- The paper introduces TIPS, a novel model that improves spatial understanding by combining synthetic image captions with self-supervised masked image modeling.
- It employs dual image-text embedding with an extra [CLS] token, enhancing feature quality for both dense prediction and global recognition tasks.
- TIPS achieves competitive performance in segmentation and retrieval, outperforming existing methods and advancing novel view synthesis applications.
TIPS: Text-Image Pretraining with Spatial awareness
This paper introduces Text-Image Pretraining with Spatial awareness (TIPS), a novel image-text model designed to enhance spatial awareness in learned representations, thereby improving performance on both dense and global vision tasks. TIPS addresses the limitations of existing image-text models, which often fall short in dense prediction tasks compared to self-supervised methods. The approach combines synthetic image captions to improve weak supervision, along with self-supervised masked modeling to improve image feature quality.
Methodological Innovations
The paper identifies two key limitations of existing image-text learning approaches: the noisy nature of web-based image captions and the lack of explicit mechanisms to encourage spatially coherent image features. To address these, TIPS incorporates the following innovations:
- Synthetic Image Captions: The paper uses a multimodal generative model to create synthetic textual descriptions of images. These captions provide richer spatial information compared to noisy web captions, leading to improved dense understanding. The paper observes that noisy web captions often contain fine-grained details useful for global understanding tasks.
- Dual Image-Text Embedding: To leverage the strengths of both noisy web captions and synthetic captions, the model is trained with both types of captions using separate image-text contrastive losses. This is achieved by introducing an additional \verb+[CLS]+ token to the vision transformer, resulting in two global embedding vectors: eg for noisy captions and e^g for synthetic captions.
- Self-Supervised Learning: Inspired by recent self-supervised learning techniques, the model incorporates self-distillation and masked image modeling (MIM) into the image-text learning framework. This is done to incentivize the learning of spatially aware representations. The self-distillation loss encourages consistency between local crop embeddings and the global image embedding, while the MIM loss encourages the model to recover the semantics of masked patches based on the visible patches.
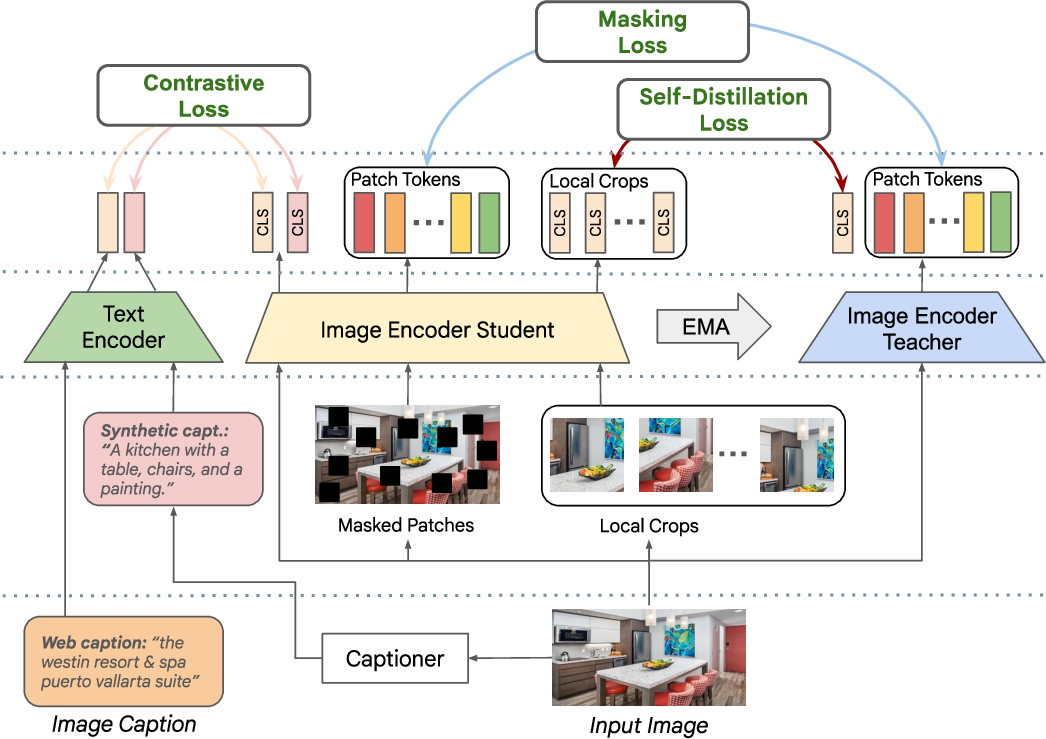
Figure 1: Block diagram of TIPS. From bottom to top: given an input image, we produce masked and cropped augmentations, along with synthetic descriptive captions from a captioner model. They are fed into the text and image encoders, along with the noisy web caption, and the output tokens are used in the losses. The contrastive loss makes use of the two captions, aligning them with two [CLS] tokens obtained from the image encoder. TIPS also employs self-distillation applied to the local crops and a masked image modeling loss applied to dense patch tokens, which encourage spatially-aware and discriminative image representations.
Implementation and Scaling
The TIPS model uses a Vision Transformer (ViT) architecture, which has been shown to scale well in various tasks. The model is scaled to the ViT-g architecture with a patch size of $14$, using the SwiGLU feed-forward network variant. The embedding dimension is adapted to $1536$ with $24$ heads, resulting in a $1.1$B parameter image encoder. The text transformer is scaled to $12$ layers, with the same embedding dimension and number of heads as the image encoder.
The model is trained on a curated set of $117$M public images from the WebLI dataset. The dataset is filtered in successive rounds to improve its quality for model training. The filtering process includes removing image-text pairs with low image-text similarities and keeping only pairs with English captions. Additionally, images are selected based on their similarity to images in curated datasets.
Experimental Results
The effectiveness of TIPS is evaluated on a suite of $8$ tasks involving $16$ datasets. The tasks cover a wide range of computer vision applications, including semantic segmentation, monocular depth estimation, surface normal estimation, image classification, fine-grained and instance-level retrieval, image-to-text retrieval, text-to-image retrieval, and zero-shot classification. The experiments demonstrate that TIPS achieves strong and competitive performance across these tasks, often outperforming existing methods.
In particular, TIPS demonstrates substantial gains in dense prediction tasks compared to existing image-text models. The results indicate that TIPS achieves comparable performance to self-supervised methods like DINOv2 in most cases and surpasses them in segmentation and retrieval. The paper highlights that while recent image-text models have achieved excellent results in multimodal retrieval or zero-shot classification, these gains do not translate to improved features for dense understanding.
Novel View Synthesis Application

Figure 2: \smallQualitative results on novel view synthesis from LRM~\citep{hong2024lrmlargereconstructionmodel}
The paper shows the application of single-image to 3D, where modern large reconstruction models rely on high-quality pre-trained image encoders to produce image tokens for an encoder/decoder transformer. The paper evaluates TIPS performance in the LRM framework and compares DINO-B/16 to an equivalently-sized TIPS-B/14 and shows that TIPS outperforms DINO as an image encoder for large reconstruction models, with enhanced novel view synthesis capabilities.
Conclusion
The TIPS model represents a step forward in general-purpose image-text representation learning. By incorporating synthetic image captions and self-supervised learning techniques, TIPS achieves improved spatial awareness and strong performance across a wide range of vision tasks. The authors suggest that the presented findings will encourage the development of next-generation image representations, to enable multimodal and spatially grounded applications.