- The paper introduces a novel automated framework (AgenTracer) to precisely attribute failures in complex multi-agent LLM systems using counterfactual replay and RL-based training.
- It constructs a high-fidelity dataset via counterfactual replay and programmatic fault injection, addressing the sub-10% accuracy of existing LLMs on failure attribution tasks.
- Integration of AgenTracer shows performance gains up to 14.2% in self-correcting agentic systems, enabling robust error diagnosis even without ground-truth solutions.
AgenTracer: Failure Attribution in LLM Agentic Systems
Introduction
The increasing complexity of LLM-based agentic systems—comprising multiple interacting agents, tool integrations, and orchestration protocols—has led to significant gains in task performance across domains such as code generation, document analysis, and web navigation. However, this sophistication introduces substantial fragility, with empirical studies reporting failure rates as high as 86.7% in popular multi-agent frameworks. The critical challenge addressed in this work is failure attribution: precisely identifying the agent and step responsible for a system-level failure within long, multi-agent execution traces. Existing LLMs, even at the frontier of reasoning capabilities, exhibit sub-10% accuracy on this task, underscoring a major gap in the reliability and self-improvement of agentic AI.
Automated Failure Attribution: The AgenTracer Framework
AgenTracer introduces a fully automated pipeline for constructing large-scale, high-fidelity datasets of annotated multi-agent failure trajectories and a lightweight, RL-trained failure tracer for accurate error localization.
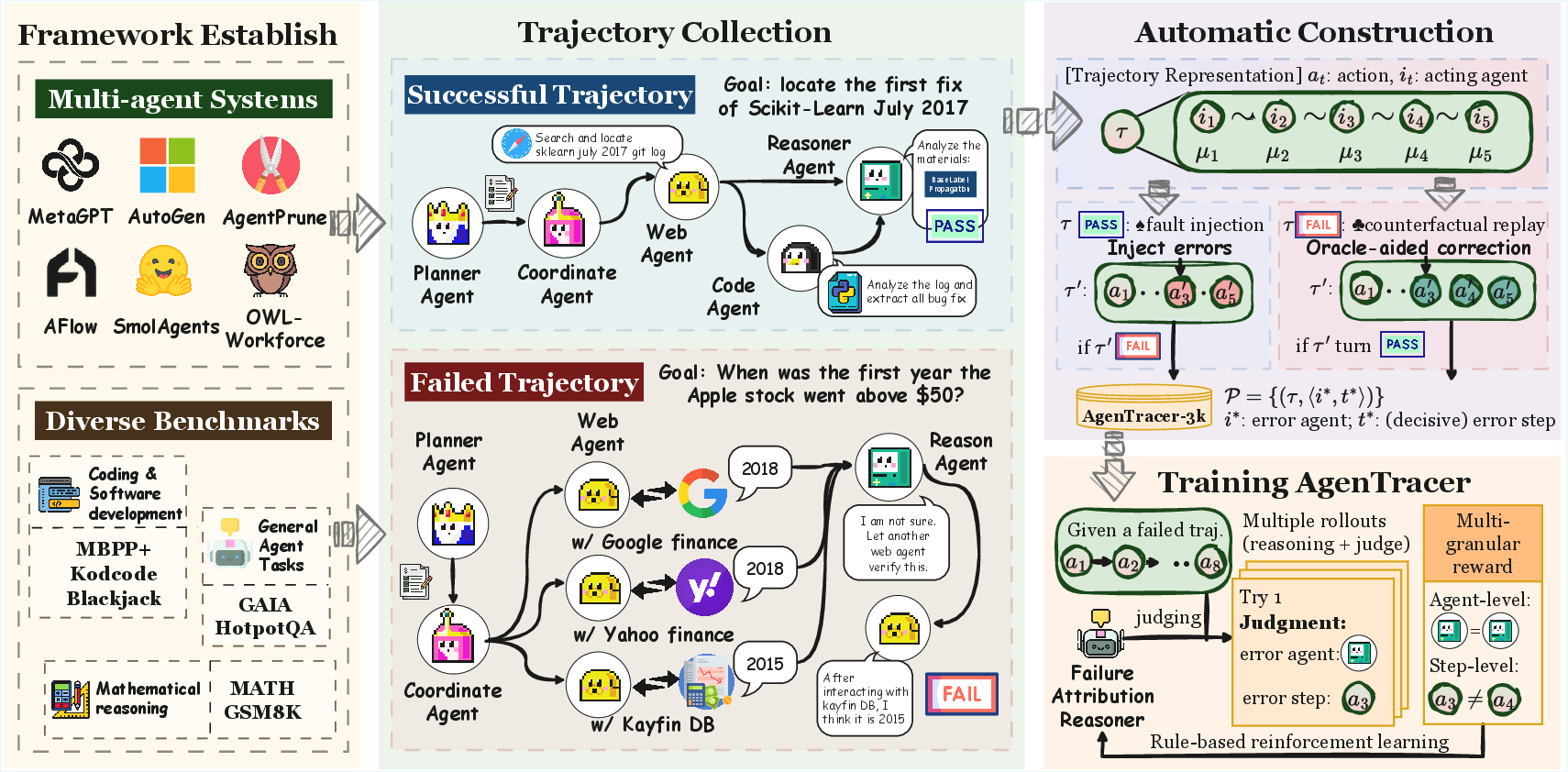
Figure 1: The overview of the proposed AgenTracer framework, including automated trajectory annotation and RL-based failure tracer training.
Dataset Construction via Counterfactual Replay and Fault Injection
The pipeline aggregates trajectories from six representative multi-agent frameworks spanning all automation levels. For failed trajectories, decisive error steps are identified using counterfactual replay: an analyzer agent systematically replaces each agent action with an oracle-corrected alternative and re-simulates the trajectory, labeling the earliest correction that flips the outcome as the root cause. For successful trajectories, programmatic fault injection introduces targeted perturbations at random steps, generating synthetic failures with known decisive errors. This dual approach yields a dataset (AgenTracer-2.5K) of over 2,000 annotated trajectory–error pairs, covering code, math, and general agentic tasks.
RL-based Failure Tracer
AgenTracer fine-tunes a Qwen3-8B backbone using Group Relative Policy Optimization (GRPO) with a multi-granular reward function. The reward combines strict format compliance, agent-level binary correctness, and a step-level Gaussian kernel for temporal proximity to the true error. This design stabilizes RL training and ensures outputs are reliably parsable and actionable.
Empirical Evaluation
AgenTracer is evaluated on the Who{content}When benchmark and held-out splits of the constructed dataset, using both agent-level and step-level accuracy metrics. The evaluation includes both settings with and without access to ground-truth solutions.
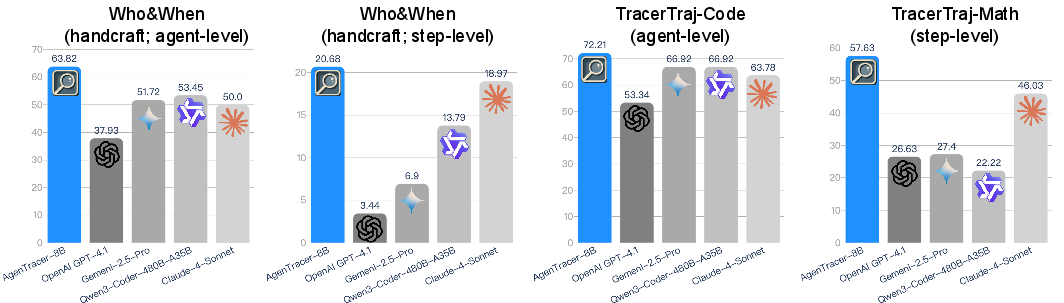
Figure 2: Benchmark performance comparison between AgenTracer and leading industry providers.
Key Results
- Prevailing LLMs are inadequate for failure attribution: Step-level accuracy for models such as Qwen3-8B, Llama-3.2-3B, and even DeepSeek-R1 remains below 10% on handcrafted benchmarks. Larger models (e.g., GPT-4.1, Claude-4-Sonnet) achieve only 21–40% step-level accuracy.
- AgenTracer consistently outperforms proprietary LLMs: On Who{content}When (handcrafted), AgenTracer achieves 20.68% step-level accuracy, surpassing Claude-4-Sonnet by 1.71x. On the automated subset, it reaches 42.86%, outperforming DeepSeek-R1 and Gemini-2.5-Pro by 11.54% and 13.34%, respectively.
- Robustness without ground-truth access: AgenTracer maintains high accuracy even without access to ground-truth solutions, with only marginal drops compared to the w/ ground-truth setting, unlike other models that degrade significantly.
Practical Impact: Enabling Self-Correcting Agentic Systems
AgenTracer's actionable feedback enables direct integration with mainstream multi-agent systems (e.g., MetaGPT, MaAS, OWL Workforce), facilitating multi-turn self-improvement.
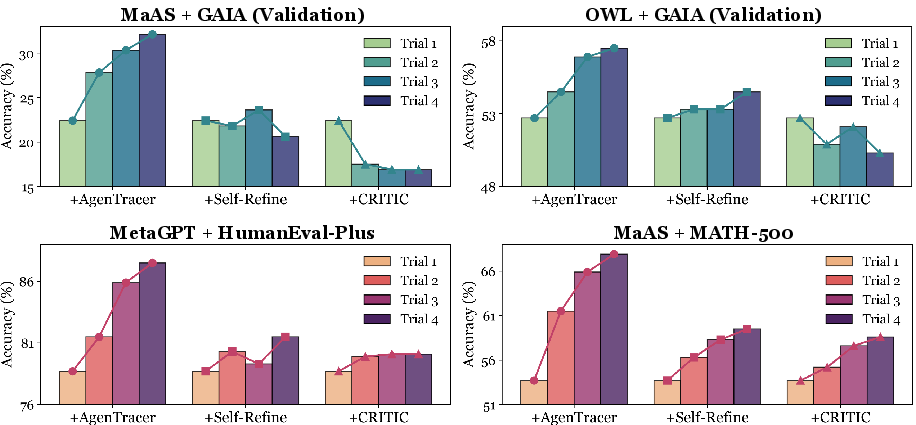
Figure 3: The multi-turn improvement performance brought by AgenTracer compared with classical agent reflection baselines, Self-Refine, and CRITIC.
- Performance gains of 4.8–14.2% are observed when AgenTracer's feedback is injected into agentic systems, whereas classical reflection-based methods (Self-Refine, CRITIC) often fail to improve or even degrade performance.
- Generalization to unseen systems and domains: AgenTracer's improvements are consistent across both seen and unseen agentic frameworks and benchmarks, demonstrating strong transferability.
Qualitative Analysis: Attribution in Long-Horizon Tasks
AgenTracer demonstrates superior diagnostic granularity in complex, long-chain tasks.
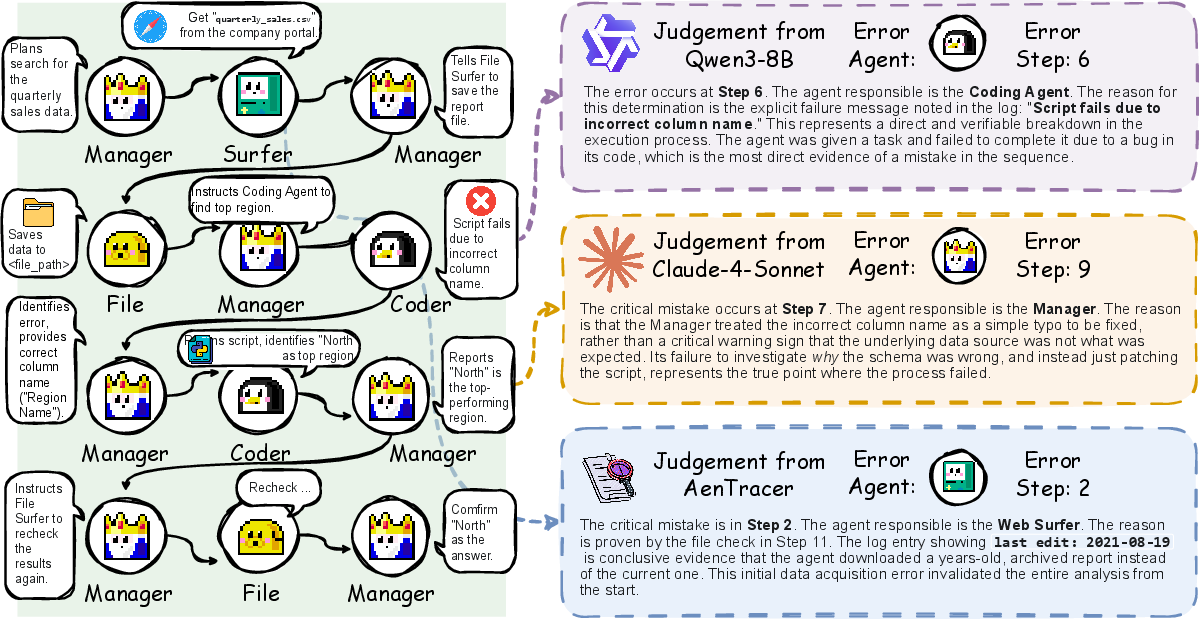
Figure 4: Case study of failure attribution in a long-chain document analysis task, comparing Qwen3-8B, Claude-4-Sonnet, and AgenTracer.
- Early, subtle error detection: AgenTracer identifies root causes originating early in the trajectory (e.g., incorrect file retrieval at Step 2), which are missed by both smaller and larger LLMs that focus on surface-level execution errors.
- Actionable explanations: The model provides structured, interpretable rationales, facilitating targeted debugging and system retraining.
Theoretical and Practical Implications
AgenTracer advances the state of agentic system reliability by providing a scalable, automated approach to failure attribution. The counterfactual replay and programmatic fault injection methodology enables the construction of large, diverse, and high-precision datasets, addressing a major bottleneck in agentic system evaluation and improvement. The RL-based tracer, with its multi-granular reward, demonstrates that targeted post-training can yield specialized diagnostic capabilities that general-purpose LLMs lack, even at much larger scales.
The results challenge the assumption that larger LLMs or access to ground-truth solutions are sufficient for robust failure attribution. Instead, domain-specific training and reward shaping are critical. The demonstrated performance gains in self-correcting agentic systems suggest a path toward autonomous, self-evolving AI collectives with reduced human intervention in debugging and retraining.
Future Directions
- Scaling to more complex, open-ended environments: Extending the counterfactual annotation pipeline to tasks with non-deterministic or partially observable outcomes.
- Integration with agentic credit assignment and reward modeling: Leveraging failure attribution for more efficient RL and meta-learning in multi-agent settings.
- Automated system design and orchestration: Using attribution signals to inform agent selection, role assignment, and communication topology in evolving agentic architectures.
Conclusion
AgenTracer establishes a principled, automated framework for failure attribution in LLM-based agentic systems, achieving substantial improvements over both open and proprietary LLMs in diagnostic accuracy and practical system improvement. The approach enables actionable, fine-grained feedback for self-correcting multi-agent AI, marking a significant step toward resilient, autonomous collective intelligence.

