- The paper introduces a tuning-free, optimization-free pipeline that enables high-resolution image editing through tiled DDIM inversion and kernel-dilated sampling.
- The method uses NDCFG++ to balance unconditional and conditional noise outputs, nearly doubling ImageReward and CLIPScore at 16× scaling.
- The approach demonstrates robust semantic preservation while mitigating artifacts like object repetition and patch seams, validated via user studies and ablation experiments.
EditCrafter: Tuning-Free High-Resolution Image Editing via Pretrained Diffusion Models
Motivation and Background
Recent advances in large-scale text-to-image (T2I) diffusion models, such as Stable Diffusion (SD) and Imagen, have significantly improved the synthesis and editing of images guided by text prompts. Despite their success, such models remain fundamentally limited to their training resolutions (typically 512×512 or 1024×1024). Scalable, high-resolution image editing remains an open challenge, especially given the tendency for naive patch-wise approaches to yield undesirable artifacts, such as object repetition and seam discontinuities. Prior strategies, including joint patch-wise diffusion [Kim:2023CSD], alleviate some issues but introduce constraints regarding semantic consistency and scalability.
Methodology
EditCrafter proposes a tuning-free, optimization-free pipeline for text-guided high-resolution image editing using only standard pretrained diffusion models. The method is grounded in the following key algorithmic innovations:
- Tiled DDIM Inversion: High-resolution images are divided into tiles matching the model's native training resolution. Each tile undergoes independent DDIM inversion (with guidance scale set to zero) to obtain the corresponding latent representations, which are then concatenated to form an edit-friendly, high-resolution latent embedding that preserves the original content identity.
- Kernel Dilated High-Resolution Sampling: Following the concepts of ScaleCrafter [he2023scalecrafter], kernel dilation is applied to the U-Net in the diffusion model to adapt its receptive field, enabling generative and editing operations at arbitrary spatial scales without architectural re-training.
- Manifold-Constrained Noise-Damped Classifier-Free Guidance (NDCFG++): To address excessive guidance-induced artifacts, EditCrafter introduces NDCFG++, which interpolates between unconditional and conditional (text-guided) noise estimates with a small scale parameter λ∈[0,1]. For early sampling steps, NDCFG++ utilizes unconditional noise from the vanilla estimator for better stability and semantic preservation, switching to standard classifier-free guidance in late steps. This approach preserves the semantic integrity of the input and achieves spatial and object-level coherence during high-resolution editing.
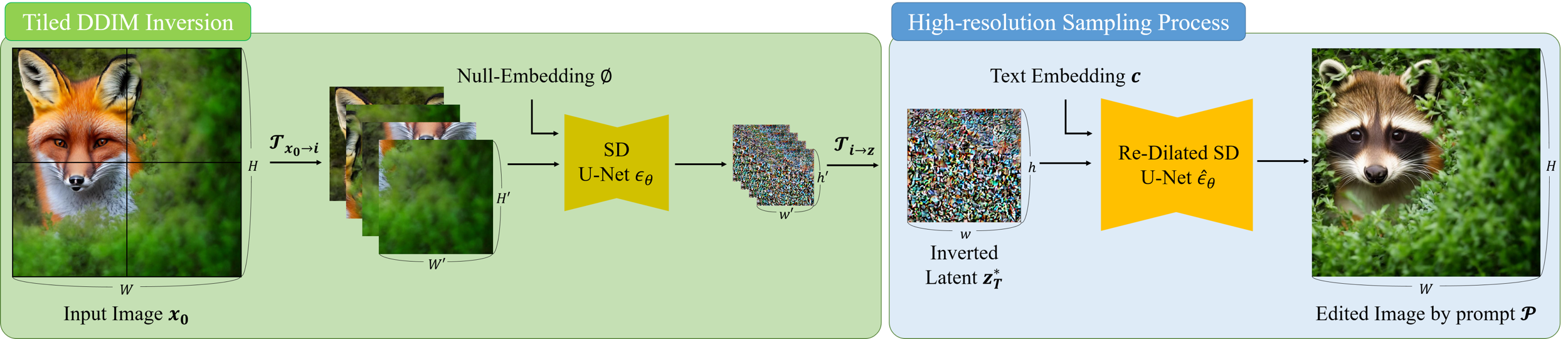
Figure 1: The overview of the EditCrafter pipeline, combining tiled DDIM inversion and NDCFG++ for seamless, high-resolution editing.
Experimental Evaluation
Experimental Setup and Benchmarks
Experiments are conducted across multiple upscaling factors (4×, 8×, 16×), corresponding to target resolutions of up to 4096×4096 on datasets curated from high-fidelity generation models. Comparative baselines include CSD [Kim:2023CSD] and pipelines combining state-of-the-art editing (e.g., InfEdit) with super-resolution upsamplers (e.g., StableSR).
Quantitative Results
EditCrafter achieves superior alignment with editing prompts and user preferences at all tested resolutions. Specifically, the method nearly doubles ImageReward and CLIPScore metrics over CSD at 16× scale. Human evaluation further demonstrates robust perceptual fidelity and semantic control, with users preferring EditCrafter over CSD in over 72% of cases.

Figure 3: Qualitative comparisons at 4×, 8×, and 16× scaling — EditCrafter avoids object repetition and patch seams compared to CSD.

Figure 2: EditCrafter versus InfEdit+StableSR for 16× scaled editing. EditCrafter achieves finer structural fidelity and more accurate semantic edits.
Qualitative Analysis
Figures throughout the study reveal consistent preservation of fine-grained details, object identities, and seamless integration across tiles. Unlike prior methods, EditCrafter robustly avoids object repetition and erroneous patch boundaries, yielding semantically consistent edits as resolution increases.
Ablation Studies
Careful ablations highlight the criticality of the NDCFG++ mechanism. Removing NDCFG++ or adopting purely generative guidance (as in ScaleCrafter) degrades both perceptual and quantitative performance: objects are misplaced, and semantic fidelity to editing prompts is diminished. NDCFG++ achieves optimal tradeoff by modulating guidance in early steps, as shown both qualitatively and in alignment metrics.

Figure 4: Ablation results on NDCFG++ — omitting NDCFG++ leads to less accurate semantic edits and degraded structural integrity.
Classifier-Free Guidance Scale Analysis
Systematic exploration of the guidance scale λ demonstrates its influence: increasing λ strengthens prompt alignment but can jeopardize faithfulness to the original input. Empirically, λ=0.5 is found to yield optimal trade-offs. This tunability allows EditCrafter to meet diverse application requirements, from subtle retouching to more radical semantic modifications.

Figure 5: The effect of classifier-free guidance (CFG) scale λ on prompt fidelity and content preservation.
User Study
Extensive user studies confirm the practical benefits of EditCrafter, with participants consistently preferring its outputs to those of CSD, InfEdit+SR, and ProxEdit+SR. The unified editing approach notably excels in matching user expectations for both semantic accuracy and preservation of high-resolution input features.
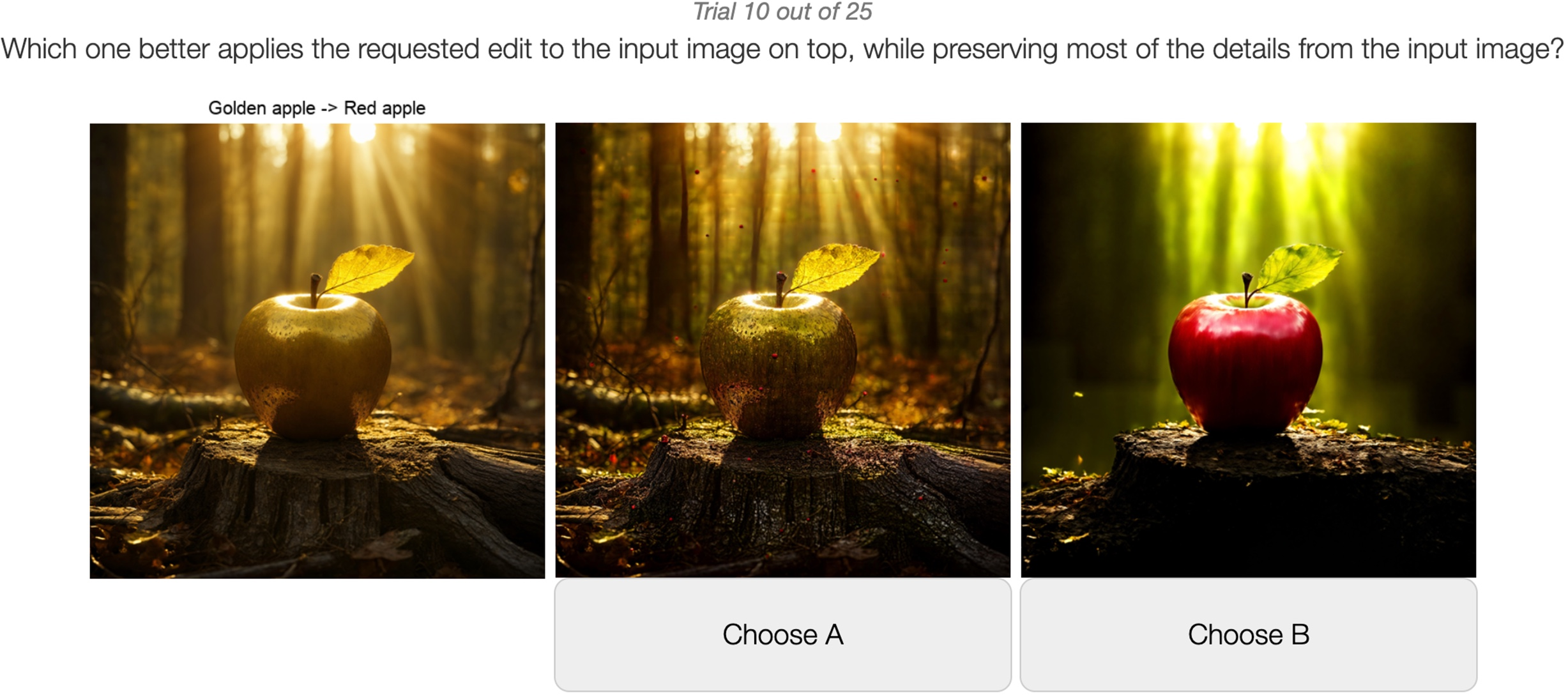
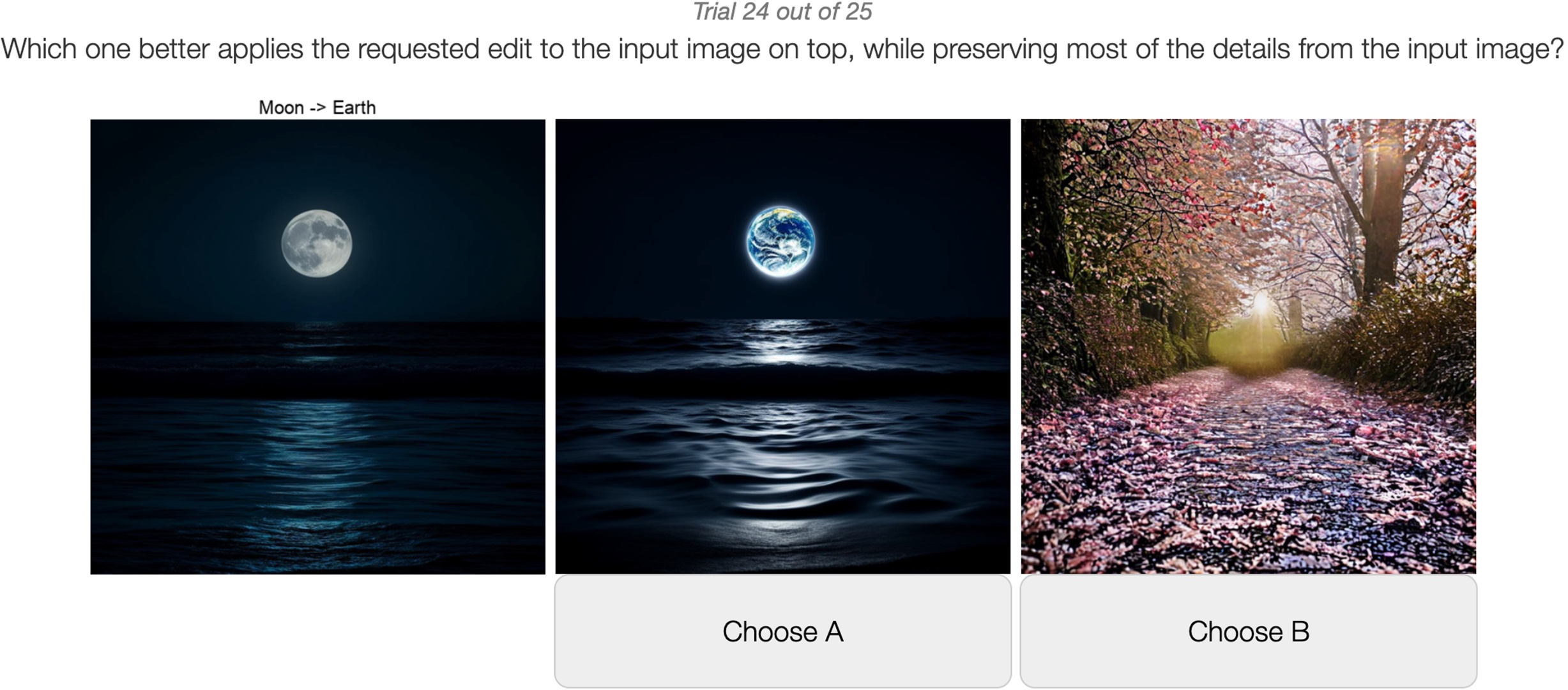
Figure 6: Example user study interfaces demonstrating comparative evaluation setup.
Implications and Future Directions
EditCrafter establishes that it is feasible to repurpose off-the-shelf pretrained T2I diffusion models for high-resolution image editing without any model fine-tuning or external optimization. This contributes a significant leap in scalability, democratizing high-fidelity editing previously limited by fixed model architectures. The method’s pipeline is broadly compatible with most latent diffusion models and is extensible to future architectures supporting kernel dilation and classifier-free guidance.
From a theoretical standpoint, the manifold-constrained guidance approach establishes a more principled trade-off between prompt adherence and content preservation, which can inspire further research in controllable generative modeling. In practical terms, EditCrafter offers immediate utility for applications in content creation, industrial design, and any setting where real-world high-resolution edits are essential.
Prospective developments may include the integration with video and 3D volumetric editing, extension to multimodal prompt conditioning, and further efficiency optimizations for real-time, high-resolution deployment.
Conclusion
EditCrafter introduces an effective, tuning-free pipeline for high-resolution text-guided image editing, achieving strong performance across both quantitative and qualitative axes without modifying the underlying pretrained diffusion models. Its combination of tiled inversion and manifold-constrained guidance sets a new standard for scalable, semantically controlled image editing at arbitrary resolutions, and paves the way for further research and practical advances in large-scale generative visual manipulation.

