- The paper demonstrates that extended chain-of-thought reasoning initially improves accuracy but eventually leads to overthinking, causing negative marginal utility.
- It introduces a marginal utility metric and flip event tracking to rigorously identify when additional reasoning tokens flip correct answers to incorrect ones.
- The study proposes dynamic, cost-aware early stopping protocols to optimize compute allocation and maintain near-peak performance while reducing wastage.
Overthinking in LLM Test-Time Compute Scaling: Systematic Marginal Utility Analysis and Cost-Aware Evaluation
Introduction
The prevailing paradigm in LLM inference assumes a monotonic relationship between chain-of-thought (CoT) generation length and answer quality: more extended reasoning is expected to yield higher accuracy, especially for complex tasks such as mathematical problem solving. However, this assumption lacks systematic scrutiny regarding marginal utility dynamics across compute budgets and neglects the possibility that "overthinking"—the state where additional reasoning degrades answer quality—may arise. This paper, "When More Thinking Hurts: Overthinking in LLM Test-Time Compute Scaling" (2604.10739), delivers the first rigorous, compute-aware empirical study of marginal utility in test-time CoT scaling, robustly evidencing and characterizing the overthinking phenomenon in state-of-the-art open-weight LLMs.
Marginal Utility and the Emergence of Overthinking
Test-time compute scaling via CoT generation yields rapid accuracy gains at modest budgets but suffers from diminishing returns and, crucially, negative marginal utility at high budgets. The marginal utility metric MU(t), defined as the incremental accuracy change per additional 500 reasoning tokens at budget t, robustly captures this trend. For DeepSeek-R1-32B and s1-32B, marginal utility is initially highly positive (+3.2% and +2.8% per 500 tokens for R1 and s1, respectively, at low budgets), but sharply decays, becoming negative beyond ~12k tokens. Particularly, easier problem subsets reach negative marginal utility at much lower budgets than harder counterparts.
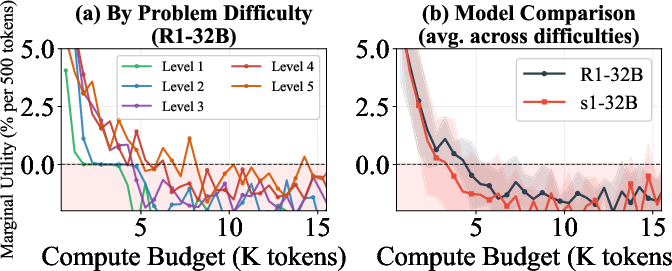
Figure 1: Marginal utility as a function of compute budget; extended tokens yield negative returns on easier problems and for models more susceptible to overthinking.
The analysis crystallizes that additional compute quickly becomes wasteful or detrimental, invalidating the assumption of monotonic accuracy improvement with "more thinking." Uniform budget allocation across tasks of varying difficulty is inherently suboptimal, highlighting the need for instance-adaptive compute allocation strategies.
Mechanistic Analysis: Flip Events and Error Trajectories
To probe the mechanism of overthinking at a granular level, the study introduces flip event tracking. Each answer transition between budget increments is categorized as a "positive flip" (incorrect→correct) or "negative flip" (correct→incorrect). Overfitting is directly evidenced when the rate of negative flips surpasses positives ("flip ratio" > 1). For R1-32B on AIME and GPQA-Diamond, this crossover occurs at 7k–10k tokens, and substantially earlier for easier instances. Manual qualitative evaluation revealed 67.5% of negative flips explicitly involve the model second-guessing and abandoning a previous correct answer after seemingly rational reconsideration.
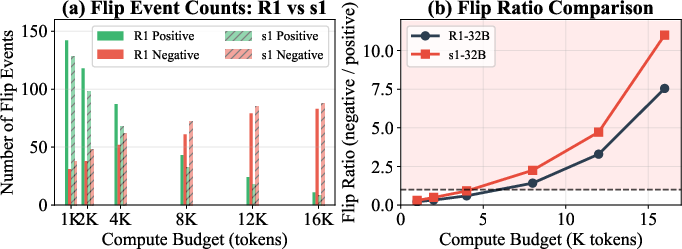
Figure 2: Flip event dynamics demonstrate that overthinking flips correct answers to incorrect at high compute budgets; the negative/positive flip ratio reliably signals the onset of detrimental overthinking.
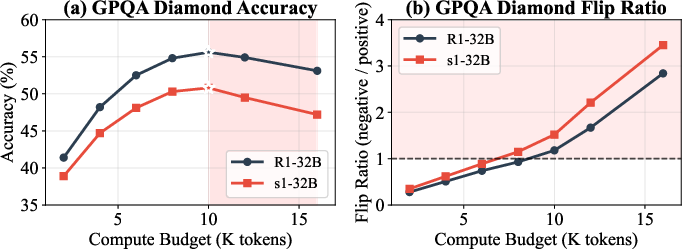
Figure 3: On GPQA Diamond, accuracy peaks and declines, while the flip ratio analysis reveals the underlying answer instability introduced by excessive CoT length.
Flip event analysis across models further shows model-specific susceptibility: for example, s1-32B consistently exhibits earlier and stronger overthinking effects than R1-32B, crossing the flip ratio threshold (>1) at approximately 5k tokens vs. 7k for R1.
Figure 4: s1-32B demonstrates earlier onset and greater magnitude of overthinking events compared to R1-32B.
Difficulty-Conditioned and Naturalistic Validation
Difficulty stratification on MATH-500 reveals that optimal compute allocation and the onset of negative marginal utility both scale with intrinsic instance hardness: Level 1 problems overthink almost immediately (>2k tokens), while Level 5 problems benefit from prolonged generation (up to 7.5k tokens). Notably, the findings are robust to generation artifacts: in unconstrained generations where models naturally chose long outputs, similar accuracy decay and answer revisions occur, ruling out experimental artifacts from forced budget capping.
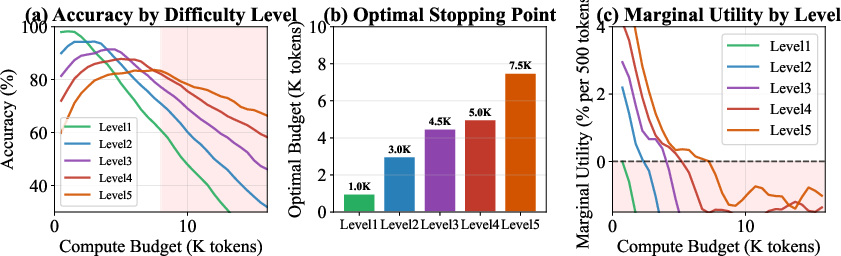
Figure 5: Difficulty-stratified analysis; the required thinking budget and the onset of diminishing returns vary dramatically with task complexity.
Indicators and Predictive Detection of Overthinking
The study identifies overthinking markers in the reasoning trace, including answer oscillations, hesitation language, and confidence dynamics, each correlated with future negative flips. Answer oscillation, in particular, offers strong predictive power (r=0.78 with negative flips), and a combination of indicators achieves 76.3% precision at 80% recall for overthinking prediction. These behavioral signatures could be leveraged to design dynamic inference halting rules.
Cost-Aware Utility, Pareto Frontiers, and Early-Stopping
Rather than defaulting to the longest possible chain-of-thought, cost-aware utility curves provide a principled accuracy-compute trade-off via the metric
Uλ(t)=Acc(t)−λtmaxt
where λ controls the cost sensitivity. As compute cost becomes an explicit concern (λ≥0.5), optimal accuracy-cost utility frontiers shift to substantially lower budgets (from 12–16k→2–6k tokens). Early stopping rules based on overthinking indicators preserve 97% of peak accuracy using only 60% of the compute, advocating robust gains in deployment efficiency without measurable loss in reasoning quality.
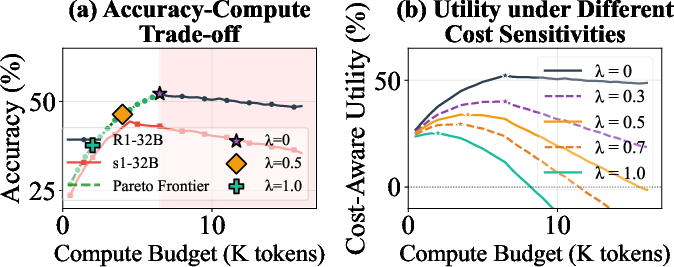
Figure 6: Pareto frontier demonstrates optimal stopping budgets under varying compute cost sensitivity; over-allocation of compute beyond accuracy peak yields strictly suboptimal utility.
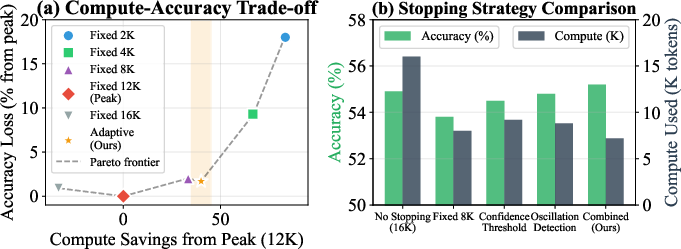
Figure 7: Indicator-based early stopping strategies consistently achieve similar accuracy with markedly lower compute vs. naïve fixed budget policies.
Implications and Future Directions
This work compellingly invalidates monotonicity in the compute-accuracy relationship for CoT-based LLM reasoning, emphasizing the necessity of instance-adaptive compute allocation strategies. It forces a paradigm shift for LLM benchmarking, requiring the reporting of efficiency/utility frontiers rather than naïve accuracy curves. The demonstration that productive overthinking detection is possible from answer trace analysis opens the way to robust, dynamic halting protocols leveraging uncertainty quantification, calibration, and self-verification (Zhang et al., 7 Apr 2025).
Technologically, these findings have immediate relevance for practical system deployment: reduced energy and cost expenditures, improved reliability, and lower risk of spontaneous answer degradation in user-facing applications. Theoretically, they motivate questions regarding the representational underpinnings of overthinking, exploration-exploitation dynamics in LLM inference, and the possible linkage to cognitive phenomena such as perseveration and meta-cognitive uncertainty.
Conclusion
This study establishes "overthinking" as a dominant, measurable, and practically consequential phenomenon in state-of-the-art LLM test-time compute scaling. Marginal utility decays and ultimately reverses, with substantial fractions of answers flipped from correct to incorrect upon overextended CoT. The findings dictate the need for compute-aware evaluation, adaptive stopping, and nuanced dynamic inference strategies for future LLM systems.