TIPSv2: Advancing Vision-Language Pretraining with Enhanced Patch-Text Alignment
Abstract: Recent progress in vision-language pretraining has enabled significant improvements to many downstream computer vision applications, such as classification, retrieval, segmentation and depth prediction. However, a fundamental capability that these models still struggle with is aligning dense patch representations with text embeddings of corresponding concepts. In this work, we investigate this critical issue and propose novel techniques to enhance this capability in foundational vision-LLMs. First, we reveal that a patch-level distillation procedure significantly boosts dense patch-text alignment -- surprisingly, the patch-text alignment of the distilled student model strongly surpasses that of the teacher model. This observation inspires us to consider modifications to pretraining recipes, leading us to propose iBOT++, an upgrade to the commonly-used iBOT masked image objective, where unmasked tokens also contribute directly to the loss. This dramatically enhances patch-text alignment of pretrained models. Additionally, to improve vision-language pretraining efficiency and effectiveness, we modify the exponential moving average setup in the learning recipe, and introduce a caption sampling strategy to benefit from synthetic captions at different granularities. Combining these components, we develop TIPSv2, a new family of image-text encoder models suitable for a wide range of downstream applications. Through comprehensive experiments on 9 tasks and 20 datasets, we demonstrate strong performance, generally on par with or better than recent vision encoder models. Code and models are released via our project page at https://gdm-tipsv2.github.io/ .

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper introduces TIPSv2, a new way to train computer vision models that connect images with text. The main idea is to make the model not just understand what an image is “about” as a whole, but also understand which words match which parts of the image. Think of an image like a mosaic made of small tiles (called patches). TIPSv2 helps the model learn to link each tile to the right words, so it can do things like color in “all the trees” or “the dog” without being specially trained for that task.
What questions the researchers asked
The team focused on a few simple questions:
- How can we make a model better at matching words to specific parts of an image (patch‑text alignment), not just the whole image?
- Why do some smaller “student” models end up better at this than their bigger “teacher” models?
- Can we change the way we pretrain these models so they learn strong patch‑text alignment from the start?
- Can we make training more efficient (use less memory and compute) without losing quality?
How they approached it (methods, with simple analogies)
First, a few quick terms in everyday language:
- Patch: A small square piece of the image (like a tile in a mosaic).
- Patch‑text alignment: Matching each image tile to the right words.
- Distillation: A teacher model guiding a student model—like a tutor helping a younger student learn.
- Masked image modeling: Hide some tiles and make the model guess what they should look like.
- EMA (Exponential Moving Average): A running “average copy” of part of a model that gives steadier guidance—like a coach who keeps a smooth, long‑term average score to stabilize training.
Here’s what they did:
- Noticing a surprise in distillation
- When they used a big “teacher” model to train a smaller “student,” the student sometimes got much better at linking patches to words—even better than the teacher. This was surprising, because usually bigger models do better.
- They found two key factors:
- 1) Removing the masking during the student’s training (so the student sees all tiles) helped a lot.
- 2) Starting the student’s vision part from scratch (not from the teacher’s weights) avoided getting “stuck” in the teacher’s habits.
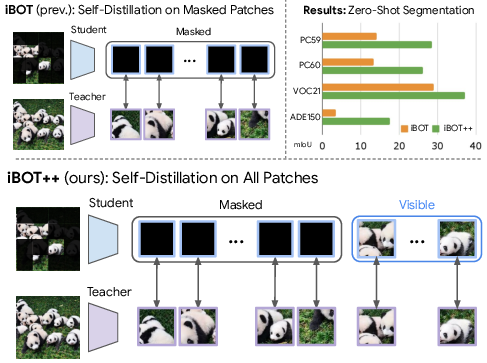
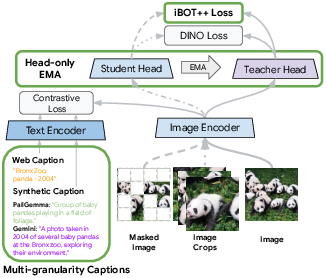
- Upgrading the core training objective: iBOT++
- Classic iBOT: Hide lots of patches and train the model to predict the hidden parts by matching a teacher’s features. The twist: iBOT mainly focuses on the hidden tiles.
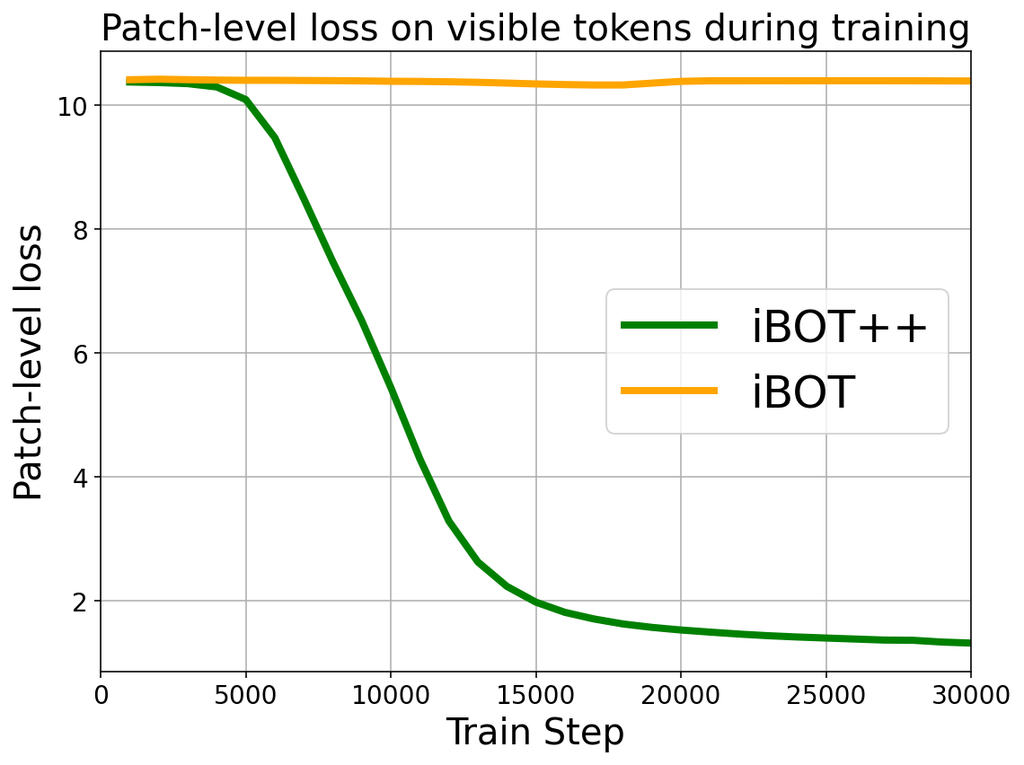
- iBOT++ (their new version): Still hide patches, but now also supervise the visible patches. In plain terms, you don’t just test the model on what’s hidden; you also make sure it gets the visible pieces right. This anchors all patches to good, stable features and strongly improves patch‑text alignment—like checking both the puzzle pieces you’re placing and the ones already on the table.
- Making training lighter: “Head‑only EMA”
- Usually, both the main vision network and the small “projection head” (a layer that maps features to training targets) use EMA teachers, which doubles memory cost.
- Because TIPSv2 also uses image‑text contrastive training (like CLIP), the backbone is already kept stable. So they apply EMA only to the head (“head‑only EMA”), saving a lot of memory and still keeping training stable.
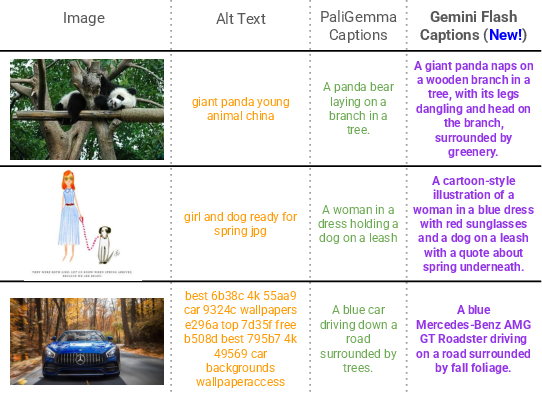
- Better text supervision: Multi‑granularity captions
- They mix different kinds of captions for each image:
- Short, messy web captions (alt‑text)
- Medium‑detail synthetic captions (from PaliGemma)
- Rich, detailed captions (from Gemini)
- They randomly alternate between simpler and more detailed captions. Why? If every caption is super detailed, the training becomes too easy and the model doesn’t learn general features as well. Mixing levels makes the model more robust and better at both global and local understanding.
- How they tested it
- They evaluated on many tasks without fine‑tuning the model:
- Zero‑shot segmentation: Color every pixel with a class (like “tree,” “road,” “dog”) just using the class names.
- Image‑text retrieval: Find the right image for a caption and vice versa.
- Image classification: Recognize objects (like ImageNet).
- Depth and surface normals: Estimate 3D structure from a single image.
- Fine‑grained retrieval: Match very specific items (cars, landmarks, etc.).
What they found and why it matters
- Distillation insight: Training a student with all patches supervised (no masking) and starting from scratch can greatly improve patch‑text alignment—even beyond the teacher model.
- iBOT++ works: Upgrading the pretraining to supervise both hidden and visible patches leads to much better patch‑text alignment. This gave big boosts in zero‑shot segmentation.
- Efficient training: Using “head‑only EMA” kept performance strong while cutting memory usage significantly (for some sizes, around 42% fewer trainable parameters in practice during training).
- Strong results across tasks:
- New state‑of‑the‑art or near‑best results on zero‑shot segmentation (a tough “dense” task).
- Competitive to top models on global tasks like image‑text retrieval.
- Strong performance on depth, surface normals, segmentation, and more—showing the model’s wide versatility.
Why this matters:
- Better patch‑text alignment means the model can “point” to exactly where words refer to in an image. This helps with open‑vocabulary segmentation, visual question answering, and any task needing precise grounding of language in pixels.
- Training efficiency improvements mean these abilities can be developed with less cost, making it more accessible to researchers and products.
What this could lead to (implications and impact)
- More accurate “grounded” vision systems: Apps that can highlight exactly where the “giraffe,” “stop sign,” or “front door handle” is in a picture—without extra training—become more reliable.
- Better tools for search and creativity: From smarter image search (“find the photo where the cat is on the shelf”) to aided editing (“select all windows in this building”), precise patch‑text alignment unlocks new user experiences.
- Practical training recipes: iBOT++ and head‑only EMA give a simpler, cheaper route to build strong vision‑LLMs, potentially speeding up research and product development.
- Future directions: Combining richer captions with improved patch supervision may keep improving how well models understand both the big picture and the small details.
In short, TIPSv2 shows a simple but powerful idea: don’t just learn from what’s missing—also learn from what’s visible. This change helps models link words to image parts much better, while also being more efficient to train.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to inform concrete follow-up research:
- Lack of theory for iBOT++: No principled explanation is given for why supervising visible tokens (in addition to masked ones) yields stronger patch–text alignment; the mechanism remains empirical and could benefit from formal analysis or probing studies (e.g., representational similarity, attention/attribution diagnostics).
- Optimal masking strategy is unclear: iBOT++ retains masking while supervising all tokens, but the paper does not systematically explore optimal masking ratios, schedules, or adaptive policies for different model sizes or datasets.
- Stability limits of head-only EMA: While head-only EMA reduces memory and works with contrastive supervision, its stability boundaries (e.g., under different loss weightings, lower contrastive signal, longer schedules, or SSL-only setups) are not characterized.
- Momentum and hyperparameters for head-only EMA: The paper does not ablate teacher momentum, temperature, or prototype count for the head-only EMA setting to understand sensitivity and robustness.
- Interaction between objectives is underexplored: How to balance CLIP-style contrastive loss vs. DINO/iBOT++ loss to optimize both global classification and dense alignment is not systematically studied (notably, ImageNet performance lags behind some baselines).
- Caption sampling policy is heuristic: Multi-granularity captioning uses random alternation between PaliGemma and Gemini captions, but there is no principled schedule, adaptive mechanism, or hardness-aware sampling; the impact of caption length/complexity on learning dynamics is not quantified beyond a qualitative rationale.
- Caption quality and bias analysis is absent: The effects of noisy, hallucinated, or biased synthetic captions (PaliGemma/Gemini) on alignment, robustness, and fairness are not measured; no analysis of failure cases, domain skew, or mitigation strategies is provided.
- Language coverage and multilinguality: Training/evaluation focuses on English; there is no assessment of multilingual text alignment or cross-lingual transfer (a key capability for many vision-language deployments).
- Evaluation of patch–text alignment is narrow: Dense alignment is assessed mainly via zero-shot semantic segmentation with a simple cosine-similarity protocol; other grounding tasks (open-vocabulary detection/instance segmentation, phrase grounding, RefCOCO/Entities, referring expression segmentation) are not evaluated.
- Comparability of zero-shot segmentation protocols: Some baselines use the more expensive sliding-window protocol (TCL) while TIPSv2 uses a simpler one; while this is noted, no head-to-head comparisons using identical protocols are provided.
- Layer choice for patch features is not studied: Patch embeddings are taken from the final layer (value embeddings); the paper does not explore whether earlier layers, feature registers, or layer-averaging yield better alignment or downstream performance post iBOT++.
- Scaling behavior and failure modes: The surprising finding that large teachers underperform on patch–text alignment is partially addressed by iBOT++, but a comprehensive scaling law (across data size, model size, and patch size) for alignment quality remains unreported.
- Generalization to other architectures: Experiments focus on ViTs (with some CLIP variants); applicability to other backbones (e.g., conv-hybrids, Swin, or Mamba-like models) and different patch sizes/resolutions is not examined.
- Robustness and OOD evaluations are limited: There is no study of robustness to distribution shift, corruptions (e.g., ImageNet-C/A), heavy occlusion, or adversarial perturbations, especially for dense alignment.
- Domain transfer breadth: Aside from UnED retrieval and standard vision benchmarks, cross-domain generalization to specialized domains (medical, remote sensing, document understanding beyond DOCCI) is not assessed.
- Fine-tuning behavior is unknown: All evaluations freeze the encoder; the effect of iBOT++ and head-only EMA on fine-tuning efficiency, stability, and final performance across tasks is not explored.
- Computational trade-offs are not fully quantified: Beyond parameter/memory reductions, there is no detailed reporting of wall-clock speedups, throughput, or energy cost vs. performance for iBOT++ and head-only EMA across model scales.
- Teacher quality in distillation: The phenomenon that a weaker teacher can yield a better student (for patch–text alignment) is intriguing but underexplained; the role of teacher architecture, head configuration, or intermediate feature targets is not dissected.
- Initialization choices beyond ViT are underexplored: The paper shows that randomly initializing the vision encoder during distillation is crucial, but does not examine alternative initializations (e.g., diverse SSL checkpoints, partial freezing schedules) or their interaction with iBOT++.
- Potential loss of invariance: Supervising visible tokens may trade off some augmentation invariances or encourage over-alignment to teacher idiosyncrasies; the paper does not measure changes in invariance (e.g., to scale, color, viewpoint) or downstream robustness implications.
- Prompt sensitivity for zero-shot segmentation: The protocol maps patches to class-name embeddings without exploring prompt engineering, synonym sets, or compositional prompts; the sensitivity of results to prompt choice is unknown.
- Background handling in segmentation: Treatment of background classes varies across datasets (PC59 vs. PC60), but the paper does not propose or evaluate mechanisms for background modeling in generalized open-vocabulary settings.
- Broader societal/ethical impacts: There is no analysis of dataset/content filtering, privacy considerations, or bias propagation from web data and synthetic captioners into downstream alignment-sensitive tasks.
- Reproducibility constraints: WebLI access, Gemini/PaliGemma caption generation details (prompts, parameters), and licensing constraints may impede replication; the paper does not provide a thorough reproducibility recipe for caption generation or data filtering.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released TIPSv2 models and code, or by modestly adapting existing vision–language pipelines. They leverage TIPSv2’s stronger patch–text alignment (via iBOT++), robust global and dense performance, and practical training/inference characteristics.
- Open‑vocabulary “text‑to‑selection” and background removal in creative tools
- Sectors: software, media/creative, e‑commerce
- What it enables: Users can type “select sky,” “mask the person,” or “remove background,” and the system produces masks directly from class names without task‑specific training.
- Why TIPSv2: State‑of‑the‑art zero‑shot segmentation from patch–text alignment; improved spatial coherence of patch features; no fine‑tuning required for many object categories.
- Tools/products/workflows: Photo/video editors, web design platforms, merchandising image tools; plug‑in that maps prompts to patch‑wise cosine scores and thresholds masks; optional post‑processing (e.g., CRF).
- Assumptions/dependencies: GPU/accelerator for high‑res inference; careful prompt engineering for category synonyms; distilled smaller variants (e.g., ViT‑B/L) for latency‑constrained deployments; license and usage compliance for released checkpoints.
- Text‑driven content redaction and compliance masking
- Sectors: policy/compliance, enterprise software, media
- What it enables: Automatically detect and mask categories like “faces,” “license plates,” “logos,” “weapons” from images/videos using only text labels; supports evolving policy lists.
- Why TIPSv2: Strong off‑the‑shelf dense alignment reduces the need for dataset‑specific training; open‑vocabulary handling helps keep pace with changing compliance taxonomies.
- Tools/products/workflows: Moderation/redaction pipelines; newsroom pre‑publication filters; enterprise PII scrubbing tools.
- Assumptions/dependencies: Requires threshold tuning and QA for low‑prevalence classes; domain shift may require calibration; human‑in‑the‑loop review for critical workflows.
- Visual search and “shop‑the‑look” with finer spatial grounding
- Sectors: retail/e‑commerce, media/search
- What it enables: Search by natural language (“red floral skirt with pleats”), retrieve images or sub‑regions; highlight matched regions to improve user trust and conversions.
- Why TIPSv2: Competitive global retrieval plus improved patch‑text alignment for spatial grounding; strong results on Flickr/COCO retrieval and fine‑grained benchmarks.
- Tools/products/workflows: Product discovery; catalog de‑duplication; interactive bounding‑box or mask overlays from text queries.
- Assumptions/dependencies: Catalog domain adaptation may improve performance; latency control via distilled models or tiling; prompt libraries to cover long‑tail product attributes.
- Dataset bootstrapping and pre‑annotation for CV teams
- Sectors: academia, industry ML/ML‑ops
- What it enables: Zero‑shot masks and labels for target classes to seed training data; reduces manual labeling burden for segmentation/detection tasks.
- Why TIPSv2: Strong zero‑shot segmentation and open‑vocab labeling provide immediate pseudo‑labels; robust dense features help active learning.
- Tools/products/workflows: Pre‑labeling in annotation tools; uncertainty‑based triage (human verification on low‑confidence regions); iterative refinement.
- Assumptions/dependencies: QA essential to mitigate bias from Web‑scale pretraining; prompt curation for domain synonyms; potential fine‑tuning for out‑of‑domain imagery.
- Enterprise and scientific document/image retrieval with spatial cues
- Sectors: enterprise search, finance, education, scientific publishing
- What it enables: Search images/figures/charts by text (“bar chart of quarterly revenue”), and highlight relevant regions; improved DOCCI‑style retrieval.
- Why TIPSv2: Strong retrieval and dense alignment enable semantic matching and region‑level grounding.
- Tools/products/workflows: Knowledge‑base search; compliance audits (e.g., find all slides with specific diagrams); educational material search.
- Assumptions/dependencies: Non‑photographic domains may benefit from prompt tuning; optional light adapters for diagram/chart specialization.
- Accessibility enhancements via grounded descriptions
- Sectors: accessibility, public sector, consumer apps
- What it enables: Generate more informative alt‑text and region‑wise descriptions (e.g., “a person in a wheelchair near a ramp”) by combining retrieval‑based labels with masks.
- Why TIPSv2: Dense alignment allows region‑specific textual tags to improve utility of descriptions.
- Tools/products/workflows: Screen reader support that announces labeled regions; captioning aided by pre‑extracted labels.
- Assumptions/dependencies: TIPSv2 is an encoder; pairing with a captioning model improves fluency; careful UX to avoid hallucination and respect privacy.
- Robotics prototyping: text‑guided grasp/interaction discovery
- Sectors: robotics, manufacturing, logistics
- What it enables: Prototype pipelines where a robot segments “handle,” “button,” or “socket” from a text query to propose interaction points.
- Why TIPSv2: Better patch‑text grounding yields reliable region proposals from class names without task‑specific labels.
- Tools/products/workflows: Visual perception front‑ends for pick‑and‑place; human‑in‑the‑loop validation in lab settings.
- Assumptions/dependencies: Real‑time constraints may require smaller distilled models and model compression; domain‑specific prompts; safety checks and sensor fusion for production.
- More efficient multimodal pretraining for ML teams
- Sectors: academia, AI labs, platform ML
- What it enables: Cut memory/compute costs by adopting head‑only EMA in combined SSL + contrastive training; upgrade existing CLIP‑like models with iBOT++ for stronger dense performance.
- Why TIPSv2: Demonstrates that supervising visible tokens (iBOT++) and head‑only EMA maintain or improve performance while reducing training overhead.
- Tools/products/workflows: Reusable pretraining recipes; drop‑in loss/head changes for internal encoders; faster iteration on new datasets.
- Assumptions/dependencies: Stability still requires EMA on heads; benefits are largest when a contrastive loss is present to prevent collapse.
- AR overlays and on‑device scene labeling (prototype‑ready)
- Sectors: AR/VR, consumer apps
- What it enables: Interactive labeling of objects in a scene by text prompts (“highlight all exits,” “find the power outlet”).
- Why TIPSv2: Open‑vocab segmentation without task‑specific training; works well across many natural categories.
- Tools/products/workflows: Edge inference with distilled models; tiled inference; prompt libraries.
- Assumptions/dependencies: Mobile latency and power constraints; domain prompts and calibration; privacy constraints for live camera streams.
Long‑Term Applications
These opportunities require additional research, adaptation, scaling, or integration with other systems to meet domain, safety, or real‑time constraints.
- Safety‑critical perception with open‑vocabulary grounding (autonomy, AR navigation)
- Sectors: autonomous driving, robotics, public safety
- Future capability: Reliable, text‑configurable perception stacks (“detect all construction signage,” “identify debris”) that adapt quickly to new categories.
- Dependencies/assumptions: Extensive domain adaptation, calibration, redundancy with other sensors; rigorous verification/validation; real‑time performance.
- Medical and scientific imaging: text‑prompted segmentation and retrieval
- Sectors: healthcare, biotech, scientific research
- Future capability: “Segment the left ventricle” or “highlight inflamed tissue” with open‑vocab prompts; retrieval of similar cases by description.
- Dependencies/assumptions: Domain shift from natural images; need for specialized pretraining or fine‑tuning with expert‑curated data; regulatory approval and clinical validation.
- Video‑level open‑vocabulary segmentation and search
- Sectors: media, security, sports analytics, education
- Future capability: Temporally consistent text‑driven masks and queries (“track the ball,” “find all scenes with smoke”) across long videos.
- Dependencies/assumptions: Temporal modeling and memory; efficient streaming inference; new training data and objectives extended to video.
- Multimodal agent tooling with grounded manipulation
- Sectors: software agents, robotics, industrial automation
- Future capability: Agents that can resolve referring expressions and ground LLM plans in pixel‑space (“open the top drawer,” “press the green button”) with patch‑level confidence.
- Dependencies/assumptions: Tight integration with LLMs, control policies, and safety monitors; datasets for instruction‑to‑action grounding; latency constraints.
- Interpretable foundation models and policy auditability
- Sectors: policy, governance, enterprise risk
- Future capability: Patch‑level alignment as a basis for human‑auditable explanations (“which pixels supported this decision?”) and content policy enforcement that adapts via text.
- Dependencies/assumptions: Robustness to adversarial inputs; standardized evaluation protocols; tools for logging and reviewing region‑level evidence.
- Sustainable large‑scale pretraining practices
- Sectors: AI infrastructure, academia/industry labs
- Future capability: Widespread adoption of head‑only EMA and visible‑token supervision to reduce training energy/cost for multimodal encoders.
- Dependencies/assumptions: Validation across diverse architectures and datasets; guidance on stability boundaries without full EMA; tooling support in common frameworks.
- Domain‑specific caption pipelines for better multimodal learning
- Sectors: enterprise AI, education, specialized verticals (e.g., legal, medical)
- Future capability: Automated multi‑granularity caption generation tailored to domain images (e.g., radiology, CAD) to improve contrastive supervision and downstream alignment.
- Dependencies/assumptions: High‑quality domain LLMs; cost/quality trade‑offs for caption generation; evaluations to avoid trivializing contrastive learning.
- 3D perception and mapping from stronger dense features
- Sectors: AR/VR, robotics, digital twins
- Future capability: Use improved depth/surface normal signals and dense semantic alignment as priors for SLAM/NeRF pipelines; text‑conditioned 3D editing.
- Dependencies/assumptions: Joint training with geometry tasks; temporal consistency; compute and memory for large‑scale 3D reconstruction.
- Edge and embedded deployments via extreme distillation and compression
- Sectors: mobile, IoT, drones, smart cameras
- Future capability: Real‑time open‑vocab segmentation and retrieval on low‑power devices.
- Dependencies/assumptions: Further distillation/quantization, pruning, and efficient token processing; accuracy/latency trade‑off studies; hardware‑aware model design.
- Cross‑modal compliance and discovery in finance and enterprise
- Sectors: finance, legal, enterprise compliance
- Future capability: Identify and segment visual elements in documents (charts, signatures, seals) by policy text; link visual elements to textual references for audits.
- Dependencies/assumptions: Document‑specific adaptation; integration with OCR/NLP pipelines; human oversight for critical decisions.
Notes on Feasibility and Risk (assumptions that cut across applications)
- Domain shift: TIPSv2 is trained on web imagery; specialized domains (medical, satellite, CAD) typically require adaptation or fine‑tuning.
- Bias and fairness: Web‑scale data can encode societal biases; sensitive deployments need bias audits and mitigation strategies.
- Compute and latency: Largest checkpoints (e.g., ViT‑g) are heavy; consider distilled variants, quantization, tiling, and batching for production.
- Prompting and taxonomy: Open‑vocabulary performance depends on well‑chosen labels/synonyms; maintain glossaries for target domains.
- Licensing and data governance: Ensure usage complies with released model/data licenses and organizational policies.
- Safety and human oversight: Use human‑in‑the‑loop review and conservative thresholds for high‑stakes settings (healthcare, safety, legal).
Glossary
- Alt-text captions: Descriptive text associated with web images used as weak supervision for image-text training. "one supervised by web alt-text captions for object-centric details,"
- Angular RMSE: A metric measuring the root mean squared error of predicted surface normal angles compared to ground truth. "reporting angular RMSE"
- CLIP: A contrastive vision-language pretraining method aligning images and texts through large-scale web supervision. "Following the approach of CLIP~\citep{radford2021clip}"
- CLS token: A special Transformer token used to aggregate a global representation (embedding) of the input. "two separate CLS global embeddings"
- Contrastive image-text learning: Training that brings matching image and text representations closer while separating mismatched pairs. "integrates contrastive image-text learning with self-supervised learning."
- Cross-entropy loss: A classification loss measuring divergence between predicted distributions and targets. "by a cross-entropy loss."
- DINO: A self-supervised visual pretraining method based on self-distillation and invariance to augmentations. "In the global-level self-distillation objective (DINO~\citep{caron2021dino})"
- Distillation: Training a student model to mimic a (usually larger or stronger) teacher model’s representations or outputs. "Distillation only requires two modifications:"
- Exponential Moving Average (EMA): A technique maintaining a slowly-updated copy of parameters to provide stable training targets. "the teacher network that is the exponential moving average (EMA) of the student network ."
- Gemini 1.5 Flash: A multimodal LLM used here to generate richer synthetic image captions. "Gemini 1.5 Flash \cite{geminiteam2024gemini}"
- Head-only EMA: An EMA variant that updates only the projection heads (not the main encoder) to save memory and stabilize training. "Head-only EMA enables memory-efficient self-supervised losses."
- iBOT: A masked image modeling objective that aligns student patch features to a teacher’s features for masked regions. "the well-known iBOT~\cite{zhou2022ibot} self-supervised objective"
- iBOT++: An enhancement to iBOT that also supervises visible (unmasked) patches to improve local semantics and alignment. "we propose iBOT++, an upgrade to the commonly-used iBOT masked image objective"
- InfoNCE: A contrastive loss that maximizes similarity of positive pairs while minimizing that of negatives. "is an InfoNCE~\citep{oord2018infonce} loss"
- Linear probe: Evaluating frozen features by training a simple linear classifier or regressor on top for a downstream task. "semantic segmentation with linear probe"
- Masked image modeling (MIM): Pretraining by reconstructing or matching representations of masked parts of an image. "masked image modeling (MIM) strategy"
- Masking ratio: The proportion of image patches masked in MIM-based training. "We ablate the effect of masking ratio"
- Mean Intersection over Union (mIoU): A standard metric for segmentation accuracy averaged across classes. "reporting mean Intersection over Union (mIoU)."
- Monocular depth estimation: Predicting scene depth from a single RGB image. "monocular depth estimation on the scene-centric NYUv2"
- Multi-granularity captions: Training with captions of varying detail to improve robustness and learning dynamics. "Multi-granularity captions provide a range of possible textual descriptions for images, increasing the robustness of the model."
- Open-vocabulary segmentation: Segmenting images into classes specified by arbitrary text labels not seen during training. "like open-vocabulary segmentation."
- PaliGemma: A vision-LLM used to generate synthetic captions that emphasize spatial details. "PaliGemma ~\citep{beyer2024paligemma}"
- Patch embeddings: Vector representations of image patches produced by a ViT encoder. "patch embeddings corresponding to different image regions."
- Patch-text alignment: The correspondence between local image (patch) features and textual concepts. "This dramatically enhances patch-text alignment of pretrained models."
- Projection layers: Small neural heads projecting encoder features into a space used for supervision (e.g., prototypes). "This updates only the projection layers"
- Prototypes: High-dimensional targets (often codebook-like) used to supervise representations in self-distillation. "and the resulting prototypes are supervised to be invariant"
- Recall@1: Retrieval metric measuring the fraction of queries for which the correct item is ranked first. "reporting recall@1"
- Self-supervised learning (SSL): Learning representations from unlabeled data using pretext objectives. "self-supervised learning (SSL) methods"
- Sliding window protocol (TCL): A computationally intensive evaluation that applies a model over overlapping crops for dense tasks. "the expensive sliding window protocol from TCL~\citep{cha2023learning}"
- Student-teacher distillation: A training setup where a student network learns from a teacher’s outputs or features. "adopt a student-teacher distillation setup"
- Temporal ensembling: Stabilizing training targets by averaging model parameters or predictions over time. "to provide stable targets via temporal ensembling."
- Text encoder: A neural network that converts input text into embedding vectors aligned with image embeddings. "a text encoder mapping texts to a text embedding"
- Value embeddings: Transformer value-state features from the final layer used here as patch-level representations. "use the value embeddings of the final transformer layer as patch embeddings"
- Vision-language pretraining: Jointly training models on images and text to learn aligned multimodal representations. "Recent progress in vision-language pretraining has enabled significant improvements"
- Vision Transformer (ViT): A transformer-based image encoder operating on patch tokens. "Vision Transformer (ViT)~\citep{dosovitskiy2020vit}"
- WebLI: A large web-crawled image-text dataset used for training. "WebLI dataset~\citep{chen23pali}"
- Zero-shot classification: Classifying images into categories with no task-specific training by matching to text labels. "zero-shot classification on ImageNet-1K"
- Zero-shot segmentation: Segmenting images into categories without any task-specific finetuning, often via text-aligned features. "zero-shot segmentation results"
Collections
Sign up for free to add this paper to one or more collections.