- The paper introduces Archer, an entropy-aware RLVR approach that applies differentiated constraints to preserve factual knowledge while stimulating reasoning.
- It employs synchronized training with tailored clipping thresholds and KL regularization, leading to significant gains on mathematical reasoning and code generation benchmarks.
- Ablation studies demonstrate that fine-tuning token-specific parameters is crucial for enhancing performance while maintaining semantic integrity.
Entropy-Aware Dual-Token Constraints for RLVR
The paper "Stabilizing Knowledge, Promoting Reasoning: Dual-Token Constraints for RLVR" (2507.15778) introduces Archer, an entropy-aware RLVR approach designed to improve the reasoning abilities of LLMs. The key idea is to apply differentiated training constraints to knowledge-related (low-entropy) and reasoning-related (high-entropy) tokens during RLVR training. This approach aims to preserve factual knowledge while encouraging exploration and learning of logical patterns, leading to improved performance on mathematical reasoning and code generation tasks.
Background and Motivation
RLVR has shown promise in enhancing the reasoning abilities of LLMs. However, prior RLVR algorithms often apply uniform training signals to all tokens, disregarding the distinct roles of low-entropy and high-entropy tokens. Recent studies suggest that RL mainly improves reasoning by better integrating existing model abilities, with high-entropy tokens acting as logical connectors and low-entropy tokens capturing factual knowledge. Existing methods that attempt to separate these token types through gradient masking or asynchronous updates may disrupt semantic dependencies within the model output, hindering effective learning.
Archer: Dual-Token Constraints
To address the limitations of previous approaches, the paper proposes Archer, a synchronized, entropy-aware framework for differentiated token training. Archer employs a response-level entropy criterion to classify tokens into knowledge-related and reasoning-related types. Unlike methods that use masking or asynchronous updates, Archer synchronously updates all tokens but applies dual-token constraints:
- Reasoning Tokens: Higher clipping threshold and weaker KL regularization to encourage exploration and learning of logical patterns.
- Knowledge Tokens: Lower clipping threshold and stronger KL regularization to maintain factual accuracy.
The overall objective function is formulated as:
$\begin{aligned}
\mathcal{J}_{\text{TDPO}(\theta) = &\ \mathbb{E}_{(q, a) \sim \mathcal{D}, \{o^i\}_{i=1}^G \sim \pi_{\theta_{\text{old}(\cdot \mid q)} \Bigg[ \frac{1}{\sum_{i=1}^G |o^i|} \sum_{i=1}^G \sum_{t=1}^{|o^i|} \
& \bigg( \min\left( r_t^i(\theta) \hat{A}_t^i, \operatorname{clip}\big( r_t^i(\theta), 1-\textcolor{red}{\varepsilon(e_t^i)}, 1+\textcolor{red}{\varepsilon(e_t^i)} \big) \hat{A}_t^i \right) - \textcolor{red}{\beta(e_t^i)} \mathbb{D}_{\text{KL}(\pi_\theta \| \pi_{\text{ref}) \bigg) \Bigg] \
&\ \text{s.t.} \quad 0 < \left| \left\{ i \in \{1, \ldots, G\} \mid is\_equivalent(o^i, a) \right\} \right| < G, \end{aligned}$
where ε(eti) and β(eti) represent the differentiated clipping and KL constraints based on token entropy.
Experimental Results
The authors evaluate Archer on mathematical reasoning and code generation benchmarks. The experiments demonstrate that Archer achieves significant performance improvements across different tasks. Specifically, Archer outperforms the standard DAPO algorithm [DAPO], achieving gains of +6.6 Pass@1 on AIME24, +5.2 on AIME25, +3.4 on LiveCodeBench v5, and +2.6 on LiveCodeBench v6. Furthermore, Archer achieves SOTA performance on both mathematical and coding benchmarks compared to RL-trained models with the same base model. (Figure 1) shows the overall performance on mathematical reasoning and code generation benchmarks, demonstrating that Archer significantly improves reasoning performance.
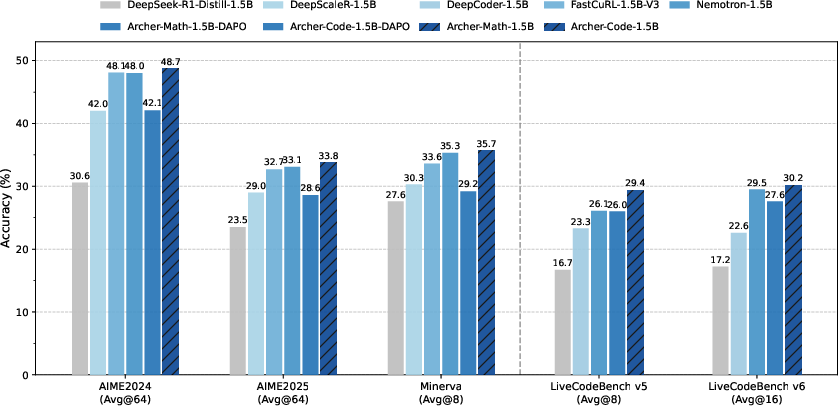
Figure 1: Overall performance on mathematical reasoning and code generation benchmarks. Archer significantly improves the reasoning performance upon DAPO and outperforms previous 1.5B-level SOTA reasoning models.
Analysis and Ablation Studies
The paper includes a detailed analysis of the impact of KL weights and clip ranges on model performance. Ablation studies reveal that:
- Both the absence of KL regularization and an excessively high KL weight reduce performance.
- Adjusting the clip threshold for low-entropy tokens significantly affects training and final performance.
- The model is less sensitive to changes in the clip threshold for high-entropy tokens, although increasing it can lead to slightly faster entropy reduction and improved performance in later training stages.
A visualization of PPO clip regions (Figure 2) illustrates how Archer extends the clipping boundaries for high-entropy tokens, increasing the model's focus on learning reasoning-critical tokens.
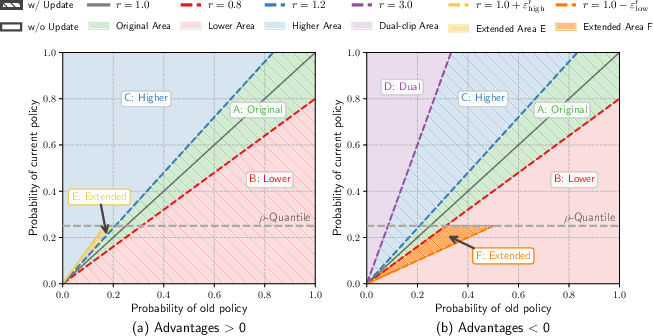
Figure 2: Visualization of PPO clip regions. The x-axis shows the sampled probability of a specific token $\pi_{\theta_\text{old}$.
Additionally, the paper explores the mutual enhancement between math RL and code RL, finding that RL training in either domain leads to performance improvements in the other. The analysis suggests that performance improvements correlate more strongly with the intrinsic difficulty of the problems rather than their topical categories and that the improvements are primarily due to enhanced reasoning capabilities.
Implementation Details
The RL training is performed using the verl framework [verl]. The base model is DeepSeek-R1-Distill-Qwen-1.5B. For DAPO-based baselines, clipping thresholds of $\varepsilon_{\text{low} = 0.2$ and $\varepsilon_{\text{high} = 0.28$ are used. For Archer, the quantile level is set to ρ=0.8. Clipping ranges and KL coefficients are set to εr=0.5, εk=0.2, $\beta^{\text{r}=0.0$, and $\beta^{\text{k}=0.001$. All experiments are conducted on compute nodes equipped with NVIDIA H800 GPUs.
The paper discusses related work in reinforcement learning for LLMs and critical token analysis in RL for reasoning. It highlights the limitations of previous approaches that apply uniform training signals or isolate low-entropy tokens, and it contrasts Archer with these methods by emphasizing its joint training approach with differentiated training constraints.
Conclusion
The paper concludes that Archer, with its entropy-aware dual-token constraints, effectively balances the goals of preserving factual accuracy and improving logical reasoning. The experimental results and analysis suggest that coordinating the learning processes of different token types through entropy-aware constraints improves the reasoning abilities of LLMs. The authors suggest future research directions for fine-grained, token-level optimization strategies that respect the inherent structural dependencies in natural language generation.

