- The paper introduces OptimalThinkingBench, a unified benchmark that evaluates LLMs on overthinking simple queries and underthinking complex tasks.
- It employs innovative techniques such as Overthinking-Adjusted Accuracy and a combined F1 score to assess performance across diverse domains and reasoning tasks.
- Experimental results show that current models struggle to balance efficiency with accuracy, highlighting potential in dynamic inference and prompt engineering strategies.
OptimalThinkingBench: A Unified Benchmark for Evaluating Overthinking and Underthinking in LLMs
Introduction
OptimalThinkingBench introduces a comprehensive framework for evaluating the dual challenges of overthinking and underthinking in LLMs. Overthinking refers to excessive computational effort on simple queries, often resulting in increased latency and cost without accuracy gains. Underthinking, conversely, denotes insufficient reasoning on complex tasks, leading to suboptimal performance. The benchmark is composed of two sub-benchmarks: OverthinkingBench, targeting simple queries, and UnderthinkingBench, focusing on complex reasoning problems. This unified approach enables systematic assessment of LLMs' ability to adapt their computational effort to task complexity, a critical requirement for practical deployment.
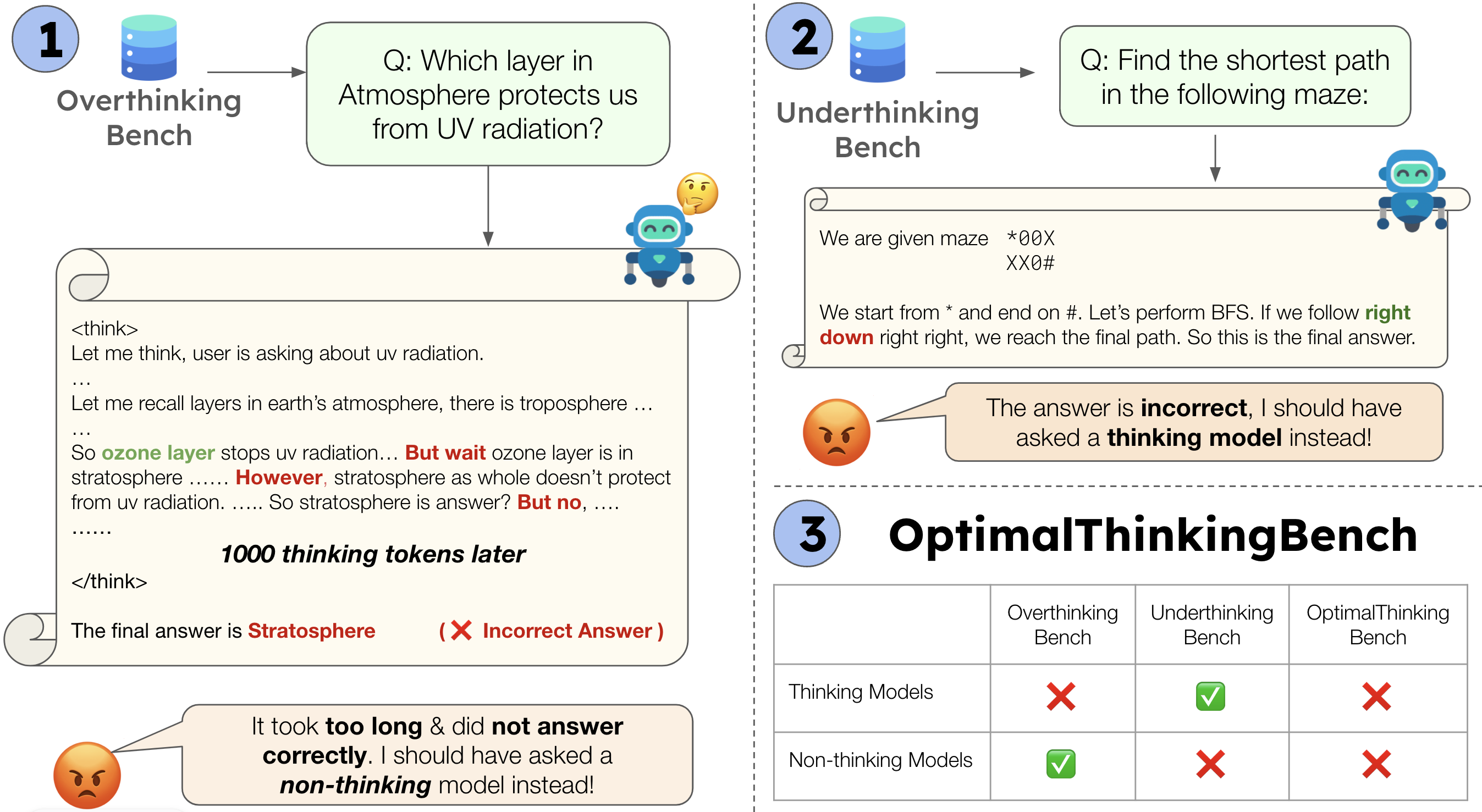
Figure 1: OptimalThinkingBench provides a unified evaluation of overthinking and underthinking in LLMs, with OverthinkingBench for simple queries and UnderthinkingBench for complex reasoning tasks.
Benchmark Construction
OverthinkingBench
OverthinkingBench is synthetically generated to cover 72 domains and four answer types (numeric, multiple-choice, short answer, open-ended). The generation pipeline employs constrained sequential prompting to ensure diversity and difficulty control. Filtering is performed by sampling multiple responses from a separate LLM and retaining only those questions where all responses match the reference answer, as judged by an LLM-as-a-Judge. This guarantees answer correctness, question clarity, and appropriate difficulty.
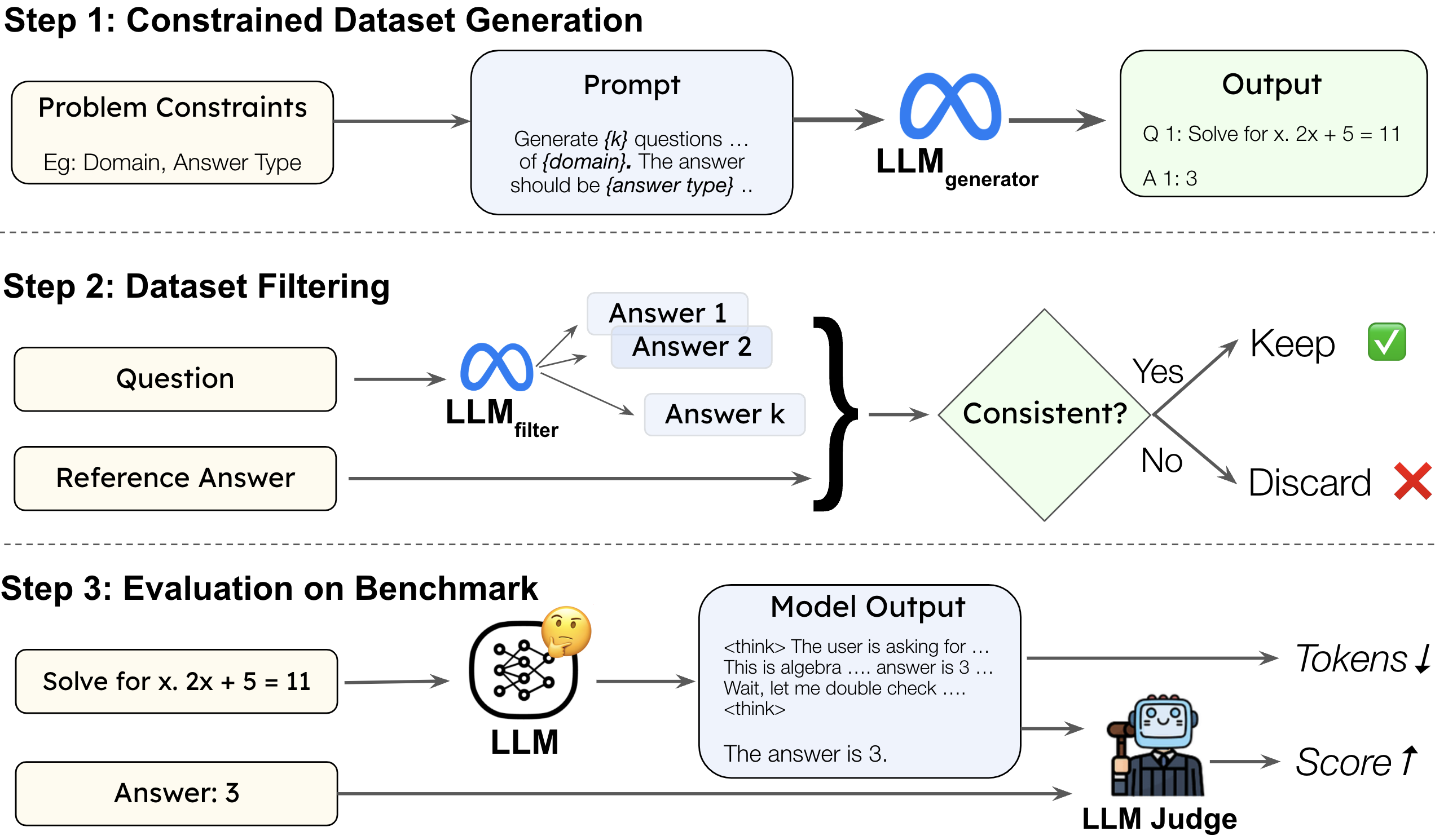
Figure 2: OverthinkingBench generation and evaluation pipeline, including constrained question generation, filtering, and LLM-as-a-Judge verification.
Evaluation on OverthinkingBench uses the Overthinking-Adjusted Accuracy (OAA), which measures accuracy under a thinking token budget. The area under the OAA curve (AUC_OAA) quantifies the trade-off between correctness and computational efficiency.
UnderthinkingBench
UnderthinkingBench leverages tasks from Reasoning Gym, selecting those where a small thinking model outperforms a large non-thinking model by a significant margin. This ensures the inclusion of tasks that genuinely require step-by-step reasoning. The benchmark spans 11 reasoning task types across six categories, with correctness verified via code-based programmatic verifiers.
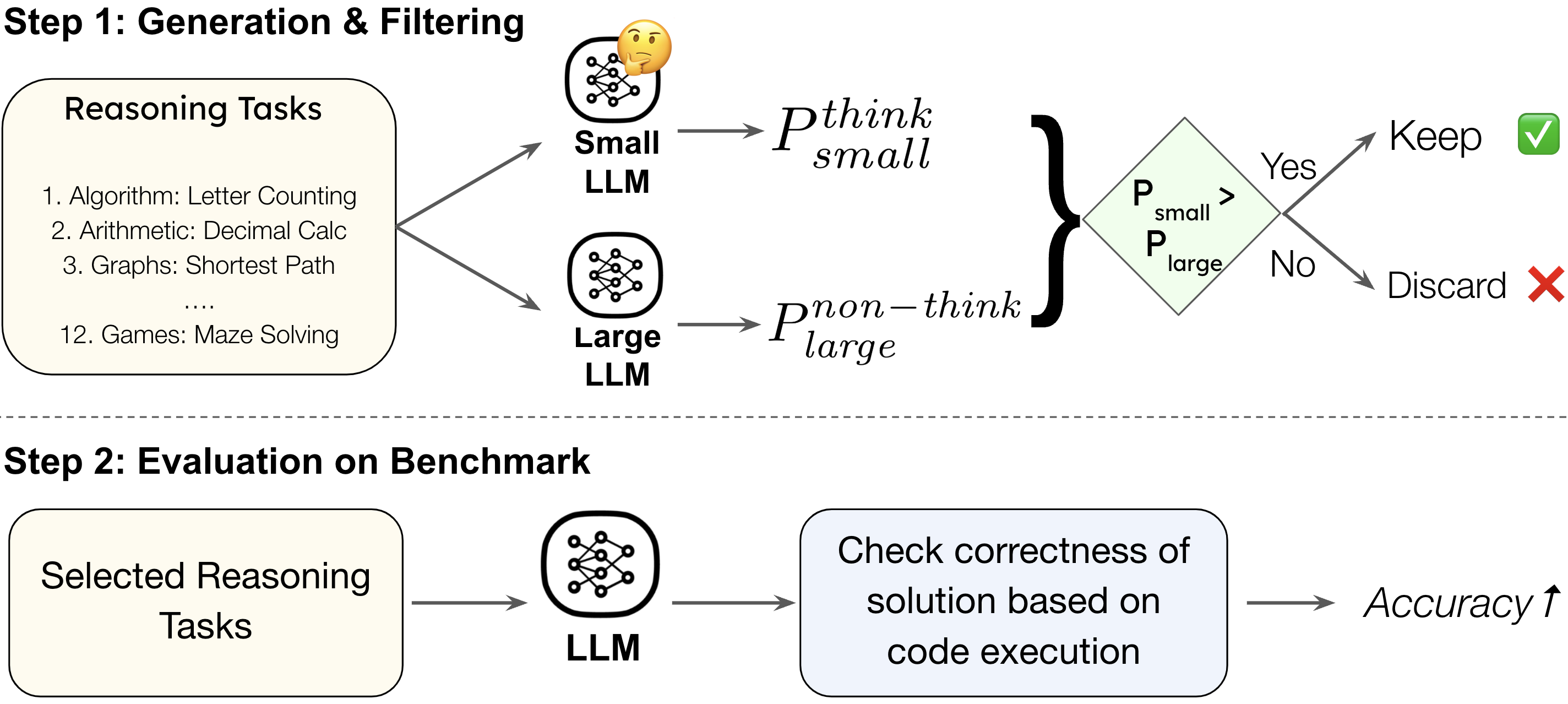
Figure 3: UnderthinkingBench construction and evaluation pipeline, focusing on reasoning tasks that benefit from explicit thinking.
Unified Evaluation Metric
OptimalThinkingBench combines AUC_OAA from OverthinkingBench and accuracy from UnderthinkingBench into a single F1 score:
F1otb=2⋅AUCOAA+AccutAUCOAA⋅Accut
This metric enforces that models must perform well on both simple and complex queries to achieve a high score, penalizing those that excel in only one regime.
Experimental Results
Comprehensive evaluation of 33 models reveals that no current LLM achieves optimal balance between accuracy and efficiency. The best closed-weight model, o3, attains a score of 72.7%, while the best open-weight model, GPT-OSS-120B, reaches 62.5%. Most models either overthink on simple queries or underthink on complex ones, with only five models surpassing the 50% threshold.
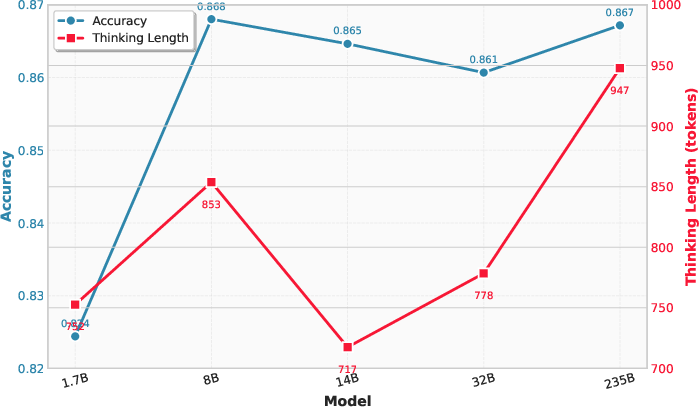
Figure 4: Overthinking and accuracy as a function of model size for the Qwen3 family, showing increased thinking tokens with larger models but plateaued accuracy.
Thinking models consistently generate hundreds of tokens for simple queries, incurring latency and cost without accuracy improvements. Non-thinking models, while efficient on simple tasks, fail to solve complex reasoning problems. Distilled models specialized for thinking show degraded performance on simple queries, indicating a trade-off between reasoning capability and efficiency.
Methods for Optimal Thinking
Several strategies were explored to encourage optimal thinking:
- Efficient Reasoning Methods: Length-based reward shaping, model merging, and auxiliary verification tasks reduce token usage by up to 68%, but often degrade performance on complex reasoning tasks.
- Routing Approaches: Difficulty-based routers that select between thinking and non-thinking modes improve overall scores by 2–11%, but still fall short of oracle routing, which achieves substantially higher scores.
- Prompt Engineering: Explicitly prompting models to "not overthink" reduces token usage by up to 29% without harming accuracy, while "step-by-step" prompts increase overthinking and sometimes reduce accuracy on simple queries.
Analysis of Thinking Behavior
Thinking token usage varies by domain and answer type. STEM domains elicit more tokens, but without corresponding accuracy gains. Numeric questions trigger more extensive reasoning, likely due to post-training emphasis on mathematical tasks. For multiple-choice questions, the number of distractor options induces a near-linear increase in overthinking, even when distractors are irrelevant.
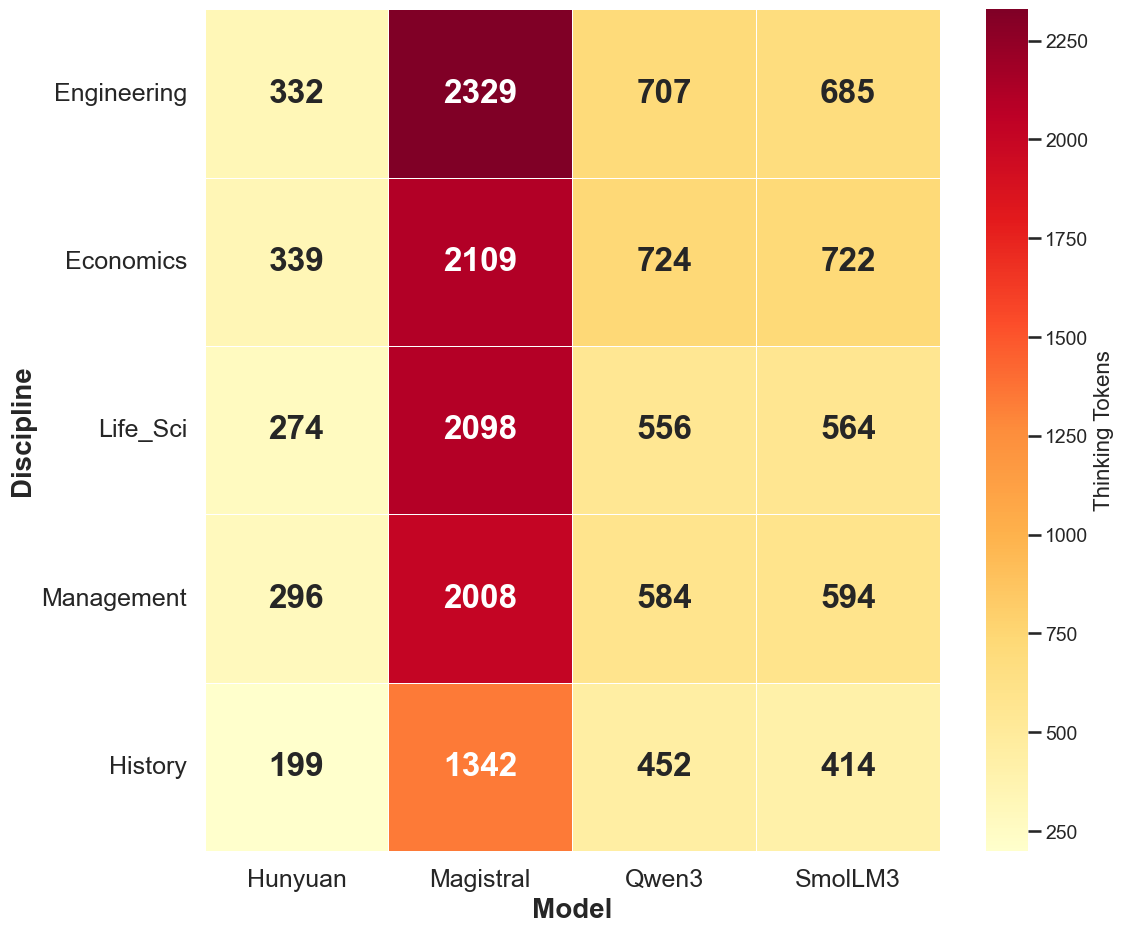
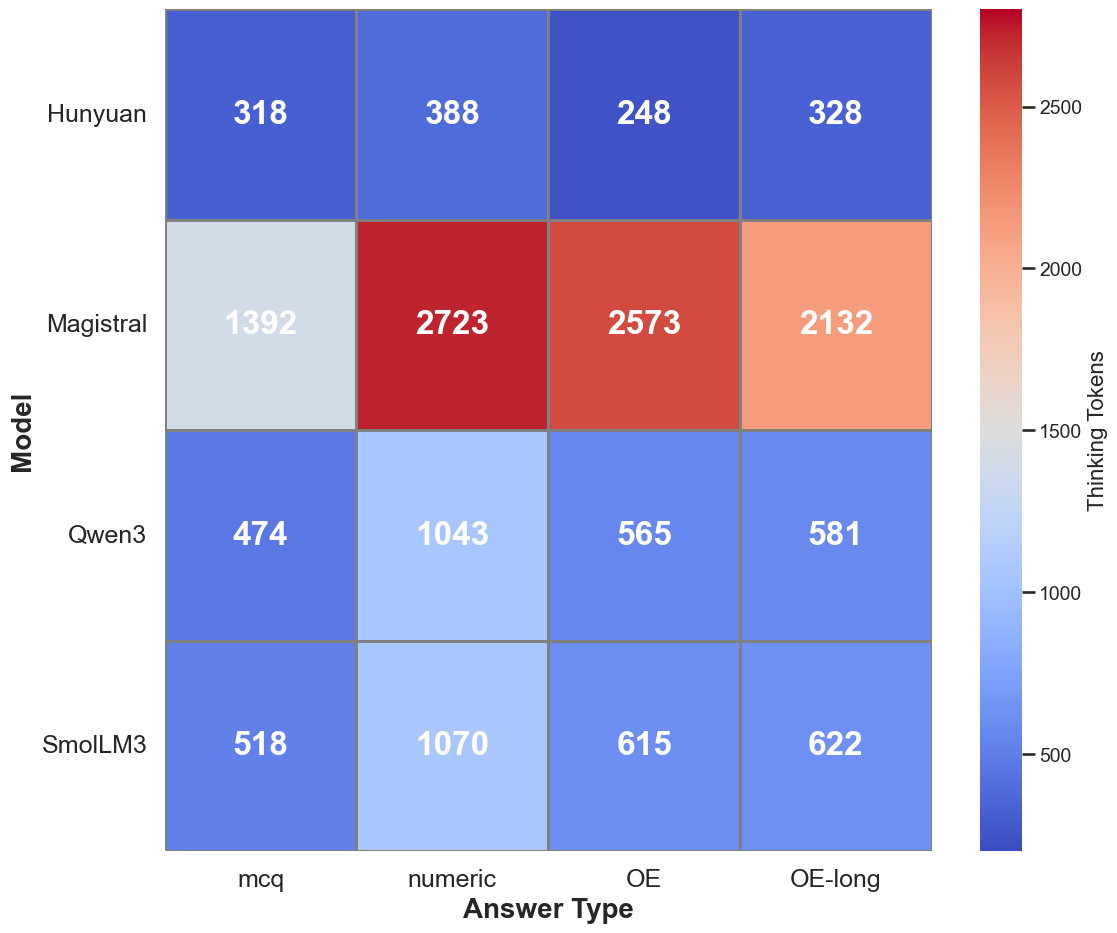
Figure 5: Thinking token usage across domains, with STEM fields eliciting more tokens.
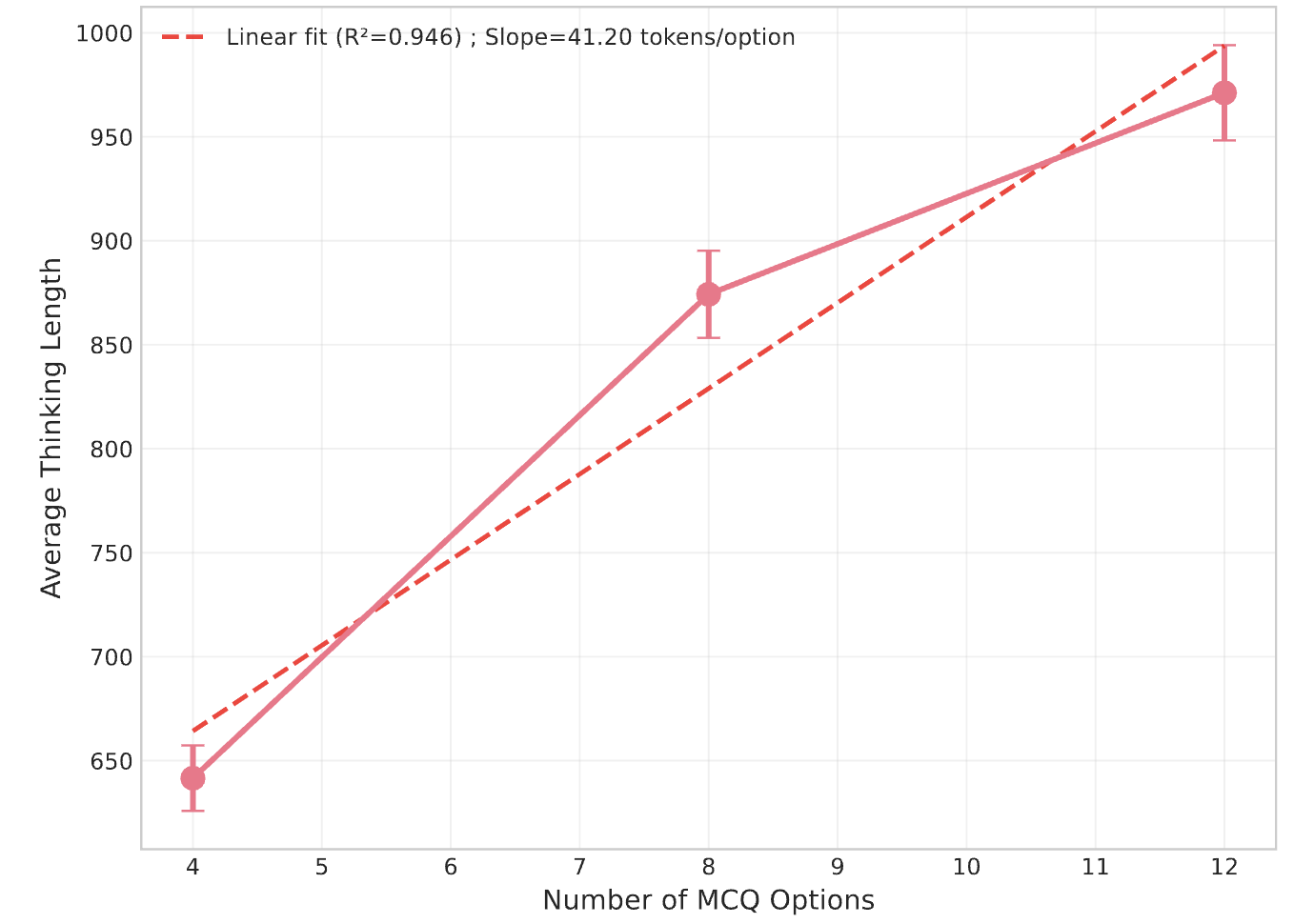
Figure 6: Overthinking increases linearly with the number of options in multiple-choice questions.
Qualitative Examples
Qualitative analysis demonstrates that overthinking can lead to incorrect answers due to excessive deliberation and confusion, while underthinking results in heuristic-based, unverified solutions. For instance, models may initially identify the correct answer but subsequently second-guess themselves, ultimately providing an incorrect response. In complex reasoning tasks, non-thinking models often fail to verify their solutions, leading to suboptimal outcomes.
Implications and Future Directions
OptimalThinkingBench exposes a fundamental limitation in current LLMs: the inability to adaptively allocate computational effort based on task complexity. This has direct implications for user experience, cost, and practical deployment. The benchmark provides a standardized, extensible framework for tracking progress and encourages the development of unified models capable of optimal reasoning. Future research should focus on dynamic inference algorithms, improved routing mechanisms, and training objectives that explicitly balance efficiency and performance across diverse query types.
Conclusion
OptimalThinkingBench offers a rigorous, unified evaluation of overthinking and underthinking in LLMs, revealing substantial gaps in current model capabilities. While some methods show promise, no existing approach achieves optimality across both simple and complex tasks. The benchmark is designed to evolve with model competence, serving as a critical tool for guiding future research toward truly adaptive, efficient, and performant LLMs.

