- The paper introduces FocusDiff, a tuning-free diffusion model that uses refocusing cross-attention to enable precise, mask-localized edits.
- It leverages localized blurring and context-preserving modules to maintain background fidelity and achieve artifact-free modifications.
- The framework extends to 360° panoramic and VR editing, outperforming previous methods in CLIPScore and LPIPS metrics.
Toward Precise 360-Degree Indoor Panorama Editing via Tuning-Free Diffusion with Refocusing Cross-Attention
Introduction and Motivation
Text-driven diffusion models have transformed generative visual content creation, but existing architectures exhibit three persistent challenges in region-specific real-world editing tasks: prompt brittleness, spillover edits in non-target areas, and failures on small or cluttered regions due to insufficient fine-grained supervision. Existing tuning-free (zero-shot) diffusion methods frequently either impose excessive modifications outside the intended target or lack the granularity to manipulate small targets in crowded settings.
FocusDiff (“Target-Aware Refocusing for Tuning-Free Diffusion Editing”) introduces a framework that performs highly precise, mask-localized, zero-shot edits given only a text prompt, without necessitating model fine-tuning or architectural retraining. Central to its approach is a refocusing cross-attention mechanism that sharpens model focus on the designated region via selective blurring of the background, augmented by context-preserving modules to stabilize the latent content outside the edit area. The method also pioneers a practical extension to 360-degree panoramic image editing, supporting immersive VR environments.

Figure 1: FocusDiff enables precise, region-specific edits from simple prompts without fine-tuning, accurately modifying small objects while preserving surrounding content and visual coherence.
Technical Contributions and Framework
Refocusing Cross-Attention and Localized Blurring
FocusDiff’s pipeline (depicted in the next figure) uses an object mask M to first create a blurred version of the source input, which is processed in parallel with the original. During the iterative diffusion denoising, the cross-attention mechanisms are modified to transfer semantic and structural object information from the blurred latent to the edited latent specifically within the masked region. This suppresses the model’s attention to non-target areas and ensures sharpness and fidelity in the textual modification restricted to user-specified regions.
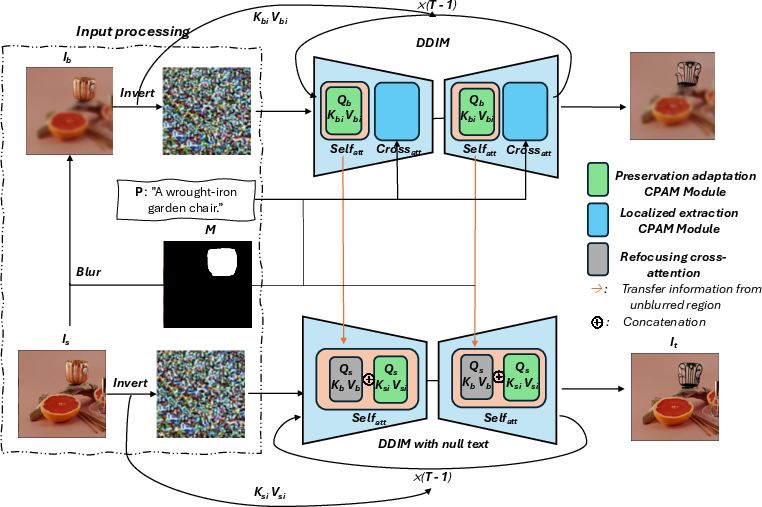
Figure 2: The FocusDiff pipeline: blurring non-edit regions focuses attention to the edit mask, while cross-attention transfers semantic details for region-specific manipulation.
Context-Preserving Integration
Background regions are prone to drift and loss of fidelity during denoising, especially in cascade architectures. FocusDiff incorporates preservation adaptation and localized extraction modules, ensuring latent consistency and structural integrity for regions outside the edit mask. These modules were inherited and further enhanced from CPAM, but now tightly integrated with the refocusing mechanism, synthesizing object modifications that are contextually aware and exhibit minimal boundary artifacts.
Panoramic and VR Editing Extension
FocusDiff introduces a novel panoramic image editing strategy tailored to VR. By allowing the user (or an automated vision-LLM such as SAM) to define local edit masks in large 360-degree images, the system crops a suitable context region, applies the FocusDiff edit, and then reintegrates and blends the result back into the panoramic canvas for artifact-free, consistent presentation.
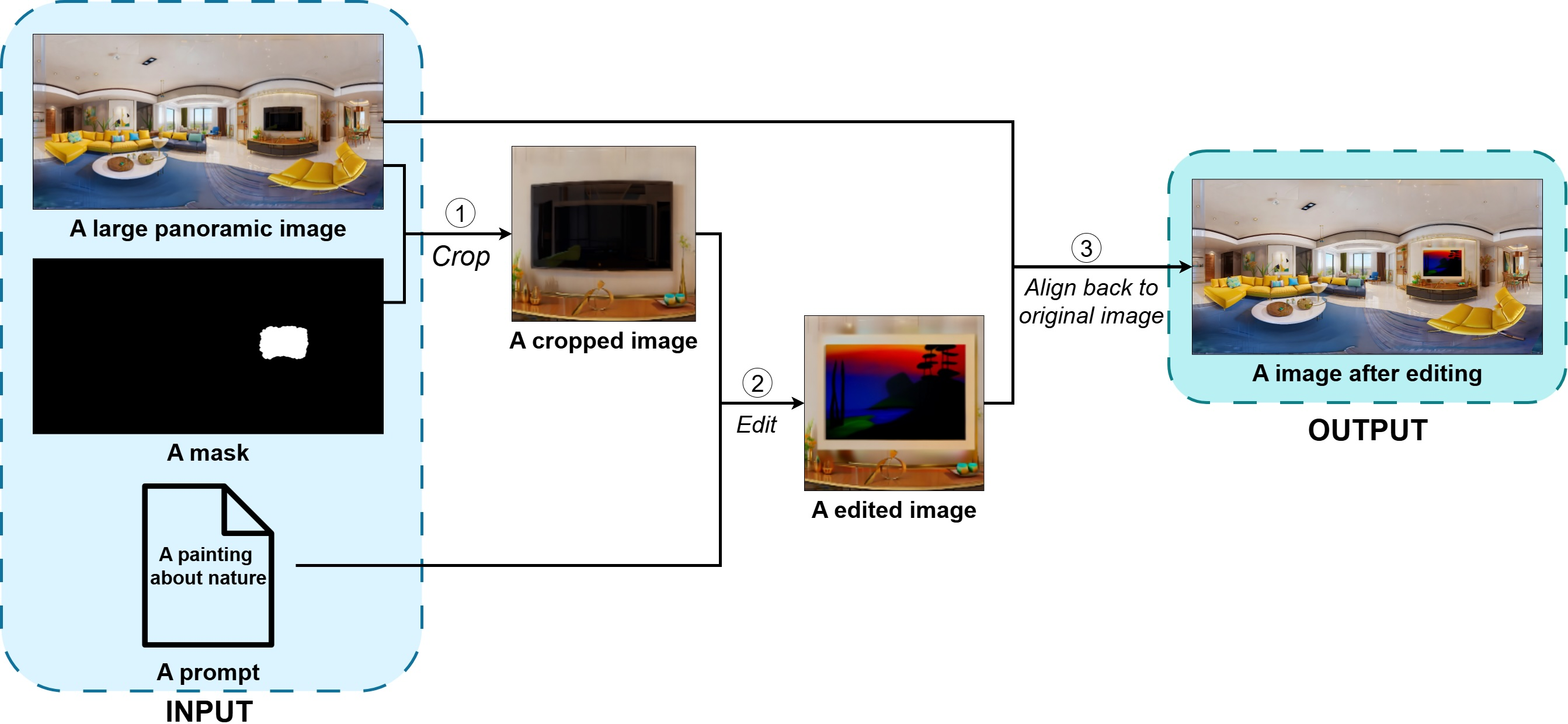
Figure 3: Panoramic image editing pipeline: mask generation (manual or automated), region cropping, context-aware region-specific editing, and seamless reintegration.
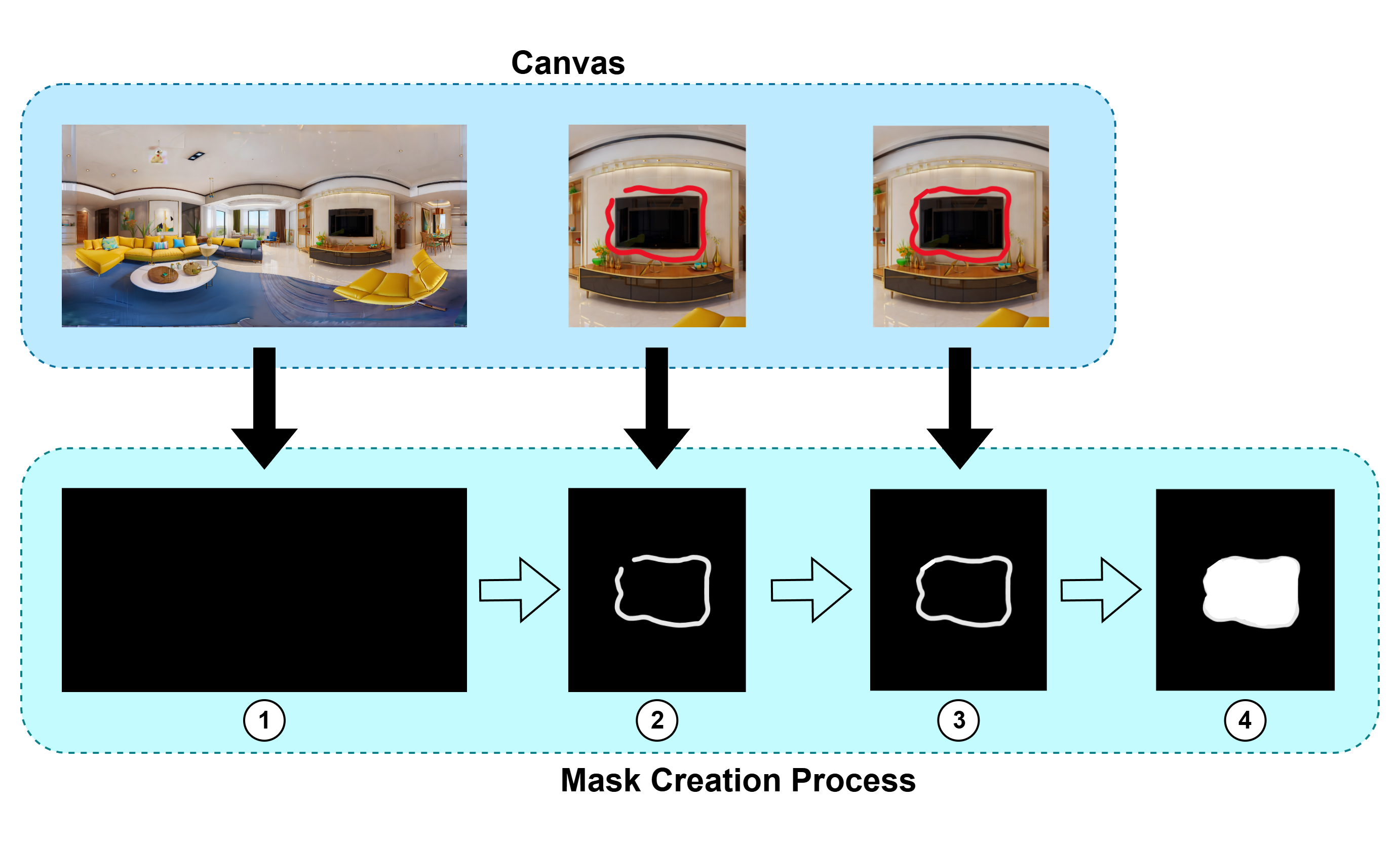
Figure 4: Mask generation workflow: users sketch contours, which are auto-connected and filled for precise region specification.
VR-Based Interaction
A dedicated VR interface allows users to interactively select region masks, input edit prompts, preview edits on a rendered sphere, and perform targeted object replacements or removals. The user can intuitively specify or draw the mask directly on the panoramic scene, merging manual fine control with automated segmentation for highly practical VR-editing usability.


Figure 5: The VR editing panel combines panorama selection, text prompting, and edit actions.
Experimental Results
FocusDiff was evaluated on the Localized Image Manipulation Benchmark (LIMB), testing fine-grained editing tasks across 30 complex, multi-object images (100 annotated examples), as well as on panoramic VR data. Quantitative metrics (CLIPScore for text-image alignment; LPIPS for background preservation) show that FocusDiff outperforms recent strong zero-shot methods such as MasaCtrl, Blended-Diffusion, DiffEdit, LEDITS++, and CPAM across Stable Diffusion v1.5, v2.1, and SDXL backbones. FocusDiff achieves a CLIPScore of 36.48 and an LPIPS of 0.064 on SDXL, indicating superior prompt adherence and minimal non-target distortion.
Figure 6: Qualitative comparison: FocusDiff delivers granular local edits, faithful prompt alignment, and naturalistic background consistency where other approaches fail.
Qualitative analysis confirms that alternative localized diffusion approaches—especially those relying on gradient guidance, blending, or prompt-to-prompt swapping—either result in rigid edits, introduce visual artifacts, or lack capacity for faithful background integration, particularly with small or occluded targets. In contrast, FocusDiff yields artifacts-free, photorealistic edits even for difficult scenarios involving tiny or crowded objects.
Panoramic Image and VR Editing
FocusDiff’s panoramic editing extension supports both object replacement and removal tasks, demonstrating region-localized fidelity and robust inpainting for unmasked context.

Figure 7: Panoramic image editing with FocusDiff: robust object replacement and removal maintaining global consistency.
A user study with 20 participants evaluated the VR-based system, measuring usability with the System Usability Scale (SUS). FocusDiff’s VR tool achieved a SUS score of 77.12/100, with most users quickly adapting despite limited prior VR experience, confirming the framework’s practical accessibility.
Figure 8: System Usability Scale (SUS) survey outcomes showing strong user satisfaction with the VR editing interface.
Ablation and Design Analysis
Ablation studies underscore the necessity of both refocusing cross-attention and context-preserving integration: omitting either leads to a dramatic drop in CLIPScore (e.g., 31.42 without RCA) and a substantial increase in LPIPS (up to 0.312 without both). Thus, both architectural innovations are indispensable for achieving precise, coherent, and targeted edits.
Implications and Future Directions
FocusDiff demonstrates that tuning-free diffusion techniques, augmented with targeted attention steering and background consistency mechanisms, can resolve major limitations in both conventional and immersive image editing—enabling region-specific, prompt-driven manipulation with minimal collateral modification. The model-agnostic attributes shown by seamless adaptation to SDXL and v2.1 further suggest strong transferability.
Practically, FocusDiff unlocks applications in interactive photo editing, media retouching, and end-user content customization within VR/AR, facilitating safe and intuitive manipulation of panorama-scale data. Theoretically, it provides a concrete recipe for directing generative model capacity to fine-grained, high-level local tasks without retraining, suggesting directions for more expressive, modular diffusion architectures.
Architectural limitations include static blurring radius specification, comparatively high computational overhead due to processing multiple variants, and rudimentary interactive mask post-processing algorithms. Further advances in dynamic mask refinement, semantic contour completion, and computational optimization are indicated. Ethical considerations around misuse, privacy, and provenance are acute for high-fidelity scene modification technologies and warrant future safeguards.
Conclusion
FocusDiff establishes a new standard for tuning-free, region-specific image editing—effectively overcoming spillover, prompt brittleness, and granularity issues inherent in prior approaches. It leverages cross-attention refocusing, integration of context-preserving modules, and seamless panoramic extension to deliver prompt-faithful, artifact-free edits in both single images and VR applications. These advances chart a path toward more robust, controllable, and democratized tools for fine-grained generative editing in multimodal and immersive contexts.
(2606.14035)