- The paper introduces a taxonomy categorizing latent reasoning techniques into activation-based and hidden-state methods to expand computational depth.
- It details methodologies like recurrent architectural designs and training-induced loops that refine multi-step inference without relying on explicit language tokens.
- The analysis highlights implications for infinite-depth reasoning and mechanistic interpretability, paving the way for more powerful and flexible LLMs.
Latent Reasoning in Neural Networks: A Comprehensive Survey
This essay summarizes "A Survey on Latent Reasoning" (2507.06203), which provides a detailed overview of the emerging field of latent reasoning in LLMs. The survey explores methodologies that enable LLMs to perform multi-step inference within their continuous hidden states, thereby overcoming the limitations imposed by explicit chain-of-thought (CoT) reasoning that relies on natural language.
Core Concepts and Categorization
The paper introduces a taxonomy that categorizes latent reasoning techniques based on how they expand computational depth and sequential capacity. These techniques are broadly divided into vertical recurrence (activation-based methods) and horizontal recurrence (hidden-state methods). Vertical recurrence applies feedback loops to activation values, while horizontal recurrence propagates context across long sequences using hidden states. Fine-tuning strategies designed to compress or internalize explicit reasoning traces are also explored. The survey emphasizes the potential of latent CoT to surpass language-based reasoning constraints by shifting the reasoning process into the model's continuous representational space.
(Figure 1)
Figure 1: Explicit reasoning transmits discrete tokens (≈15bits each), whereas latent reasoning exchanges full 2560-dimensional FP16 hidden states (≈40,960bits each), revealing a ∼2.7×103-fold bandwidth gap between the two approaches.
Activation-Based Recurrence
Activation-based methods achieve latent reasoning by creating recurrent computational flows, either through architectural design or training-time manipulation. These methods share a common principle: iteratively refining representations without generating explicit reasoning tokens. Loop-based architectures represent the foundational approach, implementing continuous activation propagation across Transformer layers through explicit architectural modifications. Since the seminal work of the Universal Transformer (UT), the field has undergone systematic evolution, converging on a three-stage Pre/Loop/Coda structure that separates input encoding, iterative reasoning, and output decoding.
Training-induced recurrence creates implicit loops in the computation graph without changing the model's underlying structure. This approach is valuable as it enables existing pretrained models to develop latent reasoning capabilities without architectural constraints. The core principle involves creating implicit loops in the computation graph, whether by feeding activations back into the model, compressing multi-step reasoning into iteratively-processed representations, or extending the effective computation depth through strategic token insertion.
Hidden-State-Based Methods
These methods expand the model's memory horizontally, allowing it to access and integrate information over longer sequences. Traditional Transformers handle temporal information by storing previous token inputs as key-value pairs in the KV cache. However, this suffers from unbounded memory consumption that scales linearly with sequence length. To address this challenge, previous information can be compressed into a fixed-size vector or matrix, similar to RNNs. When working with hidden states, there are two primary approaches to enhance their expressiveness: (1) the Linear-State recurrence approach, which applies update and decay rules to the hidden states, and (2) Gradient-State recurrence approach, treating hidden states as online-learning parameters and optimizing them using online learning methods. The paper highlights a duality where linear state models can be reinterpreted as gradient descent optimization, conceptually unifying temporal and depth recurrence.
Mechanical Interpretability of Latent Reasoning
The survey explores the mechanistic interpretability of latent reasoning, examining the role of neural network layers as the computational substrate for reasoning. The theory of Layer Specialization posits that different layers develop distinct, hierarchical functions, forming an implicit computational pipeline analogous to an explicit CoT. Shallow layers perform feature extraction, intermediate layers handle complex logical operations, and deep layers perform final integration. The flow of information across these layers is crucial for the reasoning process. The survey also addresses the Turing completeness of layer-based latent CoT, discussing the conditions under which Transformers can achieve universal computational capabilities.
Towards Infinite-Depth Reasoning
(Figure 2)
Figure 2: Taxonomy of Latent Reasoning.
The survey explores advanced paradigms at the frontier of LLM cognition, focusing on the pursuit of infinite-depth reasoning. This concept refers to a model's ability to devote unbounded computational steps to refine a solution, moving beyond fixed-depth architectures. The discussion centers on spatial infinite reasoning as realized by text diffusion models. Unlike traditional autoregressive generation, these models operate on the entire output sequence in parallel, enabling global planning and iterative self-correction through bidirectional context. This approach facilitates globally consistent and reversible reasoning processes, offering a promising path toward more powerful and flexible AI systems. Text diffusion models are organized into three architectural families: Masked Diffusion Models, Embedding-based Diffusion Models, and Hybrid AR-Diffusion Models.
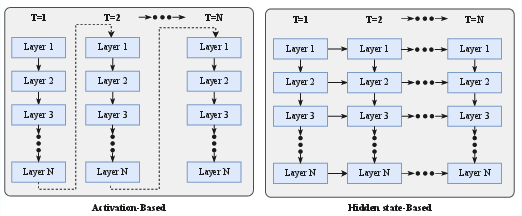
Figure 3: An evolutionary graph of the text diffusion models, including three architectural families: Masked Diffusion Models, Embedding-based Diffusion Models, and Hybrid AR-Diffusion Models.
Implications and Future Directions
The survey concludes by emphasizing the potential of latent CoT to overcome the limitations of language-based reasoning. By operating in a continuous space, models can explore more efficient and powerful reasoning strategies without direct linguistic equivalents.

