- The paper introduces a novel visual prompting paradigm that overlays colored bounding boxes and motion trails to efficiently encode object dynamics in videos.
- The method reduces text token usage by up to 93% while preserving detailed spatial-temporal cues through adaptive rendering and a minimal text legend.
- Empirical results on multiple benchmarks confirm that BoxTuning achieves performance on par with or better than traditional methods in object-centric video reasoning tasks.
BoxTuning: A Visual Prompting Paradigm for Efficient Object-Centric Video MLLM Fine-Tuning
Introduction and Motivation
The proliferation of multimodal LLMs (MLLMs) has catalyzed significant progress in video understanding. For video question answering (QA), explicit object-level spatial and temporal reasoning remains an open challenge, as conventional MLLMs primarily encode frames holistically, resulting in implicit or insufficient object grounding. ObjectMLLM [tang2025objectmllm] introduced textual serialization of per-frame bounding box coordinates to bridge this gap, demonstrating quantifiable performance gains in spatial-temporal tasks. However, this text-coordinate paradigm incurs substantial token overhead—up to 1,184 extra text tokens per video in benchmarks such as NExT-QA—which necessitates aggressive temporal downsampling and produces a modality-incoherent representation of inherently visual information.
BoxTuning (2604.11136) addresses these inefficiencies by reframing object-centric input as a visual prompting problem. Instead of textually encoding coordinates, it directly renders colored bounding boxes and trajectory trails onto video frames, preserving fine-grained spatial and temporal information while reducing text token usage by 87–93%. Only a minimal text legend is appended, mapping colors to class identities. This visual-first strategy eliminates the high-dimensional text bottleneck and recovers motion cues that aggressive downsampling discards.
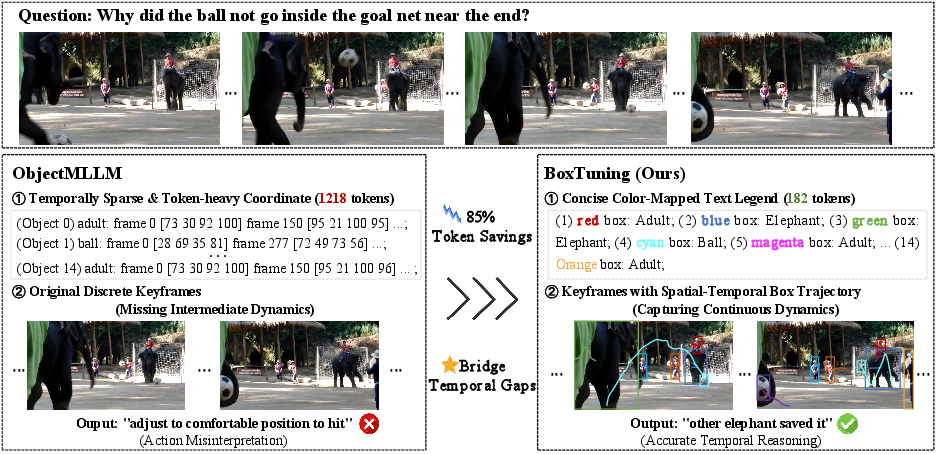
Figure 1: Comparison of object-centric representation strategies for video MLLMs. Left: ObjectMLLM serializes bounding boxes as text resulting in high token cost and coarse temporal sampling. Right: BoxTuning overlays boxes and trajectories directly on visual frames, achieving drastic text token savings and denser temporal coverage.
Method: Direct Visual Injection of Object Dynamics
Pipeline Overview
BoxTuning overlays two explicit cues on each sampled video frame:
- Colored bounding boxes: Each detected object is consistently assigned a color from a palette (up to 32 maximally distinguishable colors), visually demarcating object locations throughout the sequence.
- Trajectory trails: Polylines trace each object's centroid over the interval between consecutive sampled frames, encoding both direction and velocity cues for the vision backbone.
The categorical correspondence between colors and object classes is summarized by a terse, color-indexed text legend (9 tokens per object on average). Off-the-shelf YOLO-World [cheng2024yoloworld] provides object detection on designated frames, and SAM-2 [ravi2025sam2] generates consistent object tracks for accurate interpolation and mask-based propagation.
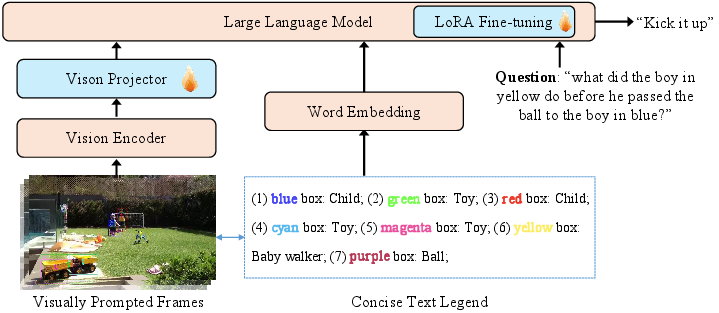
Figure 2: Overview of the BoxTuning framework. Object boxes and trails derived from tracking are rendered on sampled frames, then input to a frozen vision backbone. The minimal text legend enables bridging to the LLM while preserving context capacity.
This approach contrasts sharply with ObjectMLLM, which serializes N×T object coordinates via text, saturating the context window and thereby limiting the answer and question capacity.
Implementation and Fine-Tuning Details
Two modules are fine-tuned:
- The STC (spatial-temporal convolution) "connector" is updated with unrestricted parameter access.
- LoRA adapters (rank 128, scale 256, dropout 0.05) are placed on the LLM head with a uniform learning rate. The vision encoder remains frozen, leveraging its pretraining regime—a configuration that maximizes transfer from visual prompt engineering while minimizing potential catastrophic forgetting on non-object-centric distributions.
Each benchmarked video is uniformly sampled to 16 frames; trajectory trails are adaptively computed to span the number of frames between these samples. Lines are rendered using optimal settings of 3px for boxes and 2px for trails, balancing saliency and information occlusion, as confirmed by ablation studies.

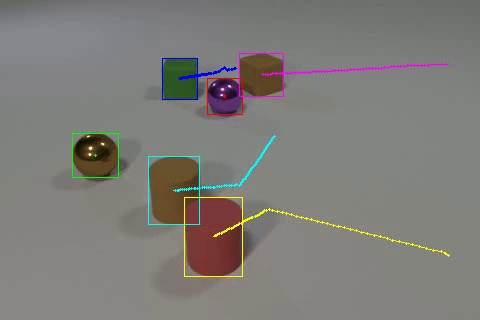
Figure 3: A single frame with only box overlays (Box only). Adding trajectory trails, not shown here, further increases temporal expressivity.
Experimental Results and Analysis
Token Efficiency and Context Utilization
Quantitative analysis across five diverse video QA benchmarks (CLEVRER, Perception Test, STAR, NExT-QA, IntentQA) reveals dramatic text token reductions—BoxTuning uses on average 88 text tokens per video (vs. 1,000 for ObjectMLLM), freeing context window resources for more substantive question/answer reasoning.
BoxTuning consistently matches or surpasses ObjectMLLM and other state-of-the-art MLLMs:
- CLEVRER: 78.5% (+0.9% vs. ObjectMLLM)
- Perception Test: 67.2% (+0.6%)
- STAR: 67.7% (+0.5%)
- NExT-QA: 79.7% (–0.1%)
- IntentQA: 76.5% (–0.2%)
On spatially oriented datasets, BoxTuning achieves top accuracy, evidencing the superior inductive bias of directly injected visual cues. On reasoning-centric tasks (NExT-QA, IntentQA), where bounding box context can crowd out critical QA tokens, BoxTuning narrows the performance gap to within 0.2% of the baseline (VideoLLaMA2) compared to ObjectMLLM’s significant regression (up to –1.3%).
Component and Hyperparameter Ablations
- Adding the color-text legend provides incremental accuracy across all tasks, confirming its utility as a class-disambiguation bridge.
- Adaptive trajectory length selection optimally encodes inter-keyframe dynamics, outperforming both short and excessively long trails.
- Box and trail line width ablations confirm that moderate thickness is essential for visual salience without undue occlusion.
Implications, Limitations, and Prospects
BoxTuning’s results emphasize the importance of modality-appropriate representations in MLLM design. By leveraging the vision backbone’s inductive priors for spatial pattern recognition, it enables dense, lossless transmission of object state and dynamics. The findings suggest that visually grounded object prompting is not only more efficient but also more compatible with the scale and granularity constraints of contemporary MLLM pretraining.
Theoretically, this prompts reconsideration of object-centric MLLM architectures: introducing anthropomorphic overlays (boxes, trails, arrows) as an explicit interface for not just detection outputs, but potentially any structured annotation (attributes, relationships, physical quantities). Practically, BoxTuning points toward efficient, user-editable debugging and annotation strategies for multimodal datasets, particularly in memory- or context-limited environments.
Potential future directions include:
- Extending visual prompting to non-bounding volume objects (e.g., masks, 3D bounding primitives).
- Adaptive trail encoding (curved or canonicalized templates) for non-linear motion.
- Integration with attention-sensitive architectural modifications to selectively fuse visual prompts with text queries.
- Exploration of prompt augmentation for compositional or multi-agent reasoning tasks.
Conclusion
BoxTuning (2604.11136) introduces a systematic paradigm shift in efficient object-centric video MLLM fine-tuning via direct visual injection of bounding boxes and motion trails. This strategy achieves order-of-magnitude improvements in token efficiency and eliminates artificial context bottlenecks induced by serialized text coordinates. The empirical results validate that visual prompts yield superior or at-par performance on spatially dense benchmarks and preserve reasoning generality elsewhere, setting the stage for further visually grounded innovations in multimodal modeling.