- The paper introduces a novel, training-free framework that leverages bottleneck patching and negative classifier-free guidance to overcome limitations in low-level perceptual editing.
- It extracts degradation concept vectors and adjusts U-Net activations during reverse diffusion to significantly improve metrics like FID, sharpness, saturation, and contrast.
- Quantitative and qualitative results demonstrate robust performance across datasets, with human evaluations preferring the method in over 76% of comparisons.
Guidance for Low-Level Perceptual Editing in Unconditional Diffusion Models
Introduction
The paper "Guidance for Low-Level Perceptual Editing in Unconditional Diffusion Models" (2605.31162) addresses the capability gap in unconditional diffusion models regarding controlled, fine-grained modification of low-level perceptual image attributes—including sharpness, contrast, and saturation—at inference time. Prior approaches primarily involve h-space (U-Net bottleneck) manipulation for structural and semantic editing, yet these techniques systematically fail for low-level, global transformations due to intrinsic non-linearities in the U-Net decoder. The authors propose a novel, training-free inference framework that combines bottleneck patching with classifier-free guidance to steer generation away from the "degraded" manifold associated with blur, low contrast, and grayscale, without retraining or finetuning the generative model. This framework generalizes beyond perceptual to semantic editing, is robust across datasets, and achieves strong improvements in both quantitative and human preference evaluations.
Methodological Framework
The method is instantiated on pre-trained, unconditional diffusion backbones and operates as follows:
- Extraction of Degradation Concept Vectors: For each class of perceptual degradation (e.g., blur, low contrast, grayscale), a canonical direction in h-space is computed as the mean activation difference between clean and degraded image pairs at a selected denoising timestep.
- Inference Activation Patching: During reverse diffusion, the U-Net bottleneck activations are intercepted and shifted along the learned degradation direction to simulate structural refinements.
- Negative Classifier-Free Guidance: To oppose the targeted degradation, classifier-free guidance is applied with the guidance sign reversed. This steers generation away from the degraded manifold by exploiting the contrast between standard and patched noise prediction trajectories.
This composite process produces output with enhanced aesthetic and perceptual quality, as visually demonstrated by improved sharpness and reduced artifacts.






Figure 1: The proposed method yields sharper details and fewer artifacts than the baseline across multiple degradation scenarios.
The overall workflow is encapsulated in an inference pipeline that, post extraction of concept vectors, injects the patch and updates the reverse diffusion trajectory using modified noise predictions.
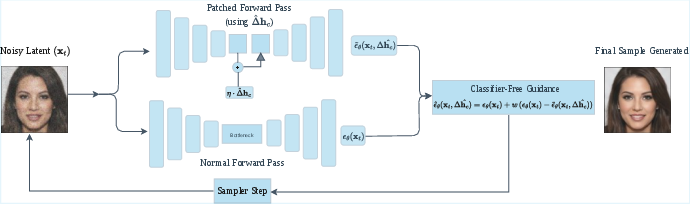
Figure 2: Schematic of the inference-time editing framework, combining bottleneck patching and classifier-free guidance via learned concept vectors in h-space.
Quantitative and Qualitative Results
Comprehensive experiments validate the superiority of the proposed method over standard activation patching and baseline sampling. Evaluation metrics encompass FID for generative quality and direction-specific measures: Laplacian variance (sharpness), mean S-channel (saturation), and RMS contrast.





















Figure 3: Visual comparison among Baseline, Standard Patching, and the proposed method across sharpness, saturation, and contrast; CFG guidance scale was fixed at +1.5 for all samples.
Key quantitative results include:
- Sharpness direction: FID improved by 6.07%, Laplacian variance increased by >2.7x compared with baseline.
- Saturation direction: FID improved by 7.76%, mean S-channel increased.
- Contrast direction: FID improved by 13.90%, RMS contrast significantly higher than all baselines.
Human evaluation substantiates these numerical findings; raters preferred this method in 76% of pairwise comparisons for sharpness and similarly high rates for the other concepts.
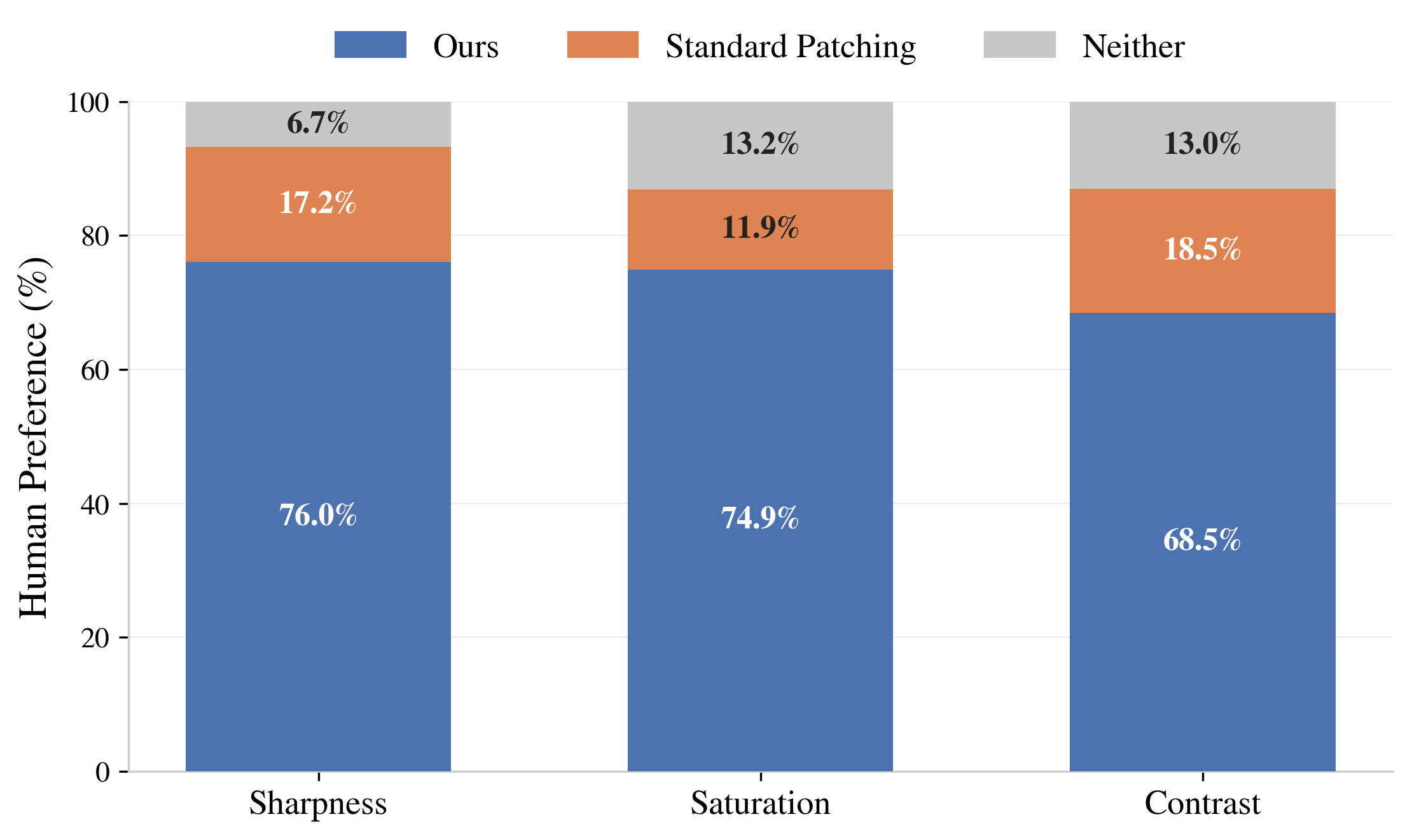
Figure 4: Human preference percentages, showing consistent favor for the proposed method across all low-level attribute editing scenarios.
Failure Modes of Prior Approaches
The authors provide a mechanistic explanation for the failure of standard negative-direction patching in low-level perceptual edits. Linearly manipulating h-space activations in the negative direction (towards "clean") causes non-linear destructive interference within the decoder, destabilizing noise prediction and degrading sample quality. This is quantified by the "relative residual ratio" metric (ρ), which exceeds unity under negative patching, indicating that higher-order decoder responses oppose the intended patching direction.
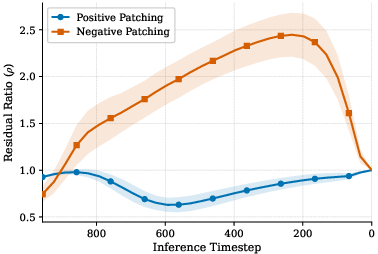
Figure 5: Relative residual ratio ρ across denoising timesteps for the blur (sharpness) direction; positive patching maintains ρ<1, unlike negative patching.
This phenomenon underscores that classical latent-space editing is unreliable for global perceptual attributes due to the non-linear alignment between patched latent codes and unpatched skip connections in the U-Net architecture.
Ablations, Extensions, and Generality
The method demonstrates strong cross-domain generalizability, performing consistently on LSUN Church and on semantic editing directions, such as "smiling" and "male" attributes. It maintains sample quality and feature preservation, surpassing or matching existing patching baselines. The framework is also compatible with partial (late-timestep) guidance strategies, drastically reducing the requisite compute while preserving directional editing efficacy.






Figure 6: Qualitative comparison on LSUN Church (blur direction), with the proposed method yielding superior structural fidelity versus baselines.



Figure 7: Editing along semantic directions, where the method better maintains high-level image structure compared to patching alone.
The approach's generality is tied to its design: guidance via negative classifier-free signal for degradation avoidance is broadly applicable to any attribute whose latent representation is linearly discriminable in h-space.
Practical and Theoretical Implications
Practically, this inference-time, training-free paradigm unlocks new capabilities for rapid, high-fidelity image refinement in conditional and unconditional settings. The methodology is readily extendable to multi-object or multi-attribute control and can be adapted to text-conditional diffusers or flow-based generative architectures. Theoretically, the analysis provides a precise characterization of the U-Net decoder's sensitivity to non-linear latent perturbations, offering a diagnostic for failure in naive patching strategies and setting the stage for more robust, learned intervention schemes.
Conclusion
This work establishes a robust, efficient framework for controllable low-level perceptual editing in unconditional diffusion models, overcoming the fundamental limitations of prior patching-only methods by leveraging negative guidance at inference. The method is empirically validated to surpass conventional baselines across several attributes and datasets, supported by both quantitative metrics and human evaluations. Future research may focus on adaptive, content-driven hyperparameter tuning, improved efficiency through dynamic guidance schedules, and theoretical developments in the characterization of latent space-editability for broad classes of attributes.

