- The paper introduces a novel query-guided visual token sampling module to enhance video temporal grounding in multimodal LLMs.
- It employs a differentiable top-K masking with STE and Gumbel-Softmax relaxation for adaptive, token-level selection based on query relevance.
- Experimental results demonstrate significant gains on benchmarks, with improved token efficiency and precise temporal localization.
GroundVTS: Query-Guided Visual Token Sampling for Video Temporal Grounding
Motivation and Problem Statement
The paper "GroundVTS: Visual Token Sampling in Multimodal LLMs for Video Temporal Grounding" (2604.02093) addresses the challenge of Video Temporal Grounding (VTG) in Vid-LLMs. VTG requires precise localization of video segments that correspond to natural-language queries, demanding fine-grained temporal understanding. Existing Vid-LLMs typically utilize uniform frame sampling, distributing input across time without consideration for query-specific relevance, which results in dilution or even omission of salient temporal cues.
Prior works have attempted coarse query-guided frame selection, often relying on external encoders for similarity estimation. Such methods are limited in granularity and adaptability, hindering accurate temporal localization.
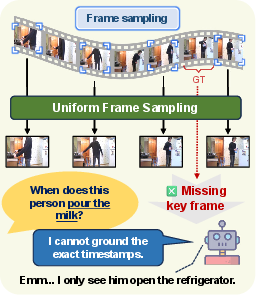
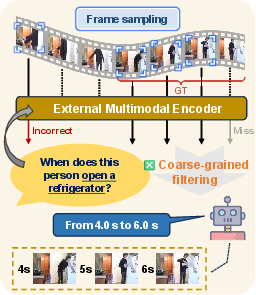
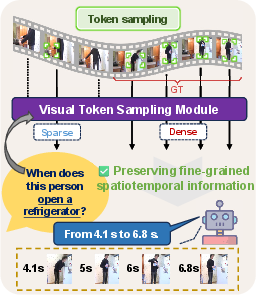
Figure 1: Schematic comparison of frame sampling strategies: uniform sampling, external encoder-based query-guided sampling, and GroundVTS’s internal token-level query-guided sampling.
Methodology: Grounded Visual Token Sampling
GroundVTS introduces a differentiable, query-guided Visual Token Sampling (VTS) module integrated into the Vid-LLM pipeline, post visual encoding and multimodal projection. The VTS module evaluates visual token-query relevance at the token level by projecting visual features and query embeddings into lower-dimensional subspaces and computing temperature-scaled dot-product similarity. This produces a relevance distribution over visual tokens.
To select the most informative tokens, GroundVTS employs a differentiable top-K masking operation using Straight-Through Estimator (STE) with Gumbel-Softmax relaxation. This enables end-to-end learning and adaptive, query-specific selection of visual content. Spatial and temporal position encodings are retained only for selected tokens, preserving coherence for token-based temporal reasoning.
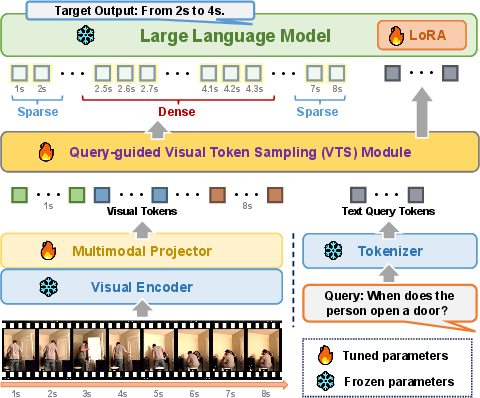
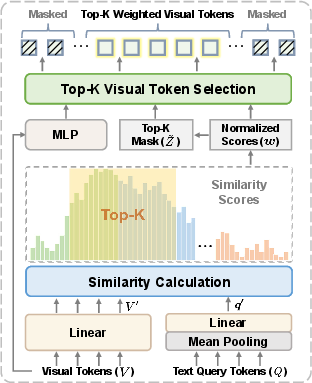
Figure 2: GroundVTS architecture illustrating multimodal input processing, VTS module, and token selection pipeline.
Training and Optimization Strategy
A three-stage progressive optimization strategy facilitates stable and effective integration of VTS:
- VTS Warm-Up: The VTS module is trained in isolation with all other components frozen, establishing stable query-conditioned token selection.
- Joint LoRA Adaptation: Fine-tuning of both VTS and multimodal projector, and adaptation of the LLM via Low-Rank Adaptation (LoRA), leveraging large-scale multimodal video instruction datasets.
- Grounding Fine-Tuning: Final stage fine-tuning on a unified VTG dataset (Grounding-FT) constructed by reformulating expert VTG datasets into instruction-style QA pairs, promoting generalizable temporal grounding and reasoning.
Frame Rate Sensitivity Analysis
A preliminary study reveals that VTG performance in Vid-LLMs depends non-linearly on visual token density. When sampling is sparse, temporal cues are lost; when too dense, redundant tokens dilute signal quality and degrade accuracy. Peak performance is observed at an optimal sampling density, motivating adaptive mechanisms for token selection.
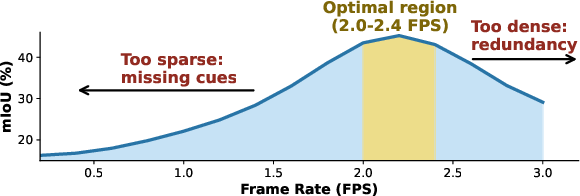
Figure 3: Analysis of Qwen2.5VL-7B frame rate sensitivity demonstrates optimal performance at moderate visual token density.
Experimental Results
GroundVTS exhibits substantial improvements in VTG benchmarks. For moment retrieval on Charades-STA, GroundVTS-Q achieves +24.8 [email protected] and +18.4 mIoU over the Qwen2.5VL-7B-G baseline, reaching 57.5 [email protected] and 50.1 mIoU. Similar gains are reported on ActivityNet-Captions and QVHighlights, including highlight detection where GroundVTS-I improves mAP and Hit@1 by significant margins.
Ablation studies show that token-level sampling and the retention of position encodings are essential for performance. Uniform or random sampling severely degrades accuracy, and removal of positional encoding collapses VTG results. Furthermore, GroundVTS maintains high grounding accuracy and token efficiency across a wide range of input densities, outperforming baselines even under sparse sampling conditions.
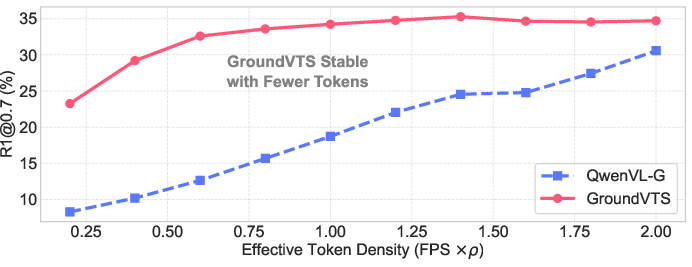
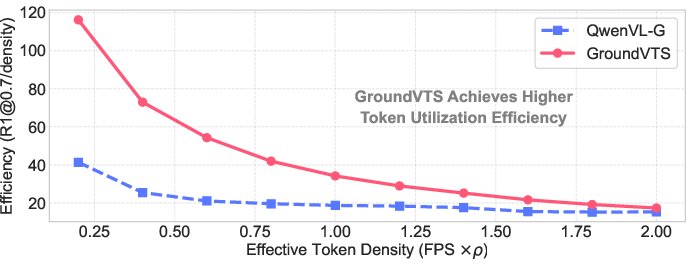
Figure 4: Impact of visual token density on VTG performance (top) and token efficiency (bottom), demonstrating GroundVTS's stability and robustness.

Figure 5: Qualitative comparison illustrating temporal grounding predictions: GroundVTS-Q aligns token density peaks with ground-truth intervals, outmatching baseline models.
Theoretical and Practical Implications
GroundVTS advances temporal grounding in Vid-LLMs by moving token selection into the LLM pipeline, enabling efficient, query-aware, non-uniform allocation of visual evidence. This mechanism achieves both high precision and robustness, mitigating sensitivity to input density and supporting practical VTG tasks across diverse temporal structures. Its progressive optimization ensures compatibility and stable adaptation in instruction-tuned Vid-LLMs.
Theoretical implications include the importance of token-level relevance modeling and the necessity of temporal positional encoding. GroundVTS’s differentiable sampling strategy opens avenues for efficient long-video reasoning and further exploration into multi-stage or iterative token selection architectures.
Future Directions
Potential future advances include multi-stage token sampling exploiting deeper cross-modal semantics, scaling GroundVTS for hour-long videos, and expanded assessment on broader multimodal tasks. Integration with other token compression or pruning paradigms may yield additional efficiency gains. Research into interpretability and transparency of token selection could provide further insight into grounded video-language reasoning.
Conclusion
GroundVTS provides a principled, query-guided visual token sampling framework, integrated via a progressive optimization strategy for VTG in Vid-LLMs. Its VTS module enables fine-grained, robust temporal grounding, outperforming current state-of-the-art methods and demonstrating resilience across input densities and out-of-distribution settings. This establishes GroundVTS as an effective solution for practical and theoretical challenges in video-language modeling.