- The paper introduces SRPO, which dynamically routes samples between GRPO and SDPO to combine early efficiency with long-term stability in RLVR training.
- It leverages entropy-aware dynamic weighting to stabilize self-distillation by reducing high-entropy, uncertain updates during later training phases.
- Extensive evaluations on five benchmarks show SRPO achieves up to 7.5% higher accuracy and 17.2% lower compute cost compared to traditional methods.
Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing
Introduction
The paper "Unifying Group-Relative and Self-Distillation Policy Optimization via Sample Routing" (2604.02288) addresses fundamental limitations of reinforcement learning with verifiable rewards (RLVR) for post-training LLMs and presents Sample-Routed Policy Optimization (SRPO), a unified on-policy optimization framework that dynamically routes learning signals at the sample level. This approach integrates two dominant paradigms: Group Relative Policy Optimization (GRPO), which applies reward-aligned but coarse sequence-level credit assignment, and Self-Distillation Policy Optimization (SDPO), which leverages dense logit-level supervision from a feedback-conditioned self-teacher but suffers from late-stage instability.
The paper's main contributions are an in-depth analysis of SDPO's failure modes, the introduction of SRPO as an adaptive routing mechanism with entropy-aware dynamic weighting, and extensive empirical results demonstrating consistently superior performance, sample efficiency, and compute cost compared to both GRPO and SDPO across five challenging science and tool-use benchmarks and two model scales.
Limitations of GRPO and SDPO for RLVR
GRPO is appealing for its simplicity and robust sequence-level outcome alignment: for each group of sampled trajectories under a prompt, a normalized scalar advantage is applied uniformly to every token. While this suffices for correct rollouts, it lacks the granularity required to localize and correct specific failures in incorrect rollouts, resulting in diluted gradients and slower convergence, especially for complex reasoning tasks.
SDPO circumvents this weakness by augmenting the supervision signal with on-policy logit-level distillation: a student trajectory is matched to the distribution induced by a self-teacher, typically conditioned on privileged feedback or correct sibling rollouts. This provides rich, targeted guidance and often yields rapid early-stage improvement on difficult domains. However, SDPO is frequently unstable over long training horizons:
- Self-distillation on already-correct samples introduces optimization ambiguity, as reward-equivalent reasoning paths are unduly collapsed, leading to degraded performance.
- The quality of the self-teacher’s distillation signal progressively degrades, manifesting as increased entropy and lower informativeness as the model converges, which destabilizes optimization.
These claims are substantiated in training dynamics on Qwen3-8B: SDPO initially surpasses GRPO but is eventually overtaken and can catastrophically collapse, whereas GRPO maintains steady, albeit slower, improvement. SRPO is designed to capture the early efficiency of SDPO and the long-term robustness of GRPO.
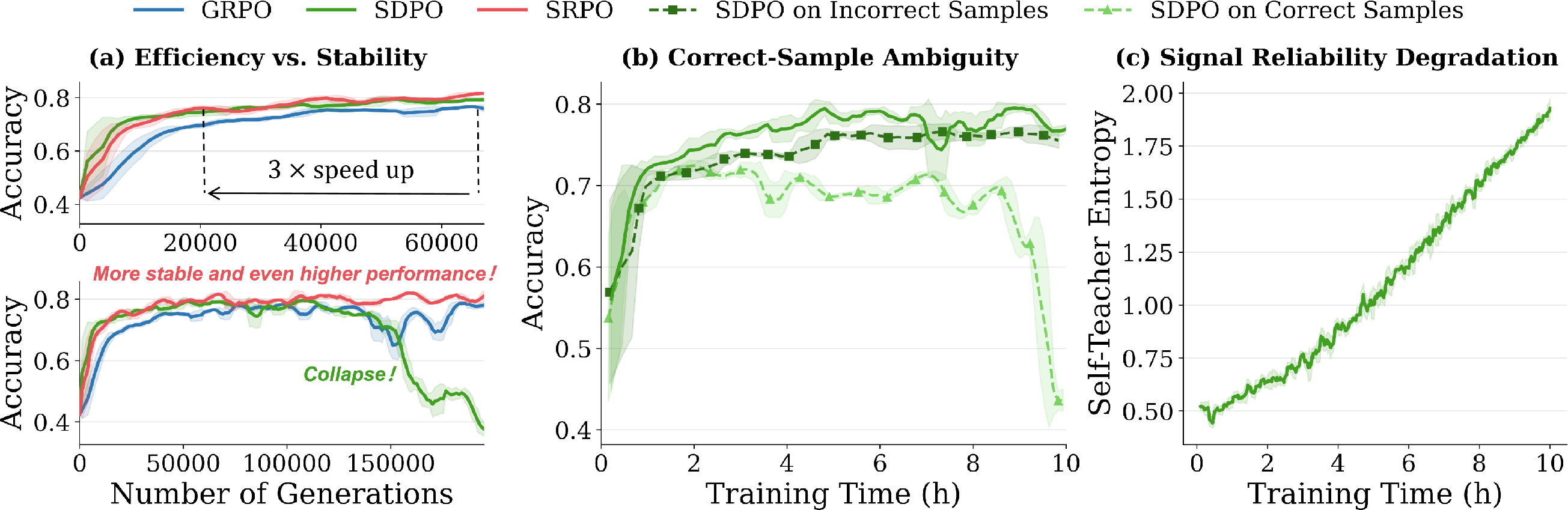
Figure 1: Training dynamics and diagnostic analysis demonstrate SDPO’s early advantage and eventual collapse, the necessity of sample routing, and the rise in self-teacher entropy over time.
The SRPO Framework
SRPO proposes a sample-level routing mechanism: for each sampled rollout, the framework checks correctness and teacher information availability. Correct rollouts are assigned to the GRPO branch for reward-aligned updates; incorrect rollouts with an available correct sibling are assigned to the SDPO branch for logit-level corrective supervision. To further stabilize SDPO in later training, entropy-aware dynamic weighting down-weights high-entropy (uncertain) distillation targets.
This architecture leverages the strengths of each base method and mitigates their weaknesses: dense feedback from SDPO is targeted where it is beneficial and reliable, and GRPO’s reward-driven updates dominate as the model matures and generates more correct responses.
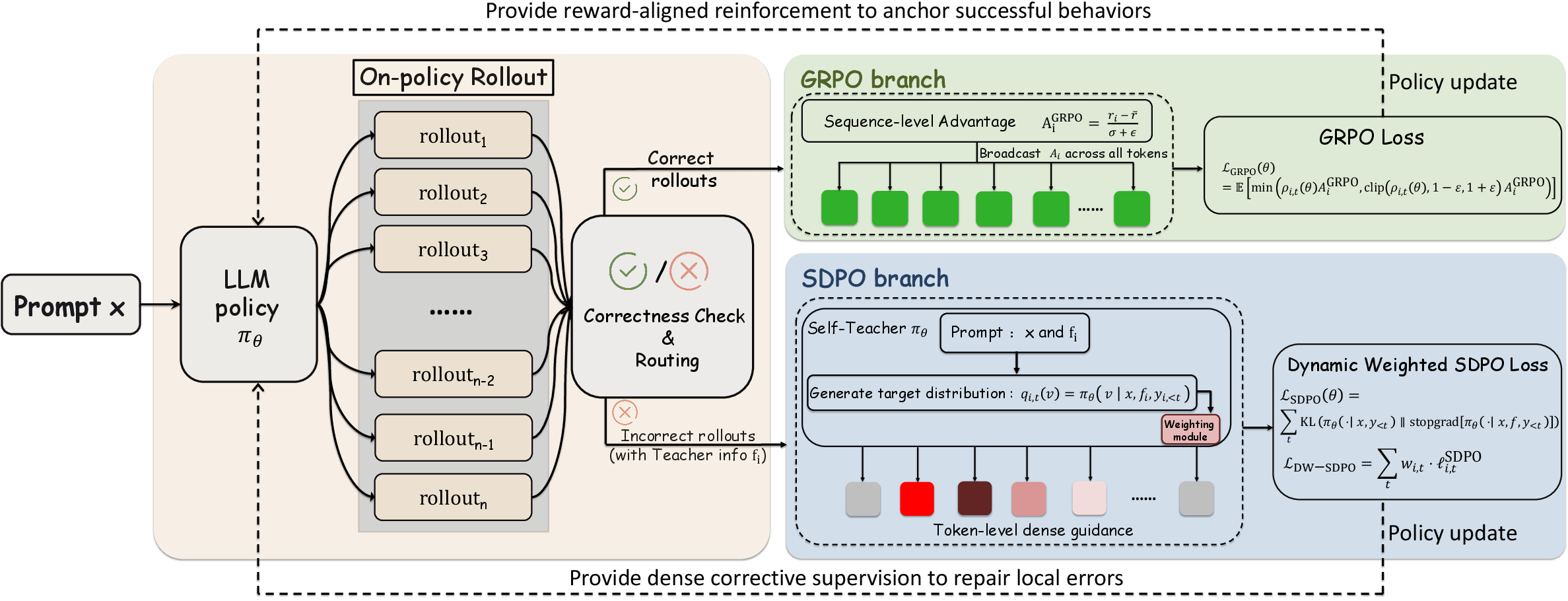
Figure 2: SRPO routes correct samples to GRPO for reward alignment and incorrect samples (with teacher information) to SDPO for dense correction; entropy-aware weighting further enhances stability.
Empirical Evaluation
Benchmark Results
SRPO is evaluated on five RLVR benchmarks (Chemistry, Physics, Biology, Materials, Tool Use) using Qwen3-8B and Qwen3-4B. Across all settings, SRPO achieves the highest peak accuracy, surpassing GRPO by 3.4–4.5% and SDPO by 6.3–7.5% in five-benchmark averages. SRPO matches the rapid early convergence of SDPO and sustains further gains over long horizons, outperforming both baselines on every benchmark and budget. Notably, in settings where SDPO is unstable, SRPO avoids collapse and remains robust due to routing and down-weighting mechanisms.
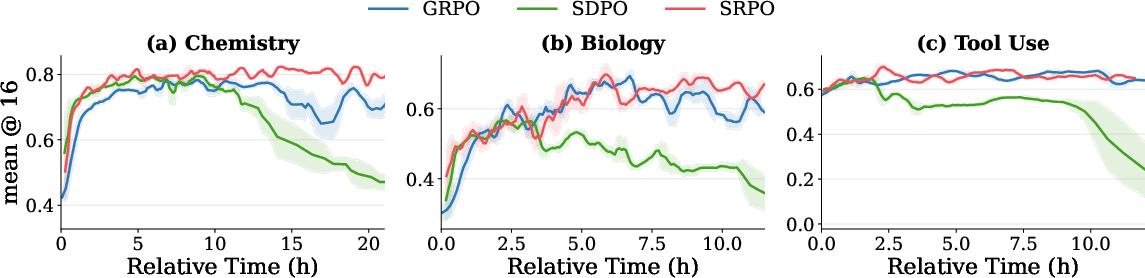
Figure 3: Training curves on Chemistry, Biology, and Tool Use highlight SRPO’s efficiency and stability compared to GRPO and SDPO.
Ablations
Ablation studies disentangle the effects of sample routing and entropy-aware dynamic weighting. Sample routing is shown to be strictly superior to straightforward advantage mixing; SRPO’s design avoids propagating noisy distillation gradients in later training, confining them to instances where positive impact is likely. Entropy-aware weighting further stabilizes optimization, most notably in the late stage, with a 1.8% average accuracy gain at 10 hours over the non-weighted variant.
Response Length and Compute Time
SRPO produces response lengths that are intermediate between verbose GRPO and over-pruned SDPO, addressing concerns about edit distance minimization and epistemic suppression in SDPO. Importantly, SRPO achieves up to 17.2% lower per-step compute time compared to GRPO over long horizons, benefiting from the decreasing share of routed SDPO updates as training progresses.
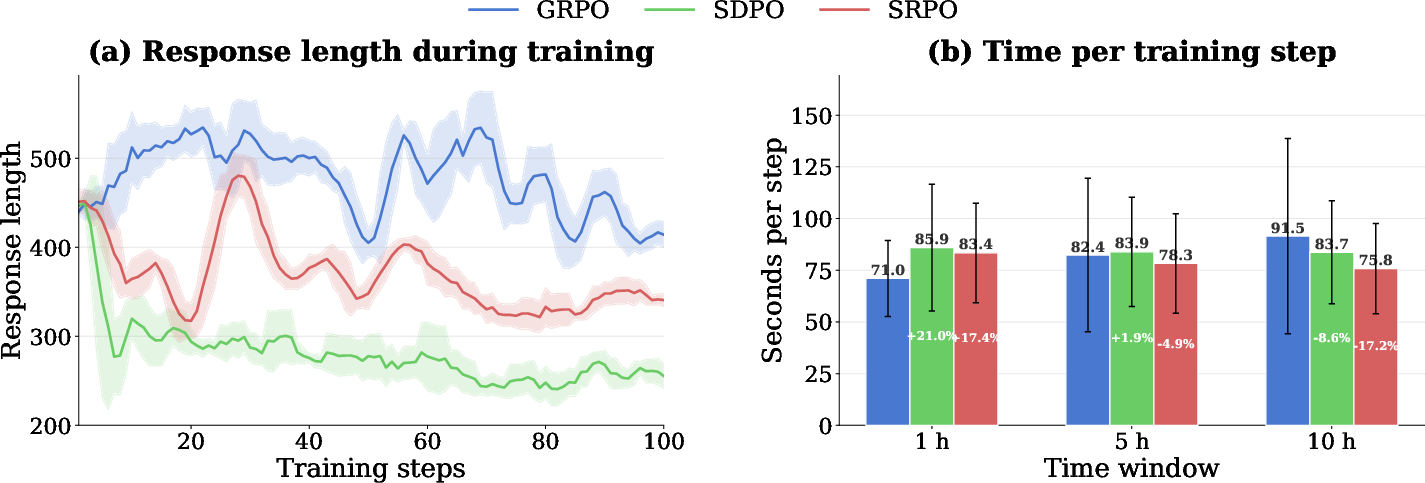
Figure 4: SRPO yields moderate response lengths and achieves favorable per-step compute cost dynamics versus both baselines.
Routing Dynamics
During training, the fraction of rollouts routed through SDPO declines as the policy improves, and the GRPO branch increasingly dominates. This demonstrates that SRPO naturally modulates the use of dense correction in a curriculum-aligned manner, without the need for explicit scheduling.
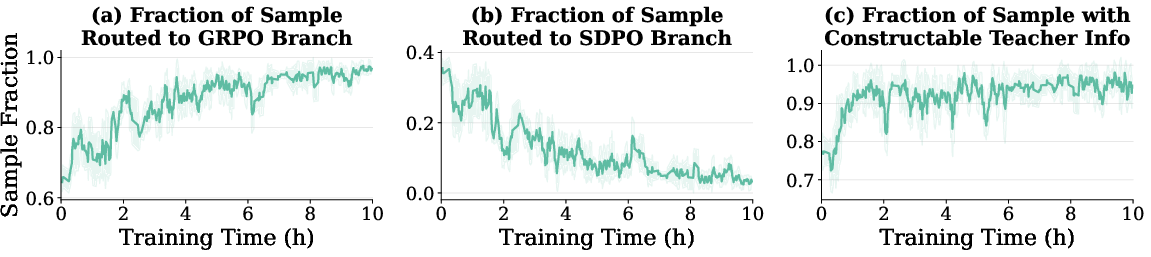
Figure 5: The SDPO branch is highly active early but steadily declines as correctness improves, validating adaptive routing.
Theoretical and Practical Implications
The primary implication is that architectural-level curriculum mixing—sample-wise routing based on correctness and teacher-information—can outperform both static advantage mixing and vanilla sequential fine-tuning for LLM RLVR post-training. This strategy maximizes sample efficiency during early training and guarantees robust convergence by minimizing the propagation of ambiguous or degraded self-teacher signals. Entropy-aware reweighting aligns the influence of SDPO with signal quality, which is crucial for stabilization at scale.
Practically, SRPO’s consistent improvements generalize across model scales and benchmarks without requiring additional reward models or external supervision. The framework’s moderate resource footprint, especially in later epochs, is notable for applied settings targeting efficient and reliable LLM alignment. The decoupling of correction and reward-based updates emerging from SRPO suggests a generalizable principle for hybrid RL/distillation protocols.
Future Directions
SRPO opens directions for evolving RLVR with richer forms of environment or process feedback, potentially extending the self-distillation signal beyond correct sibling sampling to structured execution traces or human-in-the-loop corrections. Adapting the routing or dynamic weighting to more nuanced metrics—such as calibrated epistemic uncertainty or evaluation-on-the-fly—represents fertile ground for even greater robustness and long-horizon sample efficiency. Further work should investigate generalization to tasks with less reliable or noisier reward structures, as well as integration with more complex tool-use or multi-step reasoning environments.
Conclusion
SRPO provides a principled, on-policy unification of reward-driven and self-distillation signals for LLM post-training. By routing updates at the sample level according to outcome and leveraging entropy-aware weighting, SRPO captures the best of both worlds—efficient early improvement and stable long-horizon alignment—while consistently dominating established approaches in empirical benchmarks. The insights and empirical evidence presented support SRPO as a robust paradigm for RL-based LLM post-training, driving both research and deployment advances in grounded, efficient LLM optimization.

