- The paper demonstrates that implementation errors in PPO cause severe generalization issues, marked by a win rate collapse from 73.5% to 21.6%.
- The study uses a controlled Unity environment to isolate and ablate errors in reward scaling, credit assignment, and observation normalization.
- The introduction of opponent mixing mitigates competitive overfitting, restoring and enhancing generalization performance with minimal intervention.
Diagnosing and Mitigating Failure Modes in Competitive Multi-Agent PPO with Territory Paint Wars
Introduction
The paper "Territory Paint Wars: Diagnosing and Mitigating Failure Modes in Competitive Multi-Agent PPO" (2604.04983) investigates the specific failure modes of Proximal Policy Optimization (PPO) under self-play in competitive multi-agent reinforcement learning (MARL). By introducing Territory Paint Wars—a deterministic, zero-sum, two-agent environment implemented in Unity—the study methodically isolates and corrects compounding implementation-level pathologies that undermine learning efficacy. The work further exposes and resolves emergent competitive overfitting, a phenomenon where agents maintain balanced self-play metrics yet collapse in generalisation performance vs. out-of-distribution opponents.

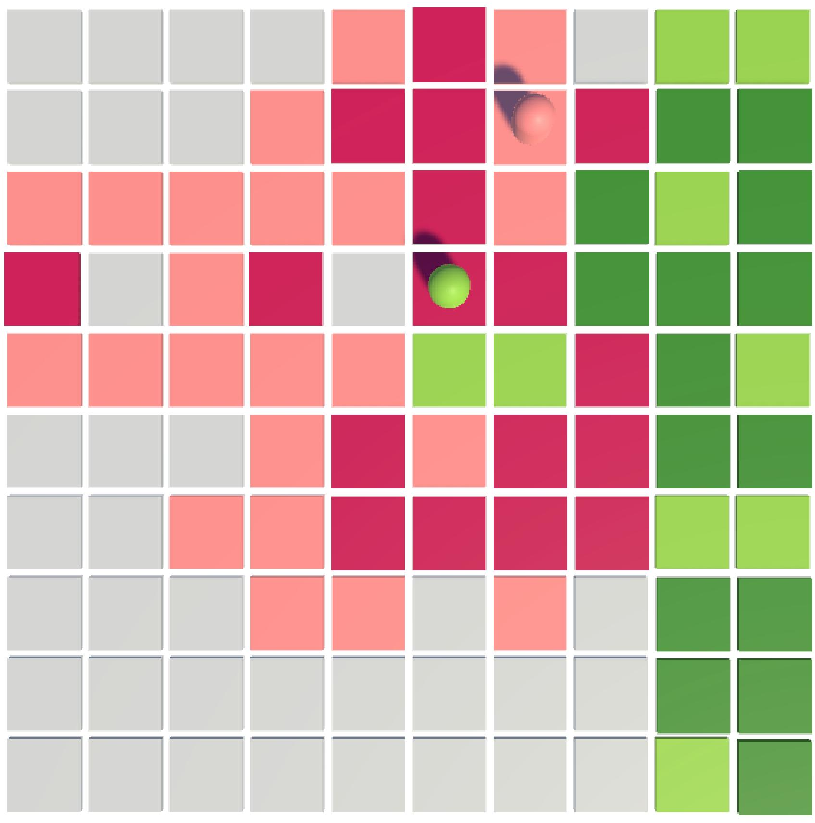
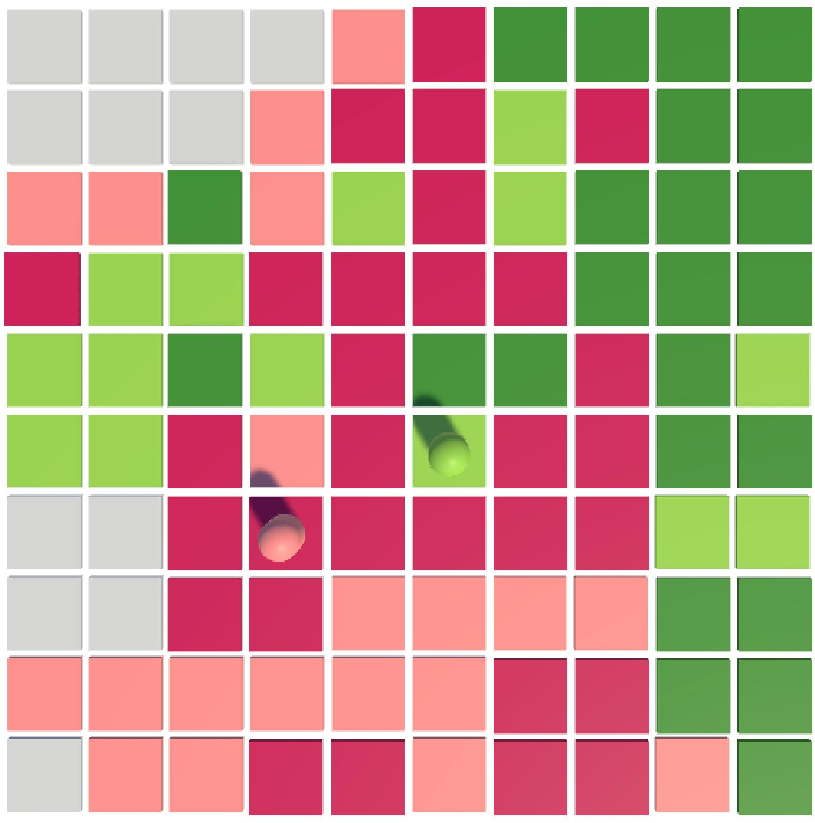
Figure 1: Territory Paint Wars environment on a 10×10 grid, showing initial, mid-game, and final board states with agent and territory control.
Environment and Game Mechanics
Territory Paint Wars is a minimalistic grid-based competitive environment specifically designed to facilitate reproducible, systematic investigation of multi-agent RL algorithms. Two agents (Pink, Green) alternate moves on a 10×10 board. Actions comprise cardinal movement and locking tiles, inducing irreversible territory control and deeper strategic commitments. Raw observations include positional encoding, board states, lock masks, step counts, and a padding element—forming a 206-dimensional input vector. Action set is discrete, with direct consequences for territory dynamics and episode outcomes.
Empirical fairness validation demonstrates unbiased win rates in 1,000 random-vs-random games (50.0±0.5% per agent), confirming environmental symmetry and suitability for competitive analysis.
Failure Modes in Vanilla Multi-Agent PPO
Initial experiments with a baseline PPO implementation yielded only 26.8% win rate versus a uniformly random policy after 84,000 episodes, markedly worse than chance. Systematic ablation and correction revealed five distinct implementation-level errors:
- Absence of terminal reward: No propagation of win/loss signal at episode termination.
- Reward-scale imbalance: Cumulative lock reward amplification (±10,000 per episode), swamping subtle signals (tile gain and terminal).
- Ineffective credit assignment: Monte Carlo returns (γ=0.99, T=250) discount early-step advantages (≈0.08) to insignificance.
- Unnormalized observations: Raw positional and step-count features dominate board-state gradients, destabilizing learning.
- Incorrect win detection: Episode rewards used for winner determination, confounded by reward-scale errors.
Each fix contributed non-redundantly, with GAE, observation normalization, and opponent mixing found to be individually critical: ablation of any single element degrades performance below the v1 baseline.
Emergence and Characterization of Competitive Overfitting
After correcting all implementation issues, self-play agents initially achieved 73.5% win rate against a random opponent (episode 8,000), but subsequent training caused a collapse to 21.6% by episode 12,000. This emergent pathology—competitive overfitting—was not detectable via self-play win rate monitoring, as both agents co-adaptively maintained near-50\% mutual win rates throughout. The Nash equilibrium formed between overly specialized policies failed to generalize.
(Figure 2)
Figure 2: Competitive overfitting: Generalisation win rate vs random opponent collapses, whereas self-play win rate remains stable, revealing monitoring failure.
Periodic external evaluation against fixed baselines is necessary to diagnose such failures, as standard monitoring is demonstrably inadequate.
Mitigation via Opponent Mixing
Competitive overfitting was resolved through opponent mixing: substituting a uniformly random policy for the co-adaptive opponent in 20% of training episodes (10×100). This intervention—a single-line change—forces agents to maintain strategies robust to out-of-distribution behaviour, preventing hyper-specialization and collapse.
Generalisation win rate recovered to 10×101 across 10 seeds, with peak individual performance reaching 10×102. This approach obviates population-based strategies such as PFSP or league play, incurring no infrastructure overhead and maintaining algorithmic minimality.
(Figure 3)
Figure 3: Bar chart progression of generalisation win rates: v1 (26.8%), v2 peak (73.5%), v2 post-collapse (21.6%), v3 mean (77.1%), v3 best (93.9%), illustrating collapse and recovery.
Criticality of GAE and Observation Normalisation
Ablation studies further established that GAE (10×103) is indispensable for long-horizon competitive tasks: plain MC returns provide negligible gradient support for early-game strategy. Removal of GAE reduced win rate to 10×104. Observation normalisation is equally vital, with ablated agents exhibiting high apparent self-play performance (10×105) but only 10×106 generalisation win rate—demonstrating accelerated and catastrophic overfitting. Terminal reward, in contrast, was found to be complementary; removal reduced generalisation by only 10×107pp relative to the best single seed, indicating that dense step rewards suffice for learning provided other critical elements are present.
Training Diagnostics and Convergence Analysis
Across 10 seeds, PPO+GAE agents with opponent mixing converged to high generalisation rates, with explained variance and policy entropy curves confirming critic learning and policy specialization. The wide variance in convergence speed reflects genuine training dynamics, not model pathology.
(Figure 4)
Figure 4: Rolling-100 self-play win rates across seeds demonstrate persistent oscillation and steady cumulative improvement with opponent mixing.
(Figure 5)
Figure 5: Policy entropy and critic explained variance over 12,000 episodes: entropy decreases with specialization; explained variance increases, validating critic reliability.
Discussion and Implications
The study provides a formal taxonomy of failure modes in competitive MARL settings, clarifying the interaction between implementation and emergent pathologies. The competitive overfitting phenomenon, shown to be invisible to standard metrics, calls for a re-examination of self-play monitoring protocols. The discriminative ablation results underscore the necessity of GAE and observation normalization alongside opponent diversity maintenance for robust generalisation. The minimal intervention design of opponent mixing offers practical advantages for practitioners seeking scalable, reproducible solutions.
Implications extend to theoretical analyses of competitive equilibria and generalisation in MARL. The findings reinforce the need for policy evaluation against diverse baselines and favour lightweight architectural changes over more complex population-based schemes. Future work could investigate transferability to stochastic and larger-scale environments, or integrate additional mechanisms for diversity regularization.
Conclusion
The paper systematically diagnoses and remedies compounding PPO failures in a competitive Unity environment, culminating in the exposure and mitigation of competitive overfitting. Opponent mixing restored generalisation without infrastructure expansion, and the criticality of GAE and observation normalization was validated through ablation. The research establishes Territory Paint Wars as a reproducible benchmark for competitive MARL and provides actionable guidelines for algorithmic design and monitoring in self-play training regimes. The primary empirical contribution is the clear demonstration that self-play win rates are insufficient and can conceal profound failures in generalisation, necessitating periodic external evaluation and architectural interventions that promote opponent diversity.

