- The paper shows that merely increasing the thinking budget does not linearly improve reasoning quality in LLMs.
- It compares configurations like self-consistency, reflection, and summary, with summary consistently outperforming the baseline.
- Empirical results emphasize the need for adaptive compute allocation strategies to optimize accuracy and efficiency in LLM reasoning tasks.
Investigating the Limits of Thinking Budgets in LLMs
Theoretical Background and Motivation
The recent advancements in reasoning-capable LLMs have expanded the exploration of their operational capabilities beyond mere answer generation. These models are now tasked with performing explicit reasoning processes to improve decision-making outcomes. The paper "Increasing the Thinking Budget is Not All You Need" (2512.19585) explores evaluating how the "thinking budget" — the computational resources dedicated to reasoning — impacts model performance. This research scrutinizes configurations like self-consistency and reflection to devise a framework that balances both performance outcomes and computational costs. The study identifies that augmenting the thinking budget alone is insufficient and emphasizes the role of alternative configurations to achieve more accurate responses.
Thinking Budget Evaluation and Methodology
A major portion of the study involves dissecting the interactions between the thinking budget and various reasoning configurations. By setting up controlled environments where configurations such as self-consistency and reflection interact with different thinking budgets, the research aims to reveal nuanced relationships between computational resources and reasoning efficiency.
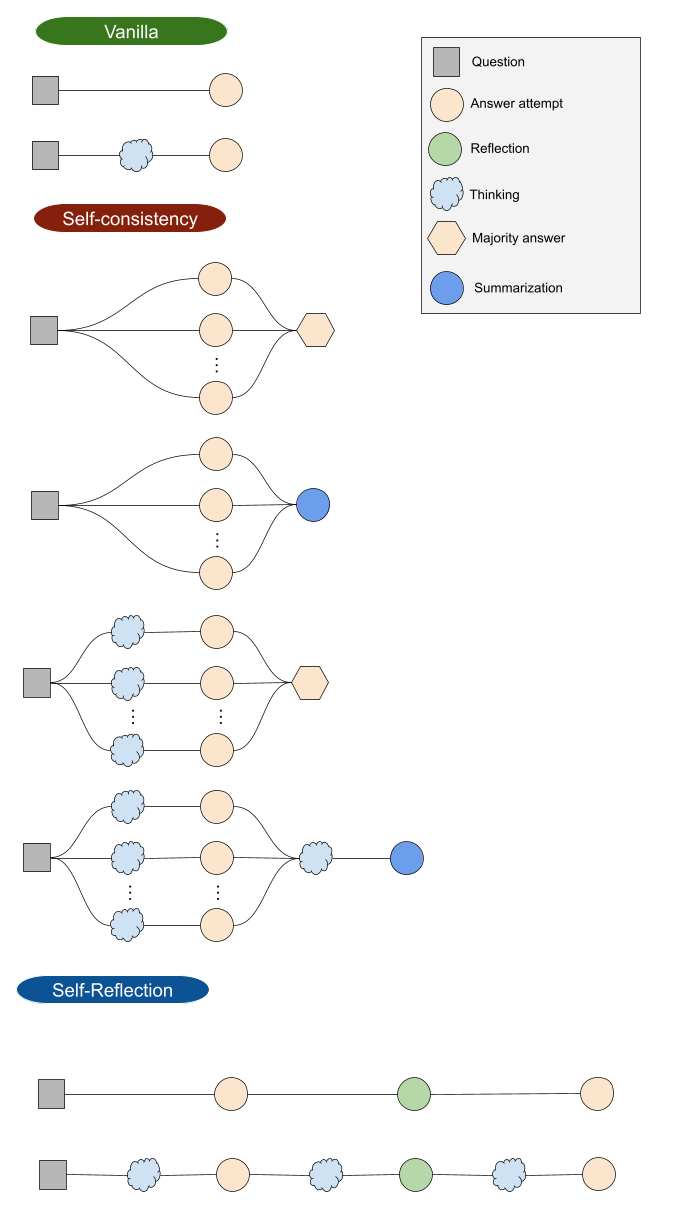
Figure 1: Visualization of reasoning strategies across different configurations.
The paper adopts empirical methods to assess these configurations using benchmarks like AIME24, across models like Qwen3-8B and DeepSeek-R1-Distill-Llama-8B. The methodology employs configurations such as Vanilla, Self-Consistency, Summary, and Reflection with varying levels of compute allocation to distill which strategies optimize performance under specific computational budgets.
Insights and Empirical Results
The experimental outcomes reveal that the straightforward expansion of the thinking budget does not yield linear improvements in reasoning quality. Particularly, the Summary configuration emerges as the most effective, consistently surpassing the baseline Vanilla strategy in performance.
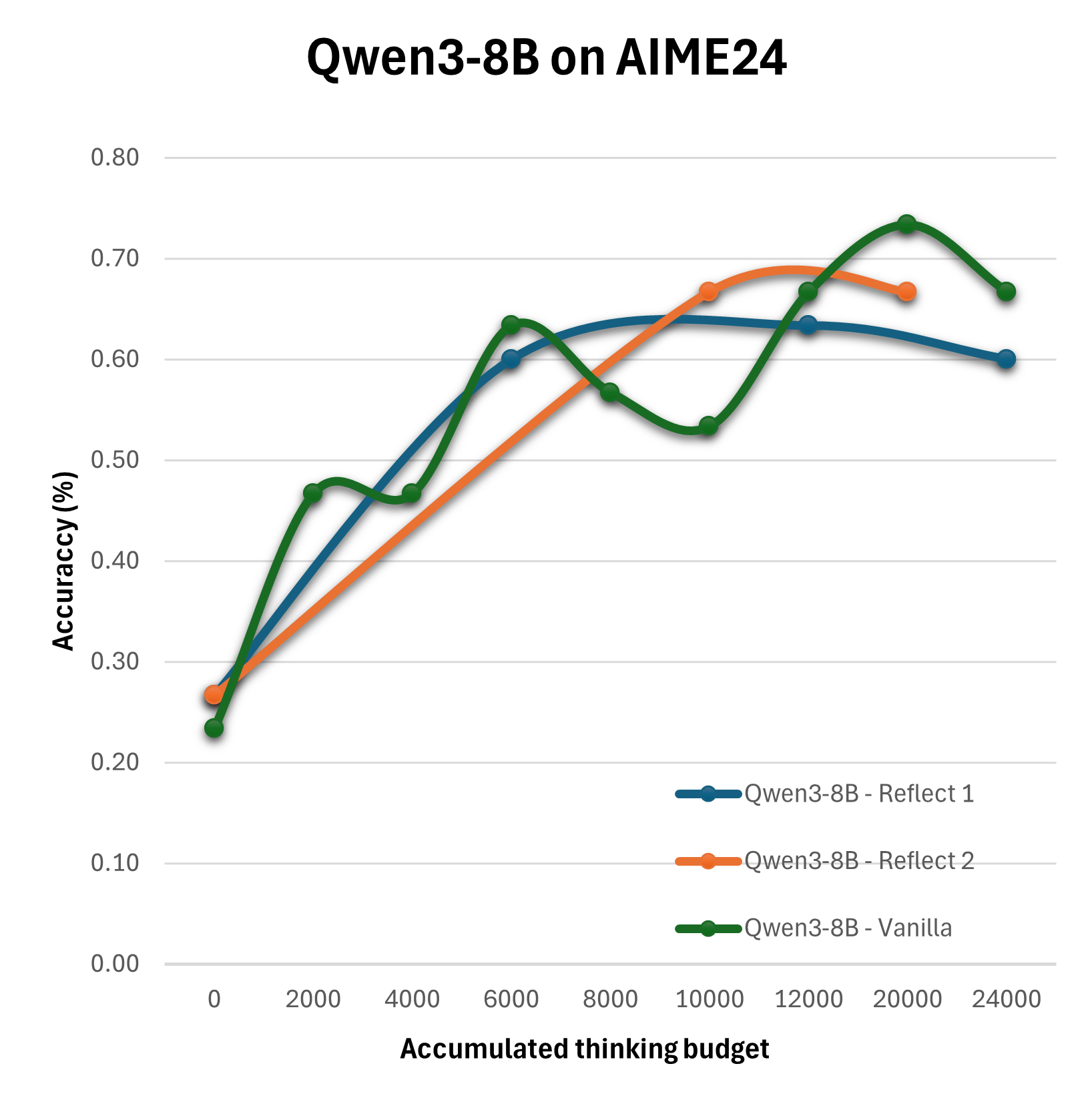
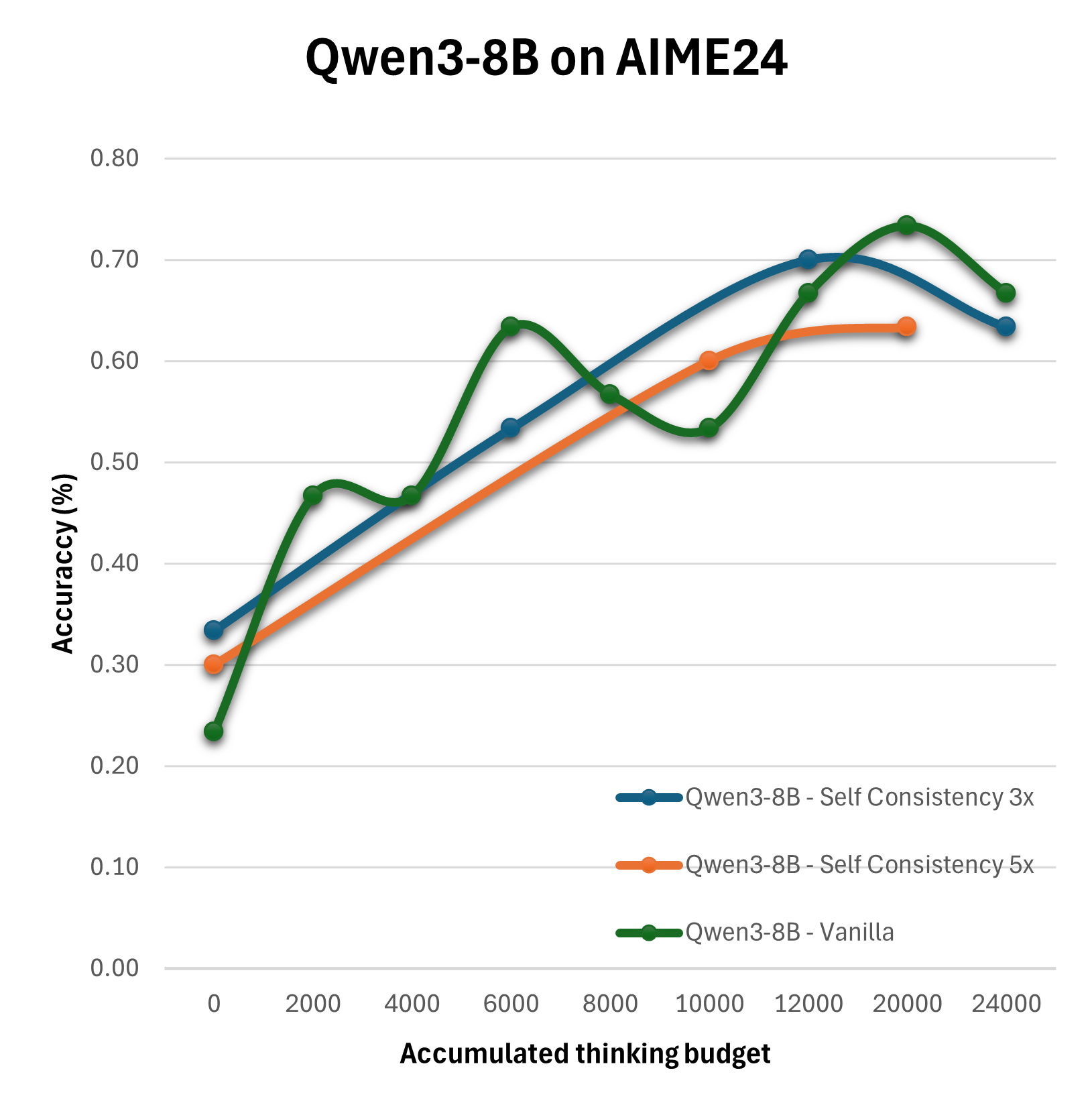
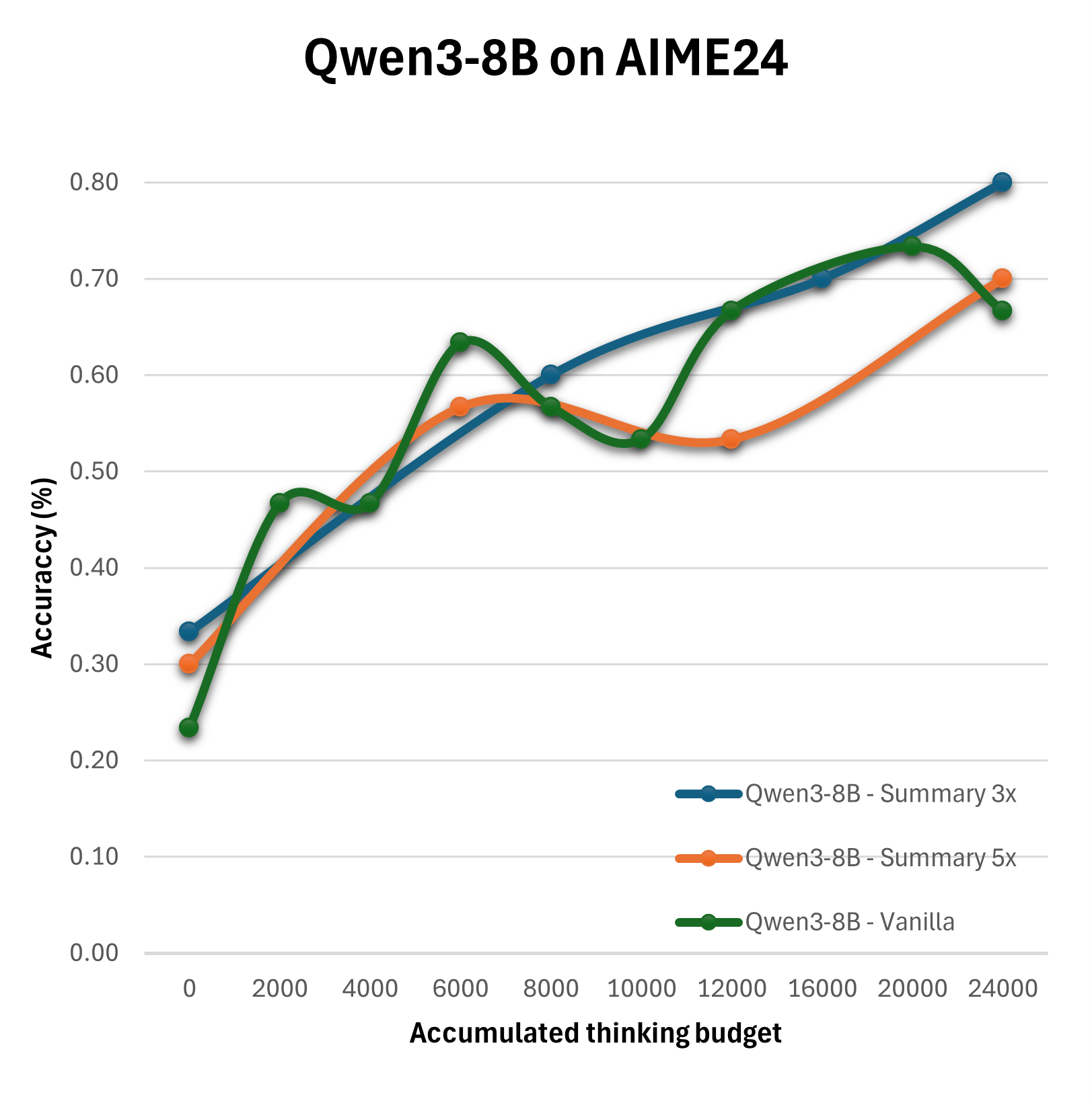
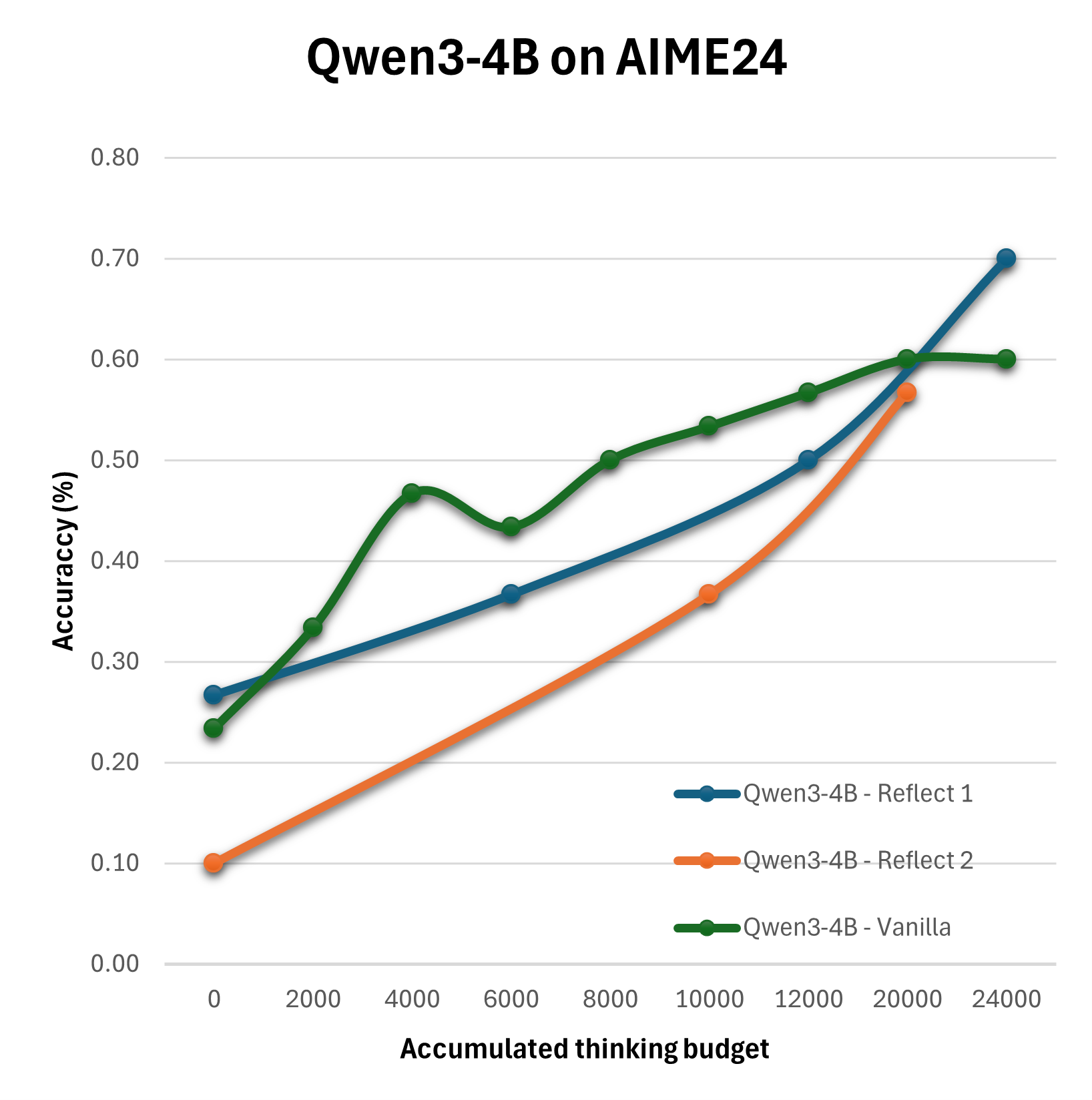
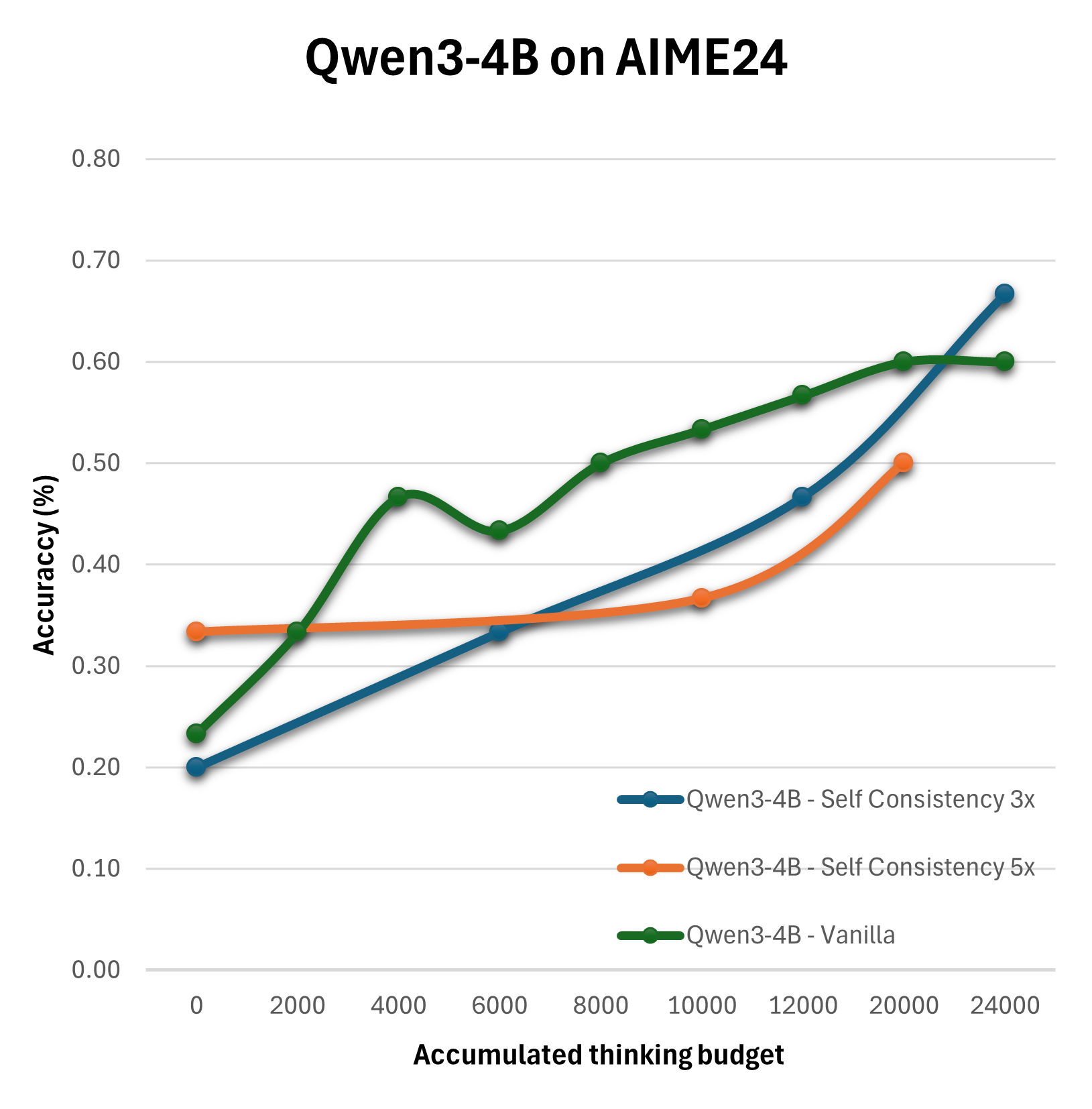
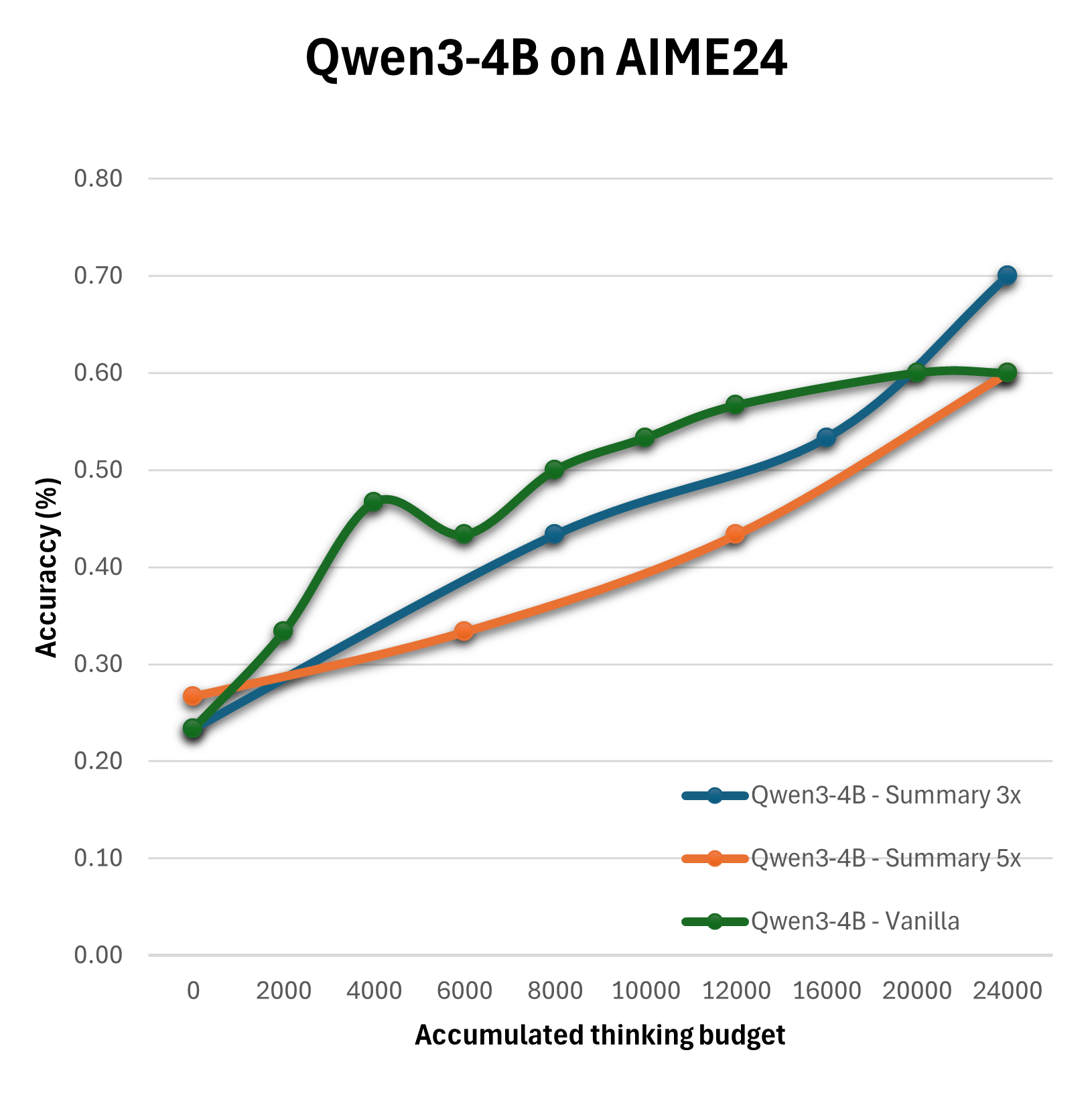
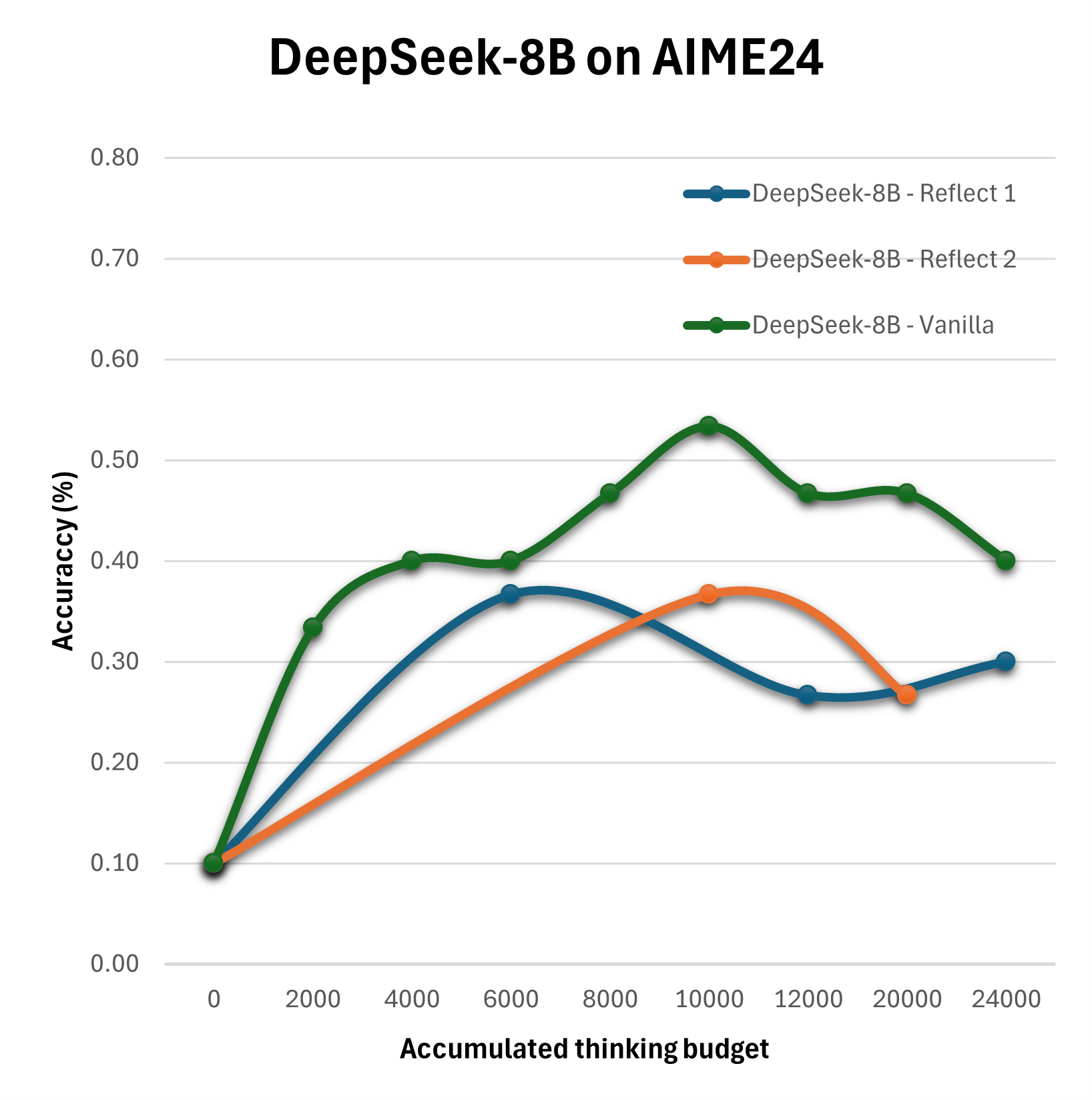
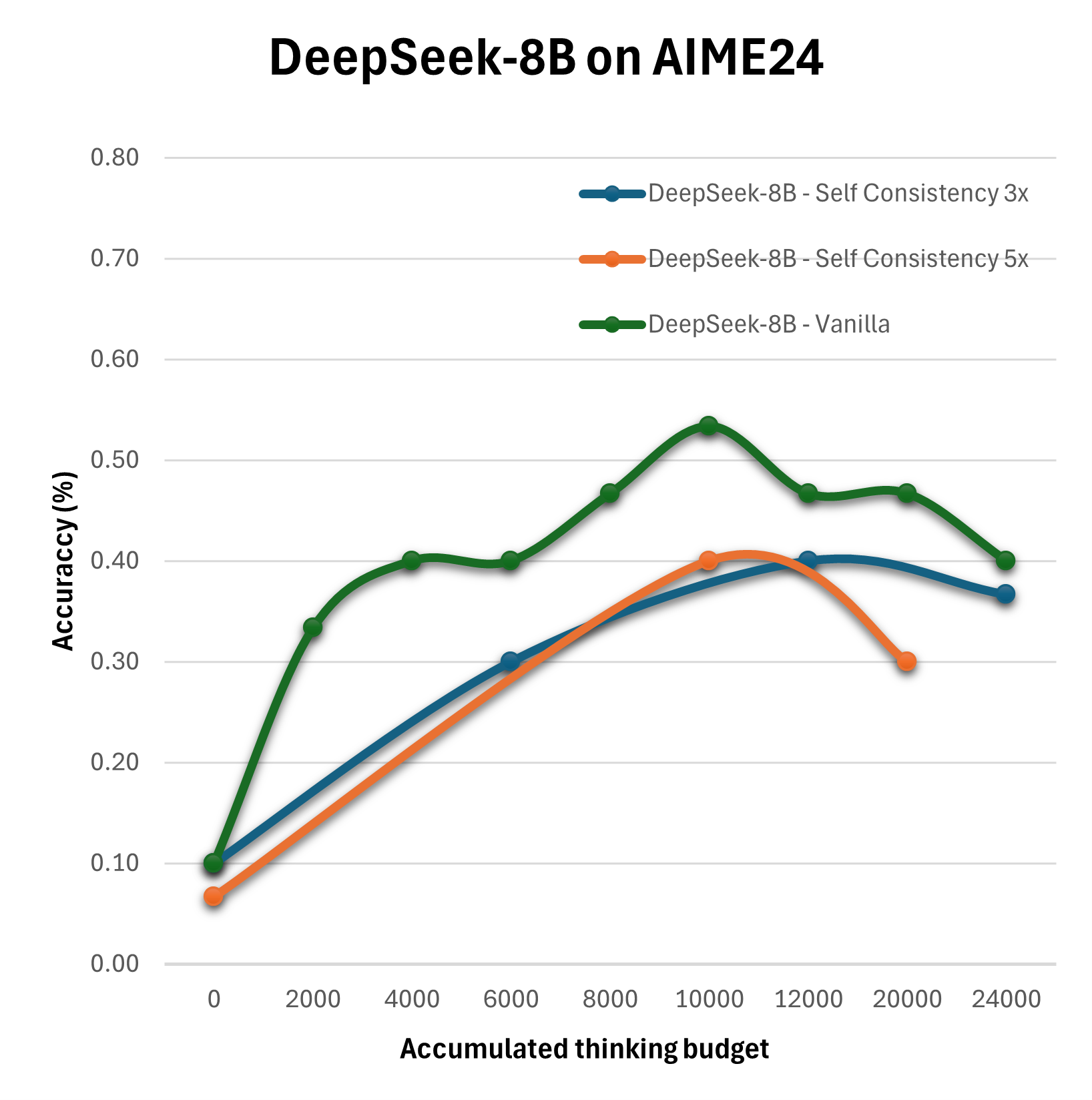
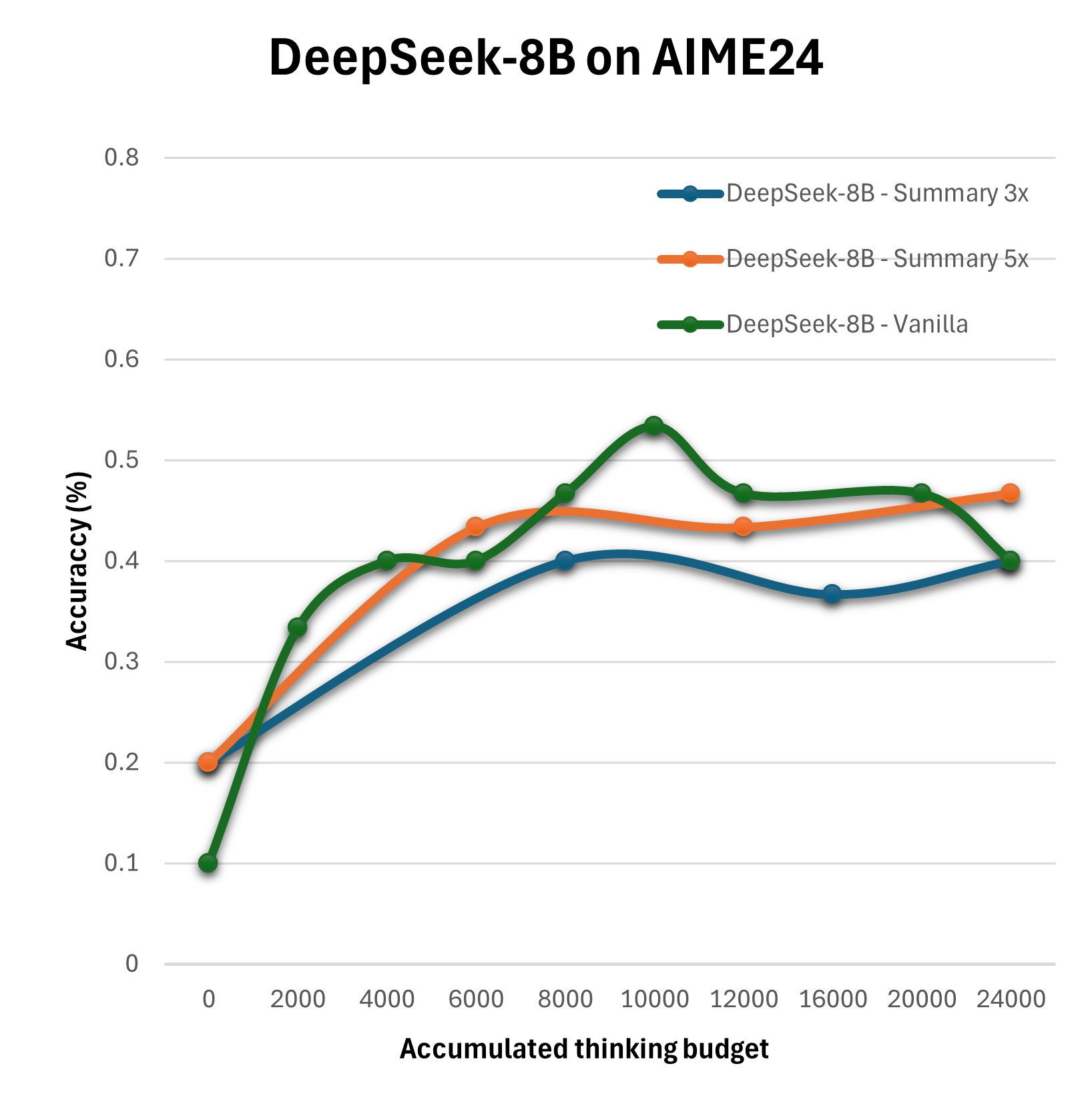
Figure 2: Evaluation of different configurations on the AIME24 on Qwen3-8B, Qwen3-4B and DeepSeek-R1-Distill-Llama-8B.
Results suggest that more sophisticated configurations achieve enhanced performance when thoughtfully combined with optimized compute distributions. For instance, multi-step reflection and summary mechanisms significantly benefit decision accuracy and quality more than simplistic extensions of reasoning tokens.
Theoretical Implications and Future Directions
The findings underscore the importance of strategic compute allocation and sophisticated reasoning strategies in optimizing LLM performance. This not only challenges the previously held notion that an increased thinking budget inherently boosts model efficacy, but it also articulates a more nuanced understanding of reasoning dynamics. Future research is advised to expand on these configurations across a broader array of reasoning tasks and to devise adaptive strategies that adjust compute allocations based on task complexity and model capacity dynamically.
Conclusion
In evaluating the reasoning strategies of LLMs, the research presented in "Increasing the Thinking Budget is Not All You Need" highlights critical insights into the operational efficiencies associated with various compute configurations. The study provides a structured framework for deploying these configurations more effectively, contributing to the broader discourse on the adaptive optimization of AI reasoning capabilities. Researchers are encouraged to leverage these insights to refine the deployment of reasoning-capable LLMs across diverse application domains.

