- The paper introduces a video-guided translation architecture that leverages global video context to resolve ambiguities in subtitles.
- It employs semantic retrieval with pretrained encoders and a text-aware segment selector to fuse temporally adjacent segments for enriched contextual signals.
- Region-aware and bi-directional cross-modal attention modules, combined with Transformer decoding, yield improved BLEU and METEOR scores on documentary datasets.
Video-guided Machine Translation with Global Video Context: Technical Summary
Motivation and Background
Conventional neural machine translation (NMT) models exhibit limitations when source subtitles are sparse or ambiguous, especially in documentary and narrative video domains. While multimodal machine translation (MMT) frameworks enhance translation quality by integrating auxiliary visual modalities, previous works largely utilize static images or locally-aligned video segments, neglecting the global narrative structure pervasive in long-form video content. The present paper addresses this deficiency by proposing a video-guided multimodal translation (VMT) architecture that explicitly incorporates global video context, utilizing semantic retrieval and region-aware attention mechanisms for improved disambiguation and semantic alignment.
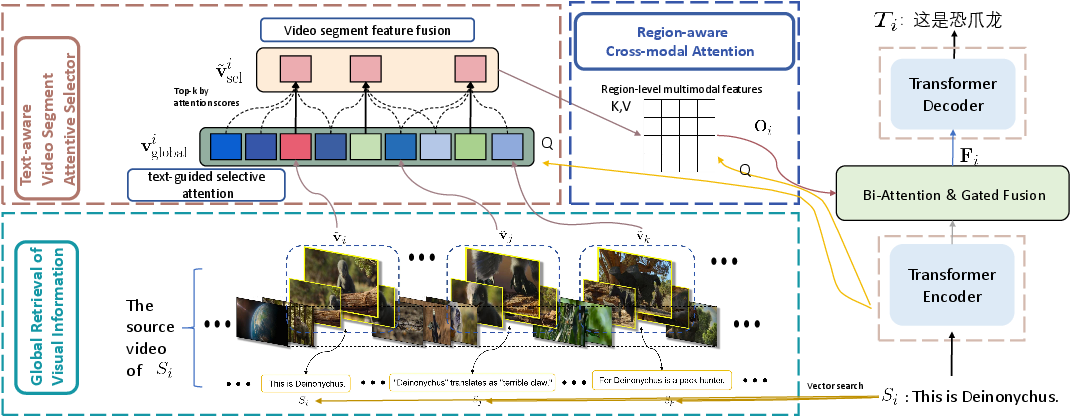
Figure 1: The overview of the proposed global context-aware multimodal translation framework, integrating semantic retrieval, segment selection, cross-modal attention, and Transformer-based text generation.
Global Context Retrieval and Fusion
The model begins by embedding each subtitle in a high-dimensional semantic space using pretrained encoders (CLIP), followed by retrieval of the top-P semantically similar subtitles across the entire video via FAISS-based vector search. Corresponding video segments for these subtitles are then fused with their temporally adjacent segments (window size w), scaled by a fixed factor γ to reduce semantic noise. This design maintains extended temporal context and narrative coherence, counteracting the local myopia of prior architectures and ensuring that ambiguous source expressions can be resolved with broader visual evidence.
Text-aware Segment Selection
A Text-aware Video Segment Attentive Selector quantifies cross-modal alignment using attention scores between the encoded subtitle and globally contextualized video segments. The top-K segments are adaptively selected as the primary visual context. Unselected segments within the relevant temporal range are aggregated using a weighted fusion coefficient λ to mitigate information loss and enhance context density. Unlike static retrieval, this mechanism is optimized end-to-end, allowing dynamic assignment of relevance during training.
Region-aware Cross-modal Attention
For fine-grained semantic alignment, the Region-aware Cross-modal Attention module projects both textual and video features into a common space and operates at region-level granularity. Queries from text attend to each region in all selected segments, facilitating hierarchical token-region interactions via multi-head attention. Average pooling across spatial regions yields a fused representation that effectively bridges modality gaps and supports nuanced disambiguation.
To further enhance semantic interaction, Bi-directional Cross-modal Attention is utilized. Text-to-video (T2V) and video-to-text (V2T) dependencies are captured by simultaneous attention operations, and their outputs are fused via a learnable gating mechanism. This yields a multimodal representation Fi that is fed to a Transformer decoder, supporting joint attention during sequential token prediction. The translation proceeds autoregressively, leveraging both text and fused visual cues at each step.
Experimental Results
The paper evaluates the proposed framework on TopicVD—a large-scale documentary subtitle dataset (256 videos, 122,930 pairs)—and on the BigVideo dataset for generalization. The models are compared against standard text-only NMT, image-MMT, segment-level video-MMT, and the BigVideo baseline (contrastive learning). On TopicVD, the proposed method achieves 30.47 BLEU / 38.96 METEOR, outperforming segment-level video-MMT and BigVideo by +1.24 and +4.55 BLEU, respectively. Ablation studies confirm that both global retrieval and the segment selector are essential, with performance dropping to 29.48 BLEU when both are omitted.
On BigVideo, results are comparable (46.78 BLEU), as expected given its subtitle temporal locality and limited narrative scope. Hyperparameter studies indicate optimal settings at P=10, w=2, K=5, balancing context expansion against semantic noise and irrelevance. Qualitative analysis demonstrates the method's superior capacity for disambiguation in cases where local visual information is misleading.

Figure 2: Correct translation example—"dry" is disambiguated using global visual context, accurately mapped to Chinese as “lack of moisture in air” rather than “depletion of a water source”.
Implications and Future Directions
The paper's results substantiate the efficacy of global video context modeling in VMT, particularly for documentary and narrative content where local alignment is insufficient. The proposed modular retrieval, adaptive selection, and region-level cross-modal attention strategies are shown to be synergistic, facilitating robust semantic grounding and ambiguity resolution. Further, preliminary experiments with Qwen3-VL vision–LLMs demonstrate improved BLEU scores (+1.93) when integrating text-aware frame selection, underscoring compatibility and scalability with contemporary large VLMs.
Theoretically, the framework offers a template for cross-modal representation learning in language–vision tasks requiring long-range dependencies, motivating extensions to future VLMs capable of handling extended video inputs.
Conclusion
The paper introduces a principled global visual context retrieval and fusion architecture that goes beyond local segment alignment, empirically outperforming prior MMT and VMT baselines on long-form translation tasks. Its design effectively balances context expansion and semantic density, while region-aware and bi-directional attention modules support precise cross-modal interactions. The method's compatibility with large VLMs further positions it as a foundational strategy for scalable, context-aware multimodal translation and general vision-language understanding (2604.06789).