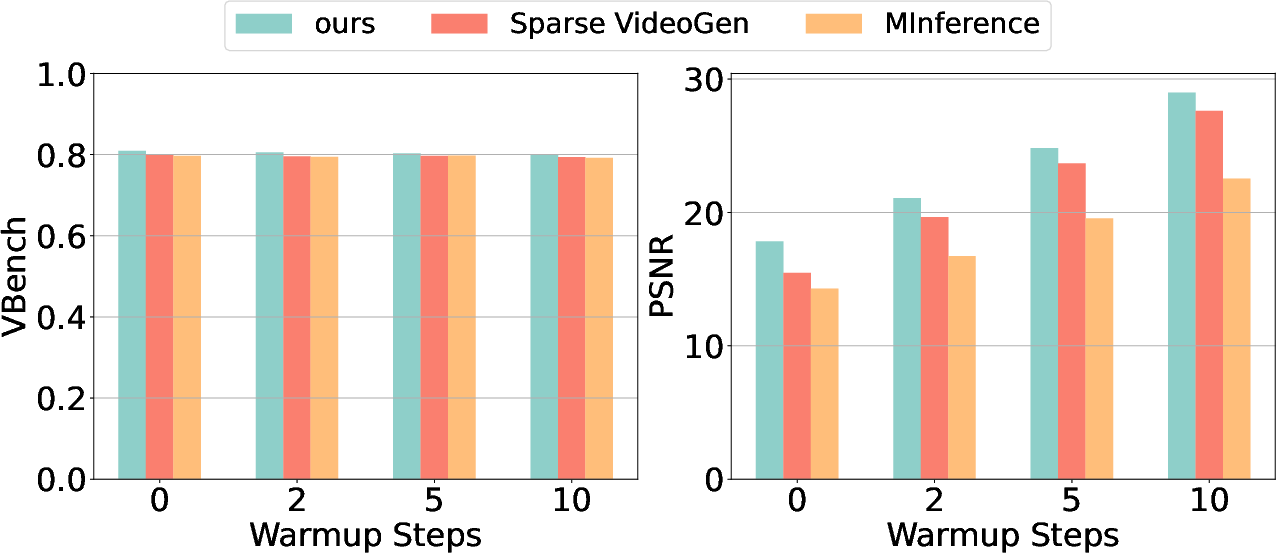
Figure 9: The impact of different warmup steps for AdaSpa, Sparse VideoGen, and MInference.
Search strategy experiments indicate diminishing returns with excessive online searches, confirming the strong pattern invariance across denoising steps.
Scaling tests reveal that AdaSpa's speedup increases with video length, reaching 4.01× for 24-second videos (Figure 10).
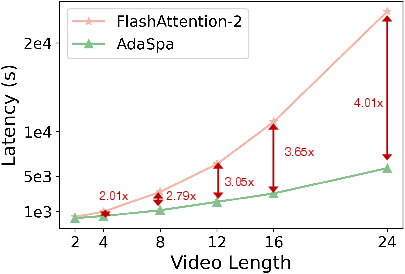
Figure 10: Scaling test of AdaSpa.
Implementation and Deployment Considerations
AdaSpa is implemented in Python and Triton, with efficient block-sparse kernels. Default parameters (sparsity=0.8, block_size=64, warmup steps) are empirically validated. The method is compatible with FlashAttention and block-sparse attention libraries, and can be integrated into DiT-based video generation pipelines without retraining.
Resource requirements are modest: AdaSpa reduces memory and compute overhead proportional to sparsity, with online search time under 5% of total attention computation. The method is robust to prompt and model variations, and scales efficiently to longer videos and higher resolutions.
Implications and Future Directions
AdaSpa establishes a new paradigm for efficient video generation in DiTs, demonstrating that training-free, adaptive sparse attention can deliver substantial acceleration without sacrificing fidelity. The blockified pattern and online precise search framework may generalize to other multimodal generative models with hierarchical attention structures.
Potential future developments include:
- Extending AdaSpa to support dynamic block sizes and multi-modal fusion.
- Integrating AdaSpa with distributed inference and hardware-specific optimizations.
- Exploring transmissibility of sparse patterns across steps and modalities for further efficiency gains.
- Investigating the impact of AdaSpa on downstream tasks such as video editing and 3D content generation.
Conclusion
AdaSpa provides a robust, scalable, and training-free solution for accelerating long video generation in DiTs. By leveraging hierarchical blockified sparsity and online precise search, AdaSpa achieves significant speedup with minimal quality loss, outperforming existing static and dynamic sparse attention methods. The approach is practical for real-world deployment and opens avenues for further research in efficient generative modeling.