- The paper introduces explicit spatio-temporal grounding to address video reasoning limitations by pinpointing precise timestamps and spatial regions.
- It details a two-stage methodology that combines supervised fine-tuning on curated datasets with reinforcement learning using GSPO for optimized accuracy and alignment.
- Experimental results reveal significant gains in temporal and spatial grounding, boosting interpretability and overall performance on video QA benchmarks.
Open-o3 Video: Explicit Spatio-Temporal Grounding for Video Reasoning
Motivation and Problem Statement
The Open-o3 Video framework addresses a critical limitation in contemporary video reasoning models: the lack of explicit spatio-temporal grounding in their reasoning outputs. While prior models typically generate textual rationales, they fail to indicate the precise timestamps and spatial regions that constitute the supporting evidence for their predictions. This deficiency impedes interpretability, verifiability, and fine-grained reasoning, especially in dynamic and cluttered video scenes. The paper identifies two principal obstacles: (1) the absence of high-quality datasets providing joint spatio-temporal supervision, and (2) the challenge of training models to localize objects in both time and space with high precision.

Figure 1: Open-o3 Video integrates explicit spatio-temporal grounding into the reasoning process, highlighting key timestamps and object regions that directly support the answer.
Data Construction and Annotation Pipeline
To overcome the data bottleneck, the authors curate two complementary datasets: STGR-CoT-30k for supervised fine-tuning (SFT) and STGR-RL-36k for reinforcement learning (RL). These datasets combine existing temporal-only and spatial-only resources with 5.9k newly annotated high-quality spatio-temporal samples. Each instance includes a question-answer pair, timestamped key frames, localized bounding boxes, and a structured chain of thought linking visual evidence to reasoning steps.
The annotation pipeline leverages Gemini 2.5 Pro for initial annotation, followed by bounding box filtering and self-consistency checking. Noisy or uninformative boxes are removed, and object-box associations are validated using Qwen2.5-VL-7B. Consistency checks ensure that every entity mentioned in the reasoning chain is matched with a valid box and timestamp.
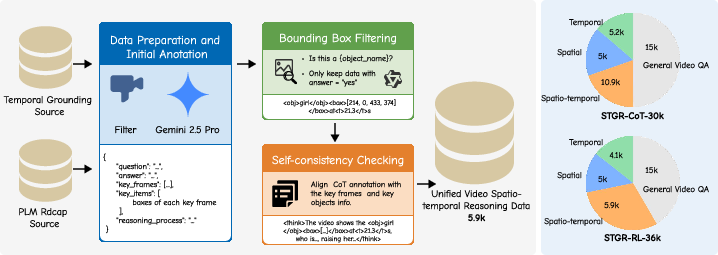
Figure 2: The data construction pipeline combines automated annotation, filtering, and consistency checking to produce balanced spatio-temporal supervision across temporal, spatial, spatio-temporal, and general QA categories.
Model Architecture and Training Paradigm
Open-o3 Video builds upon Qwen2.5-VL-7B and employs a two-stage training paradigm:
- Cold-Start Initialization: Supervised fine-tuning on STGR-CoT-30k equips the model with basic spatio-temporal grounding and structured reasoning output. This stage mitigates reward sparsity and stabilizes subsequent RL optimization.
- Reinforcement Learning with GSPO: The model is further optimized using Group Sequence Policy Optimization (GSPO), which operates at the sequence level, aligning optimization with sequence-level rewards and stabilizing long-horizon training. The composite reward function incorporates answer accuracy, temporal alignment, and spatial precision.
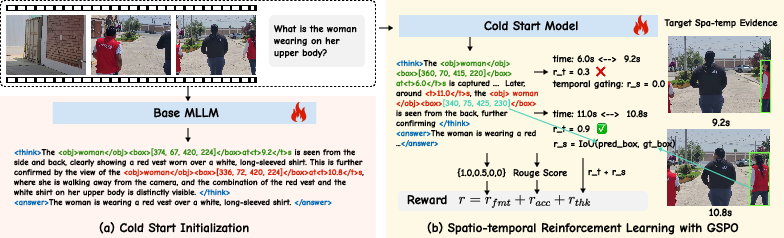
Figure 3: The two-stage training paradigm: (a) cold-start initialization for structured outputs; (b) RL with composite rewards, adaptive temporal proximity, and temporal gating.
Reward Design
- Accuracy Reward: Task-specific, using exact match for MCQ, ROUGE for free-form QA, visual IoU for spatial grounding, and temporal IoU for temporal grounding.
- Thinking Reward: Sum of temporal and spatial terms. Temporal reward uses adaptive temporal proximity, annealing the precision requirement over training to avoid reward sparsity. Spatial reward employs temporal gating, computing IoU only when temporal predictions are sufficiently accurate.
- Format Reward: Enforces strict usage of structured reasoning formats.
Experimental Results
Open-o3 Video is evaluated on V-STAR, VideoMME, WorldSense, VideoMMMU, and TVGBench. On V-STAR, it achieves state-of-the-art performance, surpassing GPT-4o and Qwen2.5-VL-7B by +14.4% mAM and +24.2% mLGM. The model demonstrates robust gains in temporal and spatial grounding, as well as general video QA and perception-oriented tasks.
Qualitative Analysis
Open-o3 Video provides explicit spatio-temporal evidence in its reasoning traces, enabling confidence-aware test-time scaling. By generating multiple responses with spatio-temporal traces and scoring the relevance of visual regions, the model supports confidence-weighted voting, which outperforms naive majority voting and improves inference reliability.

Figure 4: Confidence-aware test-time scaling leverages spatio-temporal traces for evidence relevance scoring and robust prediction selection.

Figure 5: On appearance perception tasks, Open-o3 Video provides correct answers and explicit spatio-temporal evidence, enhancing interpretability.

Figure 6: For action recognition, the model precisely localizes both the time and location of the action, outperforming Video-R1.

Figure 7: In weather reasoning, Open-o3 Video identifies more effective supporting evidence compared to related models.
Ablation Studies
Ablation experiments confirm the effectiveness of the two-stage training strategy, GSPO over GRPO, and the necessity of high-quality spatio-temporal annotations. Adaptive temporal proximity and temporal gating in the reward function are shown to be critical for coupling temporal and spatial grounding. The inclusion of curated spatio-temporal data yields substantial improvements in grounding metrics.
Implications and Future Directions
Open-o3 Video demonstrates that explicit spatio-temporal grounding is feasible and beneficial for video reasoning models. The framework enhances interpretability, verifiability, and robustness, providing a foundation for evidence-aware inference and scalable test-time strategies. The results suggest that future research should focus on extending spatio-temporal grounding to longer and more complex videos, integrating audio modalities, and developing richer supervision for fine-grained object localization.
Conclusion
Open-o3 Video presents a unified framework for grounded video reasoning, generating explicit spatio-temporal evidence through timestamped frames and localized bounding boxes. The combination of curated data, structured annotation, and GSPO-based RL yields substantial improvements in answer accuracy, temporal alignment, and spatial grounding. The approach sets a new standard for interpretable and verifiable video reasoning, with broad implications for multimodal AI systems.