- The paper presents a reinforced training framework using enhanced teacher ensembles and synthetic captions to improve zero-shot ImageNet-1k accuracy by up to 2.8%.
- It leverages the high-quality DFN-5B dataset and optimal logit tuning, resulting in models that are 2× smaller and 2.5× faster than previous benchmarks.
- The study introduces innovative five-stage architectures (MCi3 and MCi4) that deliver up to 7.1× latency reductions at high resolutions, ideal for mobile deployment.
MobileCLIP2: Advancements in Multi-Modal Reinforced Training for Efficient Image-Text Models
Introduction
MobileCLIP2 presents a comprehensive enhancement to multi-modal image-text modeling, specifically targeting low-latency, resource-constrained environments such as mobile and edge devices. Building upon the MobileCLIP framework, this work introduces improved multi-modal reinforced training, leveraging superior teacher ensembles and caption generators, and delivers a new family of models that achieve state-of-the-art zero-shot accuracy on ImageNet-1k with significantly reduced latency and model size. The methodology is grounded in systematic ablations and empirical analysis, providing actionable insights for both model training and deployment.
Multi-Modal Reinforced Training: Methodological Improvements
MobileCLIP2 refines the multi-modal reinforced training paradigm by integrating several key improvements:
- Enhanced Base Dataset: The transition from DataComp-1B to DFN-5B as the foundational dataset yields measurable gains in downstream accuracy, attributed to more sophisticated filtering and higher-quality image-text pairs.
- Superior CLIP Teacher Ensembles: The use of DFN-pretrained CLIP models (ViT-L/14 and ViT-H/14) as distillation targets, with careful logit scale tuning, results in up to 2.8% improvement in ImageNet-1k validation accuracy over previous teacher ensembles.
- Improved Synthetic Caption Generation: Caption generators are pretrained on DFN-2B and fine-tuned on high-quality datasets (e.g., MSCOCO-38k), with ablations demonstrating that fine-tuning is essential for robust retrieval performance and caption diversity.
- Dataset Reinforcement: The DFNDR datasets incorporate both teacher embeddings and multiple synthetic captions per image, enabling efficient offline knowledge distillation and accelerating training convergence.
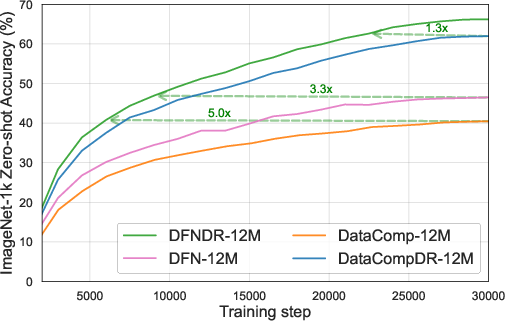
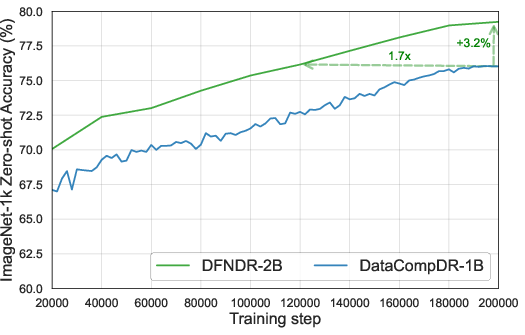
Figure 1: Left: Training on DFNDR-12M is up to 5x more efficient compared to DataComp-1B12M, with direct wall-clock time savings due to reduced sample requirements.
Architectural Innovations
MobileCLIP2 introduces two new architecture variants (MCi3 and MCi4) that extend the FastViT-based image encoder design to five compute stages, optimizing parameter distribution and scaling efficiency for higher input resolutions. This architectural choice is empirically validated to deliver substantial latency reductions—up to 7.1x faster at 1024×1024 resolution compared to scaled four-stage models—without sacrificing accuracy.
(Figure 2)
Figure 2: MCi3 five-stage design achieves lower latency at higher resolutions, critical for dense prediction tasks.
MobileCLIP2 models, trained on the reinforced DFNDR-2B dataset, consistently outperform prior art across a spectrum of zero-shot classification and retrieval benchmarks. Notably:
- ImageNet-1k Zero-Shot Accuracy: MobileCLIP2 matches the performance of SigLIP-SO400M/14 while being 2× smaller and 2.5× faster than DFN ViT-L/14.
- Dense Prediction Tasks: On object detection (MS-COCO), semantic segmentation (ADE20k), and depth estimation (NYUv2), MobileCLIP2-pretrained models surpass supervised and MAE-pretrained baselines for both ViT and hybrid MCi architectures.
- Vision-LLM (VLM) Transfer: In LLaVA-1.5 evaluations, MobileCLIP2-pretrained vision encoders yield up to 3.5% higher average accuracy compared to models trained on DFN or DataComp alone.
Ablation Studies and Training Efficiency
Extensive ablations reveal several critical findings:
- Temperature Tuning in Distillation: Optimal logit scales for teacher models are necessary for effective knowledge transfer, with performance robust to small deviations.
- Caption Diversity: While increasing the number of synthetic captions per image saturates gains beyond two, diversity from fine-tuning on different datasets (e.g., DOCCI) can yield further improvements in average accuracy.
- Dataset Size vs. Quality: The 2B subset of DFNDR is sufficient for large-scale training, with no significant loss in performance compared to the full 5B set.
Practical Implications and Deployment Considerations
MobileCLIP2's methodology and released codebase enable scalable generation of reinforced datasets with arbitrary teacher models, facilitating reproducible and efficient training pipelines. The models' low latency and compact size make them suitable for deployment in real-time mobile applications, with flexibility to select architectures and training recipes tailored to specific downstream tasks (classification, retrieval, dense prediction).
Theoretical and Future Directions
The demonstrated additive improvements from combining multiple sources of reinforcement (teacher ensembles, diverse synthetic captions) suggest that further gains may be achievable by expanding the diversity and quality of both teachers and captioners. The approach also highlights the importance of dataset curation and filtering, as biases in training data directly impact model generalization. Future work may explore multilingual dataset reinforcement, advanced loss functions for long-context captioning, and integration with emerging VLM architectures.
Conclusion
MobileCLIP2 establishes a new benchmark for efficient multi-modal image-text modeling, combining architectural innovation with systematic improvements in reinforced training. The release of pretrained models and scalable data generation tools positions MobileCLIP2 as a practical foundation for both research and production deployment in resource-constrained environments. The findings underscore the value of dataset reinforcement, teacher ensemble distillation, and caption diversity in advancing the state-of-the-art for mobile and edge AI applications.

