- The paper presents a training-free, inversion-free method that leverages visual context integration and posterior-guided concept alignment to preserve image fidelity.
- It employs multi-modal diffusion transformers and flow-based sampling to bypass expensive training while achieving superior LPIPS, DINO, and CLIP metrics compared to baselines.
- The approach eliminates the need for explicit masks, enabling fine-grained control and practical deployment across diverse image editing tasks.
Training-Free Image Editing with Visual Context Integration and Concept Alignment
Introduction and Motivation
Semantically controllable image editing remains a fundamental task in visual content creation, where precise manipulation of image regions according to user input is required without sacrificing fidelity in non-target regions. While text-based editing via diffusion models has rapidly advanced, the inherent ambiguity of textual prompts persists, limiting accuracy in fine-grained and context-specific modifications. Recent models address this by conditioning on a visual context image, but they rely on computationally intensive training and data curation pipelines. Training-free methods offer a potential solution by leveraging pretrained diffusion models, but their reliance on diffusion inversion introduces inconsistencies, especially in transferring source and context details and requiring explicit user-provided masks, which impairs flexibility.
The paper introduces VicoEdit, a training-free, inversion-free context-aware image editing method. VicoEdit directly manipulates the source image using the visual context, leveraging multi-modal diffusion transformers (MMDiT) and a novel concept alignment mechanism grounded in posterior sampling. The approach circumvents the training and data costs of existing multi-reference editing frameworks, avoids the fidelity loss associated with diffusion inversion, and eliminates the requirement for explicit editing masks.
Methodology
Inversion-Free Visual Context Integration
VicoEdit expands on the FlowEdit framework, combining the inverse and forward (sampling) velocity fields of pretrained flow-based diffusion models to define a direct path from the source image latent to the target image latent. At each timestep:
- Source Image (ztisrc): Computed via the flow model conditioned only on the source prompt.
- Target Latent (ztitar): Aggregates features from both the diffusion-initialized latent and the visual context embedding, conditioning via the MMDiT attention blocks.
- Unified Velocity Field (v~ti): The difference between the target and source velocity fields, estimated over K noise samples for stability.
This process preserves the latent features of the source image and integrates context features without requiring explicit inversion or masking, directly enabling conditional generation for context-aware editing.
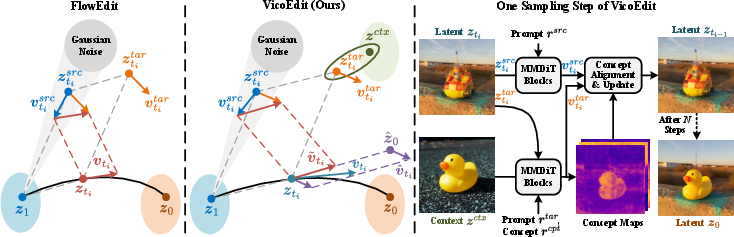
Figure 1: Left: FlowEdit pipeline overview; Middle: VicoEdit's latent, velocity, and sampling arrangement; Right: Detailed breakdown of each VicoEdit sampling step.
Posterior-Guided Concept Alignment
Conventional context integration tends to result in drift from unedited regions of the source image, particularly when strong context signals dominate. To address this, VicoEdit introduces a posterior-guided concept alignment mechanism:
- Unmodified regions are detected using concept classification, leveraging text-image attention scores to segment concepts into 'preserve' and 'modify' sets.
- At each sampling step, a mask mt is computed that identifies these regions.
- Diffusion Posterior Sampling (DPS) then introduces a guidance term v^ti to the velocity update, which ensures that the latent retains high fidelity to the source in unmodified regions, based on the computed concept mask.
Empirical visualization demonstrates that concept alignment preserves detail and structure far more reliably than context-free approaches.

Figure 2: Comparison of editing results with and without concept alignment: concept alignment preserves source image details.
Sampling Strategy
The sampling regime in VicoEdit does not skip early steps, contrary to prior approaches, ensuring that both global features and fine-grained subject characteristics from the visual context are transferred. Multiple velocity samples are averaged per step, and the guidance scale and aggregation threshold are hyperparameters tuned for optimal consistency and context integration.
Experimental Evaluation
Baselines and Protocol
Experiments employ VicoEdit on leading pretrained editing backbones: FLUX.1-Kontext, Qwen-Image-Edit, and Ovis-U1. Comparison is drawn with:
- Training-based, context-aware models: FLUX.2, Qwen-Image-Edit-2511.
- Training-free, context-aware baseline: Diptych Prompting.
- Closed-source commercial editors: Seedream 5.0 Lite, Nano Banana 2.
Evaluation is conducted on the DreamBooth dataset with tasks spanning in-domain replacement, in-domain addition, and cross-domain addition of semantic content.
Quantitative Results
VicoEdit outperforms all open-source models—including both training-based and training-free baselines—in terms of both LPIPS (structure preservation) and DINO/CLIP (subject and instruction following) metrics. Specifically, FLUX-based VicoEdit surpasses FLUX.2 and Qwen-2511 in all major metrics, with much lower model and hardware requirements compared to FLUX.2, which exceeds 80GB of VRAM at inference.

Figure 3: Source image, context image, and editing results of FLUX.2, Qwen-2511, and VicoEdit approaches.
On par with commercial methods, VicoEdit provides close or superior scores in structure preservation and textual alignment, while slightly lagging in context similarity in some settings, without any proprietary data or model pretraining.
Qualitative Analysis
Qualitative results validate that VicoEdit consistently blends source image fidelity with effective contextual insertion—even in cross-domain and style-harmonizing cases—while baseline models either introduce unnecessary changes or cannot faithfully transfer context details.

Figure 4: VicoEdit and ablated variants demonstrate the importance of inversion-free editing and concept alignment for high-fidelity, context-consistent results.
Complexity
VicoEdit's inference cost, while slightly higher than baseline generation due to velocity averaging and gradient-based posterior guidance, remains manageable for practical deployment. Ablation experiments indicate that increasing the number of velocity samples (K) and careful tuning of DPS parameters leads to moderate increases in computational load with corresponding gains in output quality.
Ablation Studies
- Inversion-free vs. Inversion-based: The inversion-free variant demonstrates substantially improved preservation of structure and details over any inversion-dependent setting.
- Concept alignment: Disabling concept alignment leads to noticeable fidelity and consistency degradation, especially in complex (cross-domain) edits.
- Sampling strategy: Skipping initial sampling steps or reducing the number of velocity field samples undermines context integration and overall faithfulness.
Implications and Future Directions
VicoEdit confirms that high-quality, context-aware image editing is feasible without training or data curation, provided that (1) an inversion-free, flow-based conditional synthesis pipeline is employed, and (2) concept-driven posterior guidance is used to localize fidelity preservation. This paradigm shift unlocks rapid, resource-light development cycles and offers interpretability via velocity field decomposition, unlike classical conditional generation.
Practically, these methods can serve as flexible post hoc editors for existing diffusion backbones, or operate as synthesizers for generating high-quality labeled editing pairs for training next-generation conditioning or multimodal models. Theoretically, the work highlights the value of explicit flow-based modeling and latent space manipulation for controllable, modular image generation.
Anticipated future developments include tighter integration of concept alignment within large-scale, multi-subject diffusion backbones, adaptive and user-driven concept specification, and efficient distillation of VicoEdit's masking and guidance mechanisms for even lower-latency applications.
Conclusion
VicoEdit provides a training-free, inversion-free, and mask-free solution for visual context-aware image editing, combining rectified flow-based sampling and concept-aligned posterior guidance. Empirical and theoretical results demonstrate that fidelity, flexibility, and context consistency can be achieved without incurring the prohibitive cost of data collection and pretraining. VicoEdit sets a new baseline for future research into training-free multimodal foundational models and real-world image editability.

