- The paper introduces HaloProbe, a Bayesian framework that disentangles internal model dynamics from external caption statistics to detect and mitigate object hallucinations in vision-language models.
- It employs a balanced estimator trained on both fine-grained attention and logit features as well as token position and object repetition to overcome confounding factors like Simpson’s paradox.
- HaloProbe enables non-invasive, post-hoc mitigation strategies that preserve output fluency while significantly reducing hallucination metrics across several LVLMs.
Bayesian Detection and Mitigation of Object Hallucinations in Vision-LLMs with HaloProbe
Introduction
The prevalence of object hallucination—token-level generation of references to objects ungrounded in the visual input—in Large Vision-LLMs (LVLMs) critically limits the reliability and practical deployment of such models in vision-language understanding and generation. Prevailing hallucination detection pipelines typically leverage image attention statistics as a direct signal for hallucination but often ignore latent confounding factors stemming from dataset biases, token position, and object repetition. The paper "HaloProbe: Bayesian Detection and Mitigation of Object Hallucinations in Vision-LLMs" (2604.06165) presents an analysis of this confounded signal, identifies the emergence of Simpson's paradox in aggregated attention statistics, and introduces HaloProbe, a model-agnostic Bayesian hallucination detection framework constructed to disentangle internal generation dynamics from superficial external statistics. The HaloProbe framework further enables non-invasive, decoding-level and post-hoc hallucination mitigation strategies, offering state-of-the-art reduction in hallucinations without degrading output fluency.
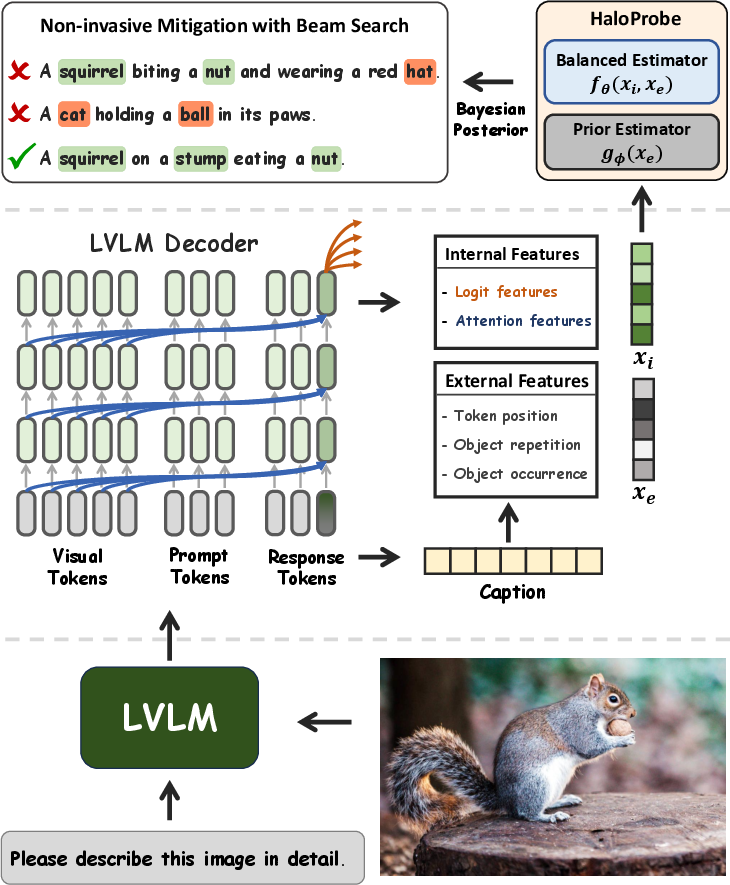
Figure 1: Overview of HaloProbe. HaloProbe combines internal features (attention and logit statistics) with external features (e.g., object repetition, token position) using a balanced estimator and a prior estimator to yield token-level hallucination probabilities, usable for downstream detection and mitigation.
Analysis of Hidden Confounders and Simpson's Paradox in LVLM Attention
Prior research posits that hallucinated tokens are characterized by low image attention, leveraging this as a discriminative signal. The paper empirically demonstrates that this signal is confounded by the non-stationary distribution of token positions and object repetitions. When conditioning on these variables, attention trends estimated at a coarse level are attenuated or even reversed, manifesting a Simpson's paradox.
Specifically, hallucinated objects predominately occur at later positions in generated captions and are typically mentioned only once (i.e., are first occurrences), while correct objects are often introduced earlier and are more frequently repeated (Figure 2). Conditioning on token position, hallucinated objects can in fact receive higher conditional image attention compared to correct objects, inverting the expectation derived from unconditioned attention statistics. Object occurrence (first vs. non-first) further stratifies attention distributions, such that first mentions—regardless of correctness—acquire notably higher attention than subsequent mentions. Marginalizing over these variables thus misrepresents the reliability of attention as a hallucination detection signal.
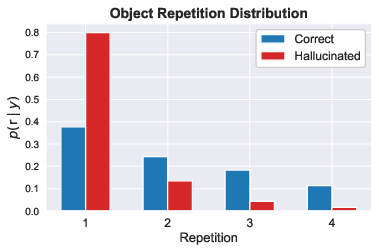
Figure 3: Distribution of object repetition counts ($r \in \{1,2,3,4}$). Correct objects are repeated with higher frequency, distinguishing their feature distribution from hallucinated objects.
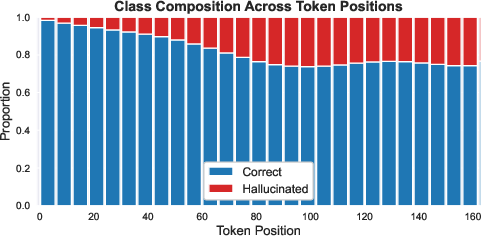
Figure 2: Proportion of correct vs. hallucinated objects across token positions; class imbalance is strongly pronounced at early positions, leading to trivial solution baselines.
The HaloProbe Framework: Bayesian Disentanglement of Internal and External Signals
HaloProbe addresses these confounding effects by explicitly factorizing detection into: (1) internal model dynamics (fine-grained attention patterns and logit-based confidences); and (2) external caption statistics (token position, object repetition, first-occurrence indicator). The core estimator is trained on a position- and repetition-balanced dataset to prevent shortcut learning via easily separable external features. A separate prior estimator models the probability of correctness exclusively from the external statistics using the naturally imbalanced data. During inference, Bayes' rule is used to optimally combine these estimators, sidestepping the sensitivity to shortcut features and improving robustness to shifts in caption structure distributions.
Ablation studies evidence that both internal and external features contribute to discrimination, whereas naïve models leveraging only class imbalance can attain deceptively high accuracy but minimal true discriminative power (AUROC).
Hallucination Mitigation: Non-Invasive Strategies Enabled by HaloProbe
Unlike intervention-based hallucination mitigation approaches that directly manipulate the attention distributions during decoding, often degrading fluency and yielding stochastic generation artifacts, HaloProbe enables post-hoc and beam search-based mitigation while preserving original model dynamics. Its token-level hallucination score provides a reliable external signal to:
- Conduct hallucination-aware beam search: For each candidate caption in the beam, HaloProbe assigns scores reflecting the total hallucination likelihood, facilitating selection of beams with minimum hallucination content and maximum object recall.
- Perform post-hoc editing: Hallucinated tokens are flagged and passed to an external text editor (e.g., an LLM) for targeted removal, with strict constraints to preserve semantic fidelity and grammaticality.

Figure 4: Without intervention, the LLaVA-1.5 baseline produces coherent, low-redundancy captions. Intervention-based approaches can induce severe repetitive degeneration, as captured by high RE-4 redundancy error scores.
Experimental Results and Numerical Evaluation
Comprehensive experiments on established LVLMs (LLaVA-1.5, Shikra, MiniGPT-4, Qwen3-VL, InternVL3.5) demonstrate that HaloProbe yields consistent SOTA detection (≥5 points improvement in accuracy and ≥3 points AUROC over strong baselines) and mitigation performance (substantial reductions in CHAIR Cs, Ci hallucination rates, and improved or preserved F1 scores) across greedy, nucleus, and beam decoding settings.
Table 1: Representative detection results (LLaVA-1.5-7B backbone).
| Method | Accuracy | AUROC | Precision | Recall | F1 |
|------------|----------|-------|-----------|--------|------|
| IC | 62.56 | — | 61.93 | 81.60 | 70.42|
| UT | 50.57 | — | 53.60 | 70.62 | 60.95|
| EAZY | 78.77 | — | 78.41 | 83.38 | 80.82|
| DIML | 84.46 | 90.19 | — | 72.34 | — |
| HaloProbe | 90.00 | 93.50 | 92.50 | 95.80 | 94.10 |
Mitigation consistently outperforms prior strategies (including intervention-based methods like PAI, DIML, EAZY, etc.) on both older and newer LVLMs. Additionally, ablation confirms all core HaloProbe components—fine-grained attention, external features, and Bayesian decomposition—are required for maximal effect.
Theoretical and Practical Implications
HaloProbe provides empirical and theoretical evidence that attribution based solely on internal model attention is inherently unreliable for hallucination detection due to dataset-induced confounding and Simpson's paradox. The Bayesian decomposition unifies shortcut control and robust inference, suggesting broader applicability in tasks involving spurious correlation and fairness. The mitigation pipeline demonstrates that robust, non-invasive, post-hoc interventions can yield competitive or superior control over hallucination, obviating the need for fragile model-internal interventions.
Directions for Future Work
Potential extensions arise in the application of the HaloProbe framework to other hallucination domains (relation, attribute-level errors) and more complex multimodal tasks (multimodal reasoning, compositional grounding). Investigation into joint training of the probe during model fine-tuning, or integration into reinforcement learning-based decoding, could further enhance grounding fidelity. Analysis of probe robustness under adversarial or real-world shift conditions remains an open avenue, particularly in safety-critical deployments.
Conclusion
HaloProbe establishes a rigorous Bayesian detection and mitigation framework for object hallucination in LVLMs, decisively demonstrating that attention-based strategies must account for latent confounders. The proposed method achieves state-of-the-art hallucination reduction across models and decoding paradigms, while maintaining output fluency by avoiding internal interventions. This robust and generalizable framework sets a new standard for factual consistency in generation and provides useful tools for analyzing dataset bias and shortcut learning in multimodal AI systems.

