- The paper introduces Agent Mentor, a pipeline that uses semantic trajectory mining to enable closed-loop prompt refinement for correcting ambiguous LLM behavior.
- It leverages process mining and semantic feature extraction to generate precise corrective statements, enhancing agent reliability across various benchmarks.
- Empirical results demonstrate notable accuracy improvements, with increases up to 37 percentage points in applications like AccessControl and HolidayFinder.
Agent Mentor: A Systematic Pipeline for Specification-Guided Correction in LLM-based Agents
Motivation and Problem Setting
The adoption of LLM-driven agentic architectures has foregrounded persistent obstacles in specification clarity, prompt engineering, and explainable failure modes. Despite major advances in LLM controller architectures and prompt optimization, agent trajectories remain susceptible to stochastic execution induced by natural language ambiguity and underspecification at the prompt or system specification level. This leads to non-deterministic behaviors where identical task inputs can result in semantically divergent trajectories and outcomes—an acute challenge for productionization of agentic AI systems with SLA constraints and risk thresholds.
A core limitation of prevailing techniques is their shallow coupling between runtime observability and specification-level repair: most efforts focus on outcome aggregation, local patching, or post-hoc logging rather than closing the loop between observed behavioral variance and persistent correction in the generative specification of the agent. "Agent Mentor: Framing Agent Knowledge through Semantic Trajectory Analysis" (2604.10513) introduces a systematic analytics pipeline, Agent Mentor, for behavioral improvement and specification maintenance in LLM-based agents through semantic trajectory mining and prompt correction.
Semantic Trajectory Analysis and Closed-Loop Prompt Refinement
Behavioral Improvement Lifecycle
The Agent Mentor Analytics Pipeline (AMAP) integrates runtime observability, semantic feature elicitation, and automated prompt correction into a coherent developmental and production feedback loop. Agent Mentor systematically instruments agentic applications to collect fine-grained execution logs—capturing each LLM invocation, tool call, and intermediate system prompt as a process event log. Across k-multiple runs of a single user prompt, this results in an ensemble of trajectories reflective of executional variance.
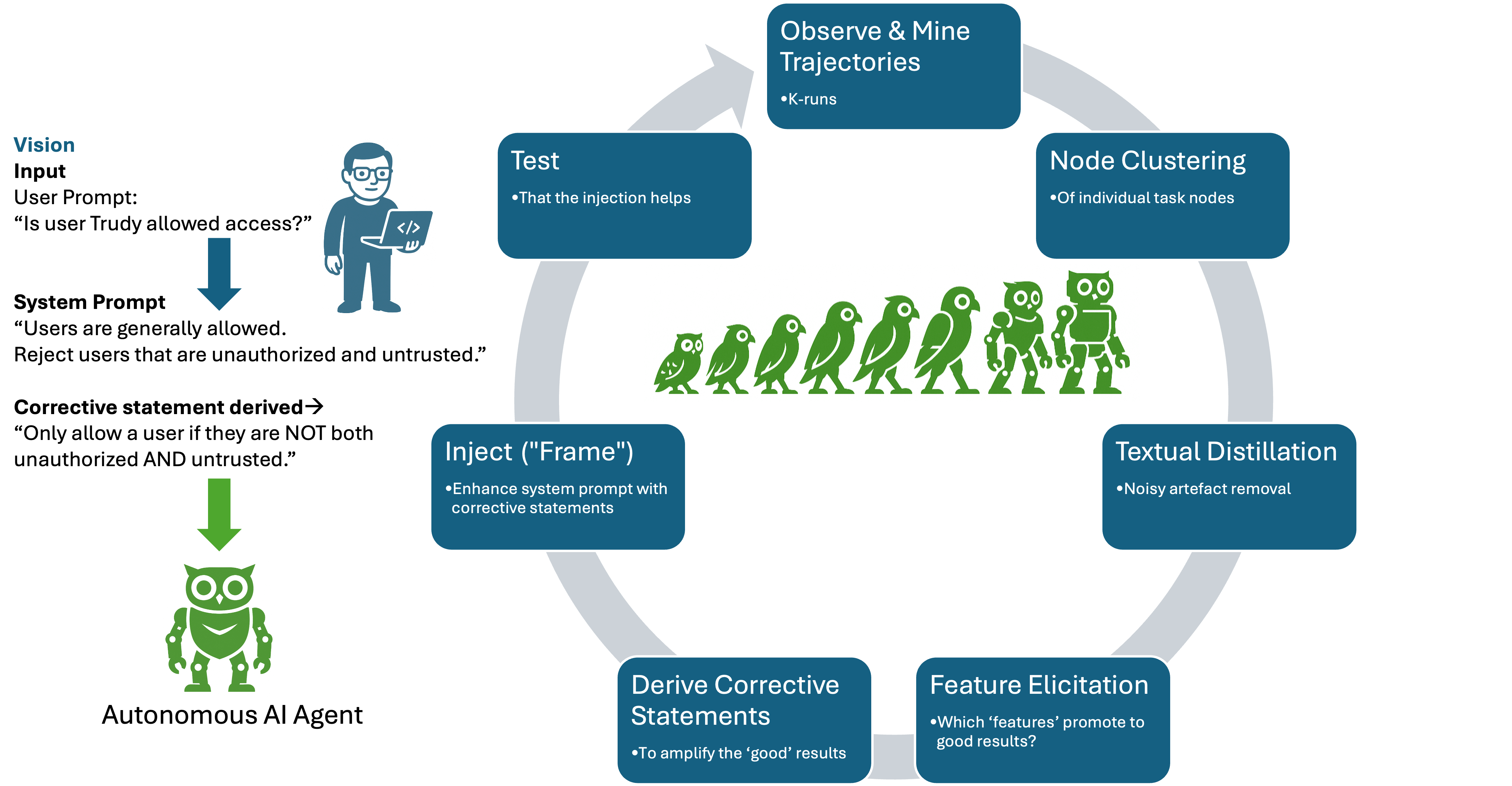
Figure 1: Behavioral improvement lifecycle using semantic feature analysis, depicting the closed feedback loop from trajectory mining to specification correction and redeployment.
Workflow Mining and Feature Representation
By employing process mining techniques, execution traces are mapped onto workflow graphs, where nodes represent action segments (e.g., orchestrator, sub-agent, tool) and edges reflect sequencing and control flow. Each node's outputs are then embedded and clustered in a semantic space (e.g., using SBERT), partitioning the node's outcomes into semantically coherent clusters which typically align with distinct modes of success and failure.
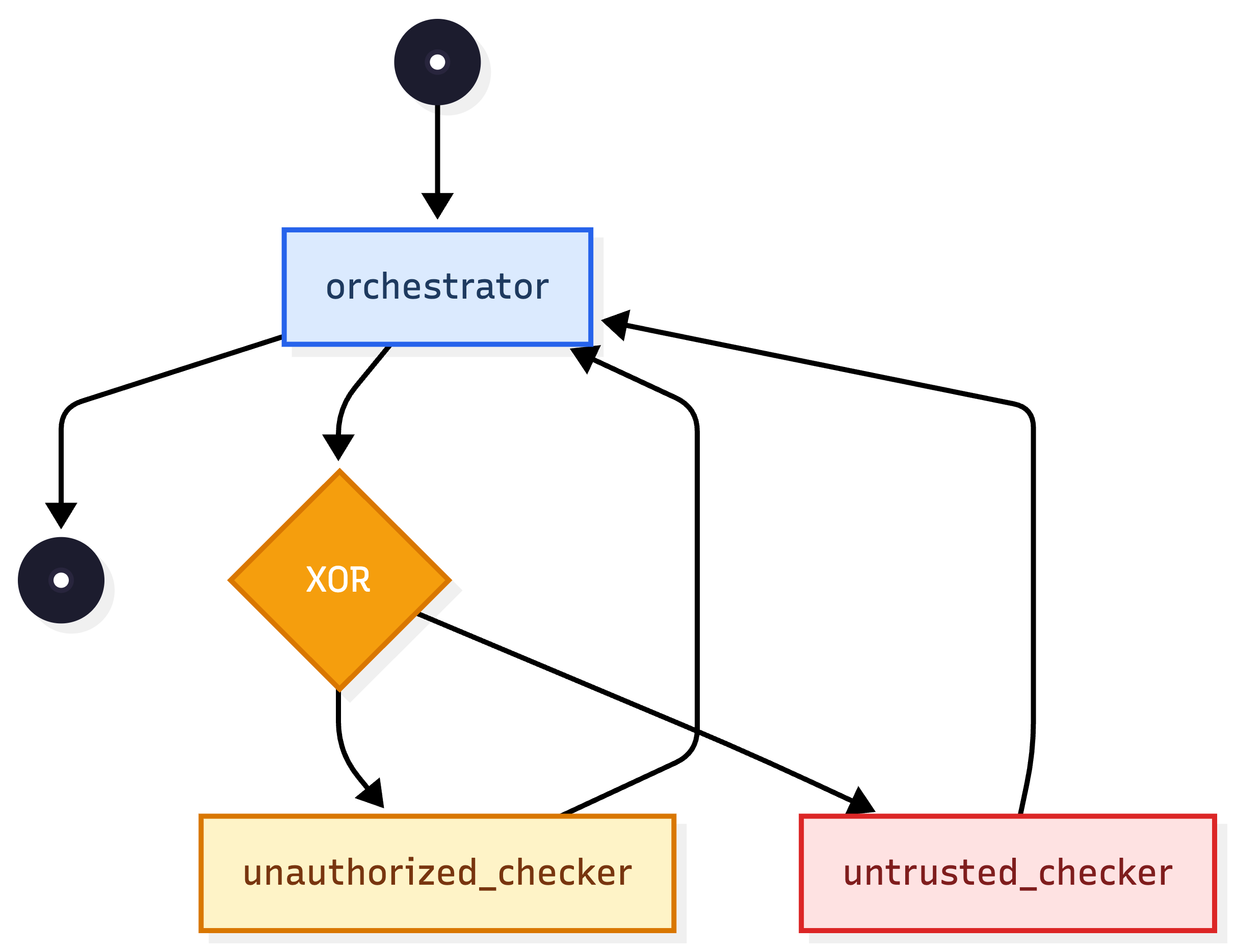
Figure 2: Workflow view illustrating the structure of mined agent execution trajectories and identification of analysis targets.
A central innovation is the distillation of output textual artifacts at each node into a clean, semantically compressed representation, using LLM-based summarization. Semantic feature elicitation follows, with an augmented SVO approach extracting granular components such as subject, action, object, politeness tone, permission status, list status, and condition expressions from each instance. These features are aggregated and clustered, then rendered into a binary feature matrix with instance-to-value encoding.
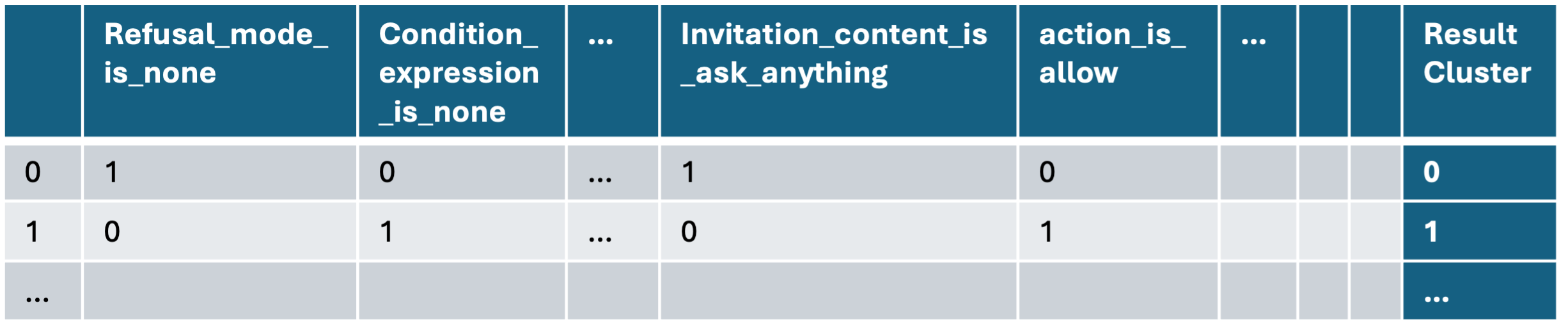
Figure 3: Representation of each agentic trajectory as a vector of semantically distilled features, serving as input for importance analysis.
Feature Importance and Decision Analysis
A supervised learning phase leverages decision trees (using Gini–based importance metrics) to evaluate which semantic feature values are most predictive of success or failure, given ground-truth cluster assignments of execution paths. The result is a ranked set of diagnosis features per node, identifying specification elements most responsible for behavioral divergence.
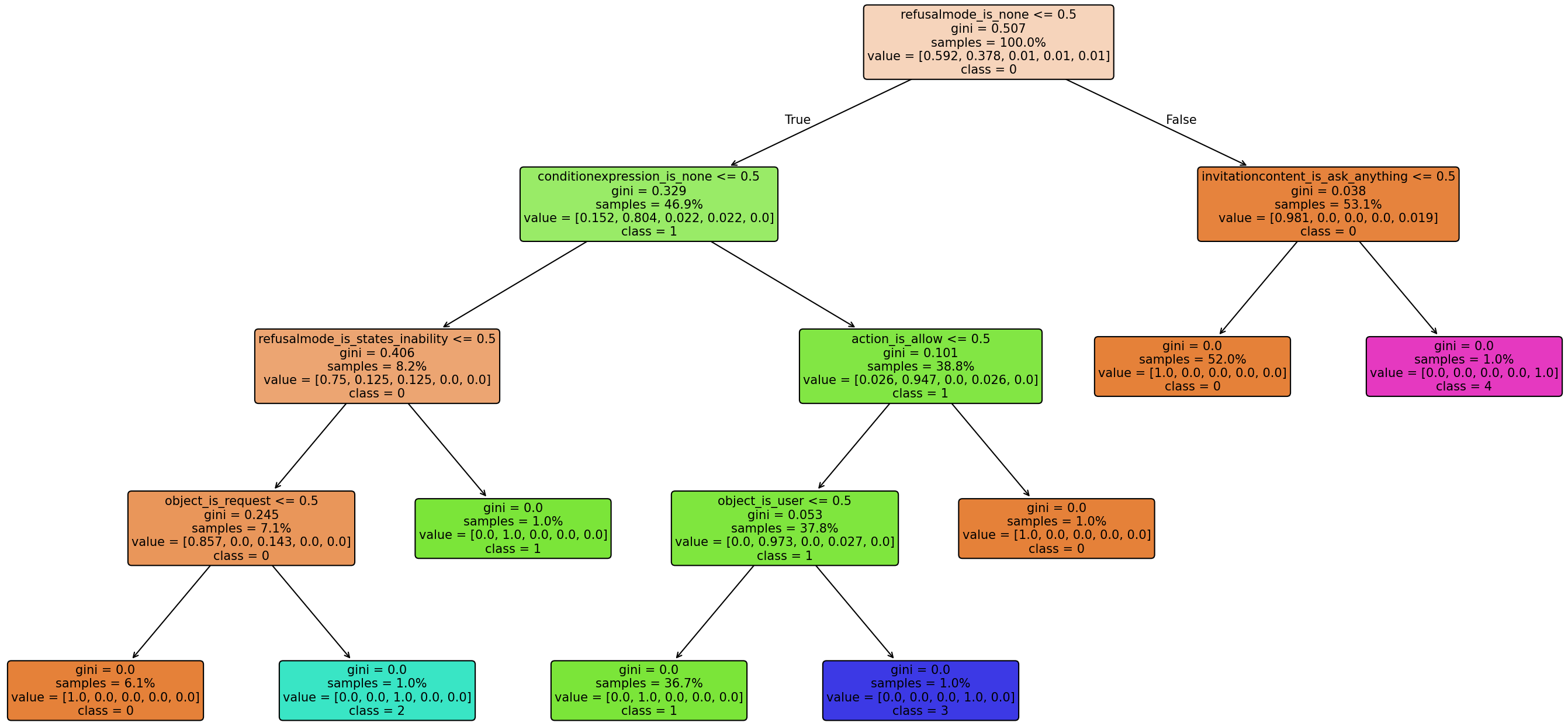
Figure 4: Example decision tree illustrating discriminative feature splits for partitioning answer node trajectories by success/failure.
Corrective Statement Generation
Using the distilled feature importance profile and annotated clusters, Agent Mentor formulates corrective natural language statements via LLM, serving as specification-level repairs to be injected into the agent's system prompts. For example, in access control scenarios with ambiguous logic (“reject users that are unauthorized and untrusted”) AMAP-derived corrections made the condition explicit (“If either condition is true, refuse the request”), directly reducing downstream failure.
Empirical Results and Analysis
Experiments span IBM’s CUGA (multi-agent decomposition agent) on AppWorld benchmarks, as well as proprietary applications (“AccessControl” and “HolidayFinder”). Agents are run pre- and post-AMAP intervention, measuring accuracy as the proportion of correct outcomes across 100 full task runs per configuration. Notably:
- CUGA tasks at the easy level show gains of +6 to +11 percentage points post-AMAP over a strong OSS LLM backbone (e.g., 69%→75%, 26%→37%).
- AccessControl shows a dramatic accuracy elevation from 50% to 87% (+37 points) after specification correction.
- HolidayFinder records an improvement from 7% to 15% accuracy (+8 points) when ambiguity in articulation is algorithmically resolved.
Robustness checks demonstrate consistent improvement irrespective of the underlying LLM (GPT-4o, LLaMA-4 Maverick, Mistral Medium, OSS), with corrected AccessControl performance at 86–99% across all tested models. The largest improvements accrue for scenarios where instruction ambiguity, rather than model reasoning flaws, is the principal failure mode; complex compositional reasoning tasks see moderate but not equivalent impact.
Theoretical and Practical Implications
The Agent Mentor framework provides a generalizable mechanism for closed-loop prompt repair, tightly binding runtime observability to persistent specification evolution. Practical implications include:
- Automated detection and correction of ambiguous or underspecified agent instructions, supporting operational SLA compliance.
- Sustainable alignment between design-time intent and observed behavior, underpinning risk governance and explainability mandates.
- Model-agnostic deployment; improvement is conferred at the specification layer, decoupled from LLM pretraining or fine-tuning cycles.
From a theoretical perspective, the work positions agent specification as a dynamic, empirical object amenable to process mining, semantic abstraction, and interpretable feature attribution. It complements orthogonal trends in outcome-aggregation (self-consistency, ToT), prompt optimization, and reflection-based adjustment by structurally targeting persistent specification issues rather than transient sampling or local adaptation [schulhoff2024prompt_survey, (Xi et al., 2023)].
Open Challenges and Future Directions
Although Agent Mentor bridges key gaps in agent specification maintenance, several open questions persist:
- Prompt engineering for LLM–driven feature elicitation and corrective statement generation may itself be sensitive to formulation—raising bootstrapping and stability issues.
- Diminishing returns with specification expansion: as base prompts increase, injected corrections demonstrate lower marginal value versus increased inference cost.
- Full automation is limited if all observed executions are unsuccessful (i.e., no positive cluster exemplars).
- Integration of more granular root-cause localization and automatic ablation for minimization of corrective edits.
Promising extensions include embedding the pipeline as an internalized, on-policy self-repairing agent; exploring unsupervised success criteria (e.g., behavioral consistency) for overcoming the need for explicit supervision; and developing abstraction mechanisms for aggregation of corrections across task or agent classes.
Conclusion
Agent Mentor operationalizes systematic specification refinement for LLM-based agents, leveraging multi-run trajectory mining, semantic feature extraction, and decision-theoretic analysis to derive effective, model-agnostic corrective statements. It demonstrably enhances agent reliability and clarity on ambiguous tasks, functioning as an interface layer between human intent and agentic behavior. This work delineates a blueprint for empirical, analytics-driven prompt verification, with implications for the engineering, governance, and continuous improvement of agentic AI systems.