- The paper introduces ScoRe-Flow, which achieves decoupled mean-variance control by leveraging a closed-form score for drift modulation in Flow Matching policies.
- It reformulates action updates as an SDE with learnable variance, yielding 2.4× faster convergence and enhanced stability across diverse robotics benchmarks.
- The approach offers scalable, real-time deployment benefits while highlighting the need to extend beyond linear-path, Gaussian settings for broader applicability.
ScoRe-Flow: Complete Distributional Control via Score-Based RL for Flow Matching
Introduction and Motivation
This work proposes ScoRe-Flow, an RL fine-tuning framework for Flow Matching (FM) policies that achieves complete, decoupled control over the mean and variance of the policy's stochastic action distribution. FM policies, which parameterize the transformation from Gaussian noise to actions via ODE-driven velocity fields, have established themselves as a cornerstone in recent robotic control architectures thanks to their superior sampling efficiency compared to diffusion-based approaches. However, existing FM policies, typically initialized with imitation learning, are fundamentally limited by their reliance on demonstration data and are unable to surpass the inherent suboptimality in these datasets without effective online RL fine-tuning.
A key bottleneck arises from the deterministic nature of traditional FM: their forward trajectories are Dirac measures, precluding well-defined action log-likelihoods and complicating direct policy gradient optimization. Previous RL fine-tuning approaches, such as ReinFlow, convert FM ODEs into SDEs by injecting learnable noise, but these methods only modulate state variance while leaving the drift dynamics unaffected. This work identifies that such noise-only control lacks geometric guidance for efficient exploration, especially when demonstration priors already localize the relevant subset of the action distribution.
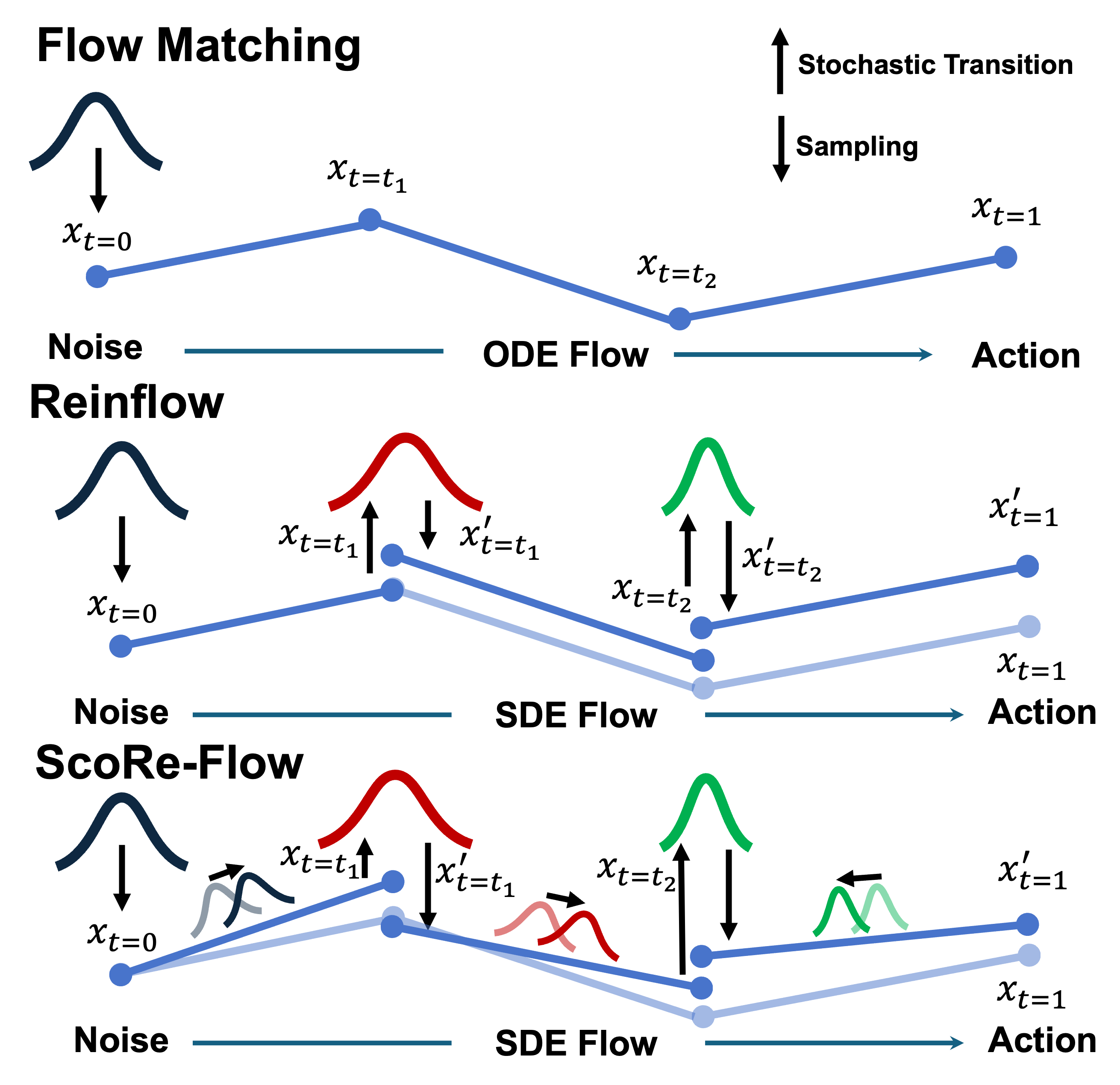
Figure 1: A comparison of flow policy sampling strategies. ScoRe-Flow (bottom) achieves decoupled mean-variance control by combining score-based drift modulation with learned variance prediction.
Methodology
The core technical insight is that, for linear interpolation FM with Gaussian prior, the gradient of the action marginal likelihood (score function) admits a closed-form in terms of the velocity field. Specifically, for at sampled along the FM path,
st(a)=1−ttvθ(t,a,s)−a,
which is efficiently computable for any learned FM velocity field. This score points toward the high-likelihood regions of intermediate marginals, providing a principled direction for drift modulation—offering targeted geometric guidance distinct from isotropic noise injection.
Practical FM policies for robotic control predominantly use linear paths from Gaussian noise, so this result has widespread applicability. Numerical stability is ensured by introducing a time-dependent decay envelope on the score scaling parameter α(t), mitigating the divergence at t→1.
ScoRe-Flow formulates the action update as an SDE:
dat=[vθ(t,at,s)+αψscaled(t)⋅st(at)]dt+σϕ(t,at,s)dWt,
where the mean (drift) comprises both the FM velocity and a learnable, time-attenuated score modulation, while σϕ is an independent, state-conditional variance predictor. This structure enables the policy to separately adapt (1) the exploratory direction and concentration (via score), and (2) the overall exploration magnitude (via variance), overcoming the limitations of both noise-only (isotropic, undirected) and score-only (drift/diffusion coupled) frameworks.
Efficient Likelihood and PPO-based Fine-tuning
Trajectory likelihoods decompose analytically using the discretized SDE update, supporting direct PPO optimization. All model components, including the FM velocity, score scheduler, and variance predictor, are jointly fine-tuned with PPO to maximize expected return. The parametric complexity for the additional scheduler is negligible relative to the full policy.
Empirical Evaluation
Benchmark Domains
ScoRe-Flow is compared against ReinFlow, DPPO (diffusion policy PPO), FQL, Score-SDE ablations, and others across:
- D4RL locomotion (Hopper-v2, Walker2d-v2, Ant-v0, Humanoid-v3)
- Robomimic visual manipulation (PickPlaceCan, Square, Transport)
- Franka Kitchen (multi-task manipulation, sparse reward)
Main Results
ScoRe-Flow consistently offers 2.4× faster convergence than the best flow-based SOTA (ReinFlow) for matched denoising steps, and outperforms on final task return/success metrics in almost every task, especially in scenarios requiring long-horizon reasoning or high-dimensional visual observations.
- D4RL: Achieves the highest reward on Humanoid-v3 and robustly matches or surpasses ReinFlow on all other locomotion tasks.
- Robomimic: Demonstrates higher or competitive success rates—over 98% on PickPlaceCan and leading performance on multi-step manipulation settings.
- Franka Kitchen: Reaches perfect completion (4/4 subtasks) on the hardest instance, significantly outperforming ReinFlow on the partial (sparse) regime.
Contradictory to prior literature, the study demonstrates that decoupled mean-variance control significantly improves both training stability and asymptotic performance relative to variance-only (ReinFlow) or rigidly coupled score-controlled SDEs.
Efficiency Analysis
ScoRe-Flow retains the computational benefits of FM, requiring only 2–4 denoising steps (vs. 50–100 for DPPO), yielding up to 94× wall-clock speedup for real-time tasks.

Figure 2: Wall-clock time comparison. ScoRe-Flow achieves a substantial speedup via few-step sampling and faster PPO convergence over flow-based and diffusion-based baselines.
Training Stability
The introduction of score-based drift yields markedly improved training stability. Unlike ReinFlow, which exhibits high-variance and occasional collapse especially in sparse-reward or long-horizon domains, ScoRe-Flow maintains consistent monotonic improvement.
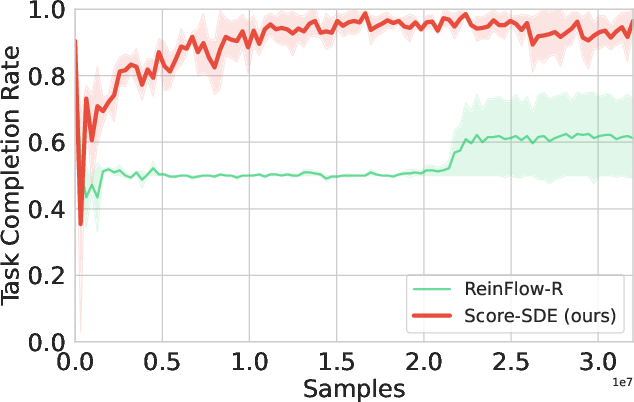
Figure 3: ScoRe-Flow maintains stable convergence on Kitchen-Complete-v0, in contrast to noisy and unstable ReinFlow trajectories.
Ablation: Importance of Decoupling
Learned variance prediction is critical—for score-only SDEs with fixed noise schedules, performance exhibits high sensitivity to the chosen σ, requiring careful per-task tuning and suffering from inability to adapt to environment stochasticity.
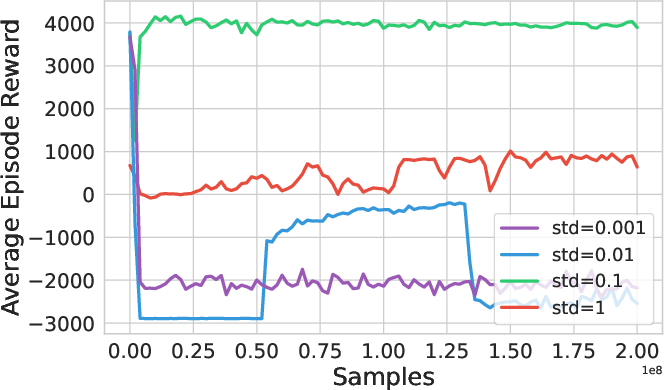
Figure 4: Score-SDE is highly sensitive to the initial noise variance hyperparameter, underscoring the need for a learnable variance predictor.
ScoRe-Flow's flexibility in scheduling both drift and variance, with their decoupling, is responsible for the observed empirical gains.
Theoretical and Practical Implications
The study elevates the role of score-based drift modulation for efficient RL fine-tuning in FM-based policies. The analytic score construction, enabled by probability geometry, offers a low-overhead mechanism to steer exploration toward high-probability regimes, enhancing both sample efficiency and robustness.
Decoupled mean-variance control allows policies to adaptively balance exploration and exploitation—critical for challenging tasks where naive isotropic policies either diverge or underexplore. The approach also provides a unifying perspective on flow- and diffusion-based generative policies for RL, connecting recent advances in score-based modeling and controlled SDE sampling.
Practically, this enables scalable online RL fine-tuning in state-of-the-art robot control stacks that rely on FM or related stochastic interpolant architectures. The method's computational frugality (relative to diffusion models) makes it suitable for real-time and large-scale deployment in both state and pixel observation settings.
Limitations and Future Directions
The analytic drift modulation is currently restricted to the linear-path, Gaussian FM setting. For non-Gaussian source distributions or nonlinear flow trajectories (e.g., Riemannian FM), the closed-form score is inaccessible, necessitating approximate or learned scorers, potentially losing the no-auxiliary-network property. Extending the approach to these scenarios remains an open theoretical and practical problem.
Moreover, while the results are robust across a suite of control benchmarks, further investigation is warranted regarding the interaction of drift modulation with other RL objectives (such as entropy maximization), integration into hybrid value/policy architectures, and its effectiveness in settings with heavy covariate shift or adversarial dynamics.
Conclusion
ScoRe-Flow establishes a new paradigm for RL fine-tuning of FM policies in robotics and continuous control. By leveraging a closed-form, velocity-field-derived score for drift modulation and pairing it with adaptive variance scheduling, the method realizes complete, independently tunable control over the action distribution's mean and variance. This yields substantial improvements in convergence speed, final reward, and stability compared to both prior art and strong ablations. The work settles the open question of the empirical and theoretical advantages of geometric guidance in flow-based RL and suggests new directions for future FM, diffusion, and stochastic interpolant algorithms in embodied AI.
References
See the full bibliography section in the original document for a comprehensive list of related works and baseline implementations.