- The paper introduces a framework that disentangles local and global contexts to enable efficient real-time video editing with diffusion models.
- It employs a sparse local context module and a lightweight temporal global embedder to achieve 10× compute efficiency and 50× faster frame generation.
- Empirical results demonstrate high-fidelity inpainting and temporal consistency, with performance validated on benchmarks like VPBench-Edit and DAVIS.
Disentangled Local and Global Control in Real-Time Generative Video Editing with EditCtrl
Overview and Motivation
This essay examines "EditCtrl: Disentangled Local and Global Control for Real-Time Generative Video Editing" (2602.15031), a work addressing efficiency and quality challenges in prompt-guided video inpainting and editing with diffusion models. Existing methods, particularly those leveraging full-attention pretrained video foundation models, suffer from prohibitive computational cost by unnecessarily processing the entire video context regardless of the spatial extent of edits. EditCtrl introduces a framework that disentangles localized generation from global video context integration, yielding compute that scales with edit mask size while preserving high-fidelity generative priors and temporal consistency.

Figure 1: EditCtrl supports efficient prompt-guided edits on 4K videos, dynamically allocating compute proportional to mask size and propagating object edits with temporal consistency.
Methodological Innovations
EditCtrl diverges from prior dense full-attention generative editing paradigms through architectural disentangling of local and global context in the editing process. The system comprises two principal components:
- Sparse Local Context Module: Operates exclusively on tokens within user-defined edit masks, applying a fine-tuned local context encoder to sparse regions. Mask dilation is employed to address inadequate blending at mask boundaries, mitigating artifacts caused by spatial sparsity.
- Lightweight Temporal Global Context Embedder: Obtains a compact representation of downsampled background video using a VAE encoder; global context tokens encode high-level temporal cues (structure, lighting, motion, camera dynamics) and are fused into generation through cross-attention modulation, enhancing coherence across frames.
This design yields editing compute proportional to edit mask area, independent of input resolution, and adapters are trained without altering base diffusion model weights, ensuring compatibility with autoregressive content propagation.
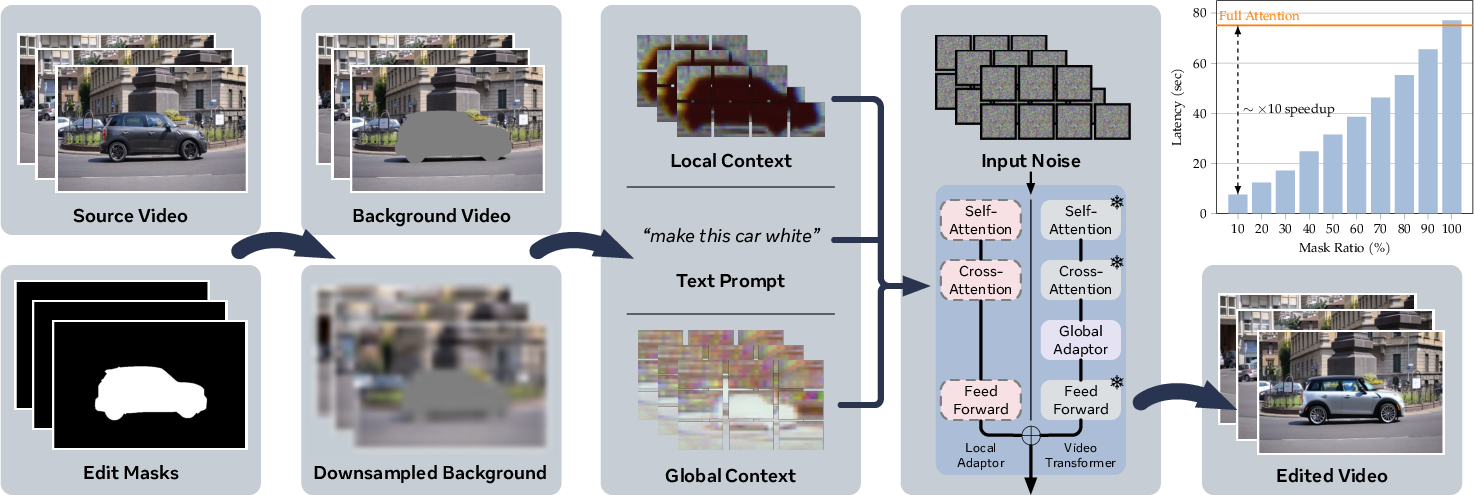
Figure 2: The EditCtrl video diffusion framework: global context from downsampled background and local context from edit masks are injected via trainable adapters into a pretrained text-to-video diffusion model.
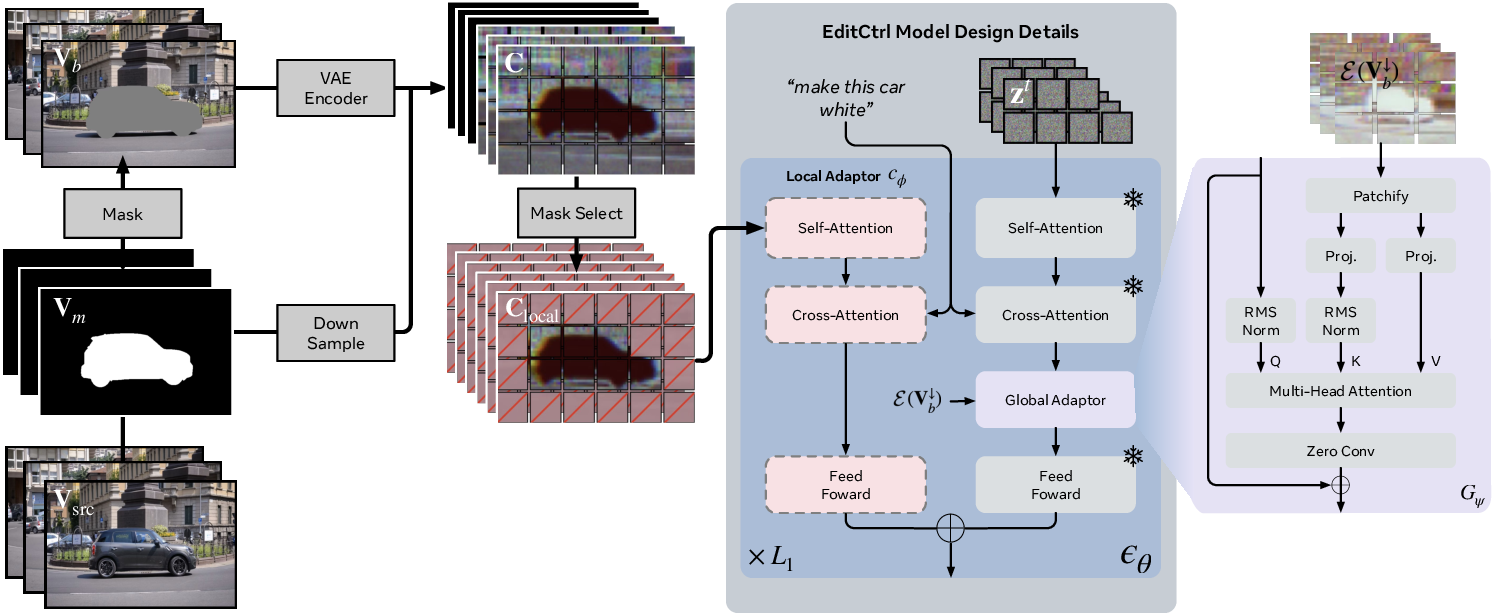
Figure 3: Disentangled local and global modules extract background tokens and masked regions, modulating transformer layers for localized generation aligned with video-wide context.
Interactive and Real-Time Editing Capabilities
EditCtrl’s computational decoupling enables broad interactive editing capabilities, including:
Empirical Results and Validation
EditCtrl achieves a 10× improvement in compute efficiency versus full-attention generative baselines, while matching or exceeding editing and inpainting quality. Performance is demonstrated on VPBench-Edit, DAVIS, and VPBench-Inp benchmarks—scenarios with diverse prompts and masks:
- Masked region preservation outperforms or matches state-of-the-art, with strong PSNR, SSIM, and LPIPS metrics.
- Semantic alignment with text prompts demonstrates robust integration of high-level generative cues.
- Temporal coherence scores are competitive, facilitated by the global context embedder.
EditCtrl's edit throughput (FPS) is notably 50× faster than generative baselines operating with full-attention, without perceptual degradation.


Figure 5: Video inpainting comparison: EditCtrl generates high-fidelity content with scene alignment using less compute; baselines struggle despite full-attention.
Ablation studies confirm necessity of both local and global adapters: naïve sparse local editing without global context or proper fine-tuning degrades visual coherence and prompt-responsiveness; combined adapters restore and enhance edit quality.

Figure 6: Removing local or global adapters undermines editing performance; EditCtrl with both matches full-attention quality at higher efficiency.
Qualitative Demonstrations
Qualitative results reveal EditCtrl’s ability to:
- Perform localized semantic edits (e.g., “change flower color to blue”).
- Edit multiple regions or objects within the same frame using distinct prompts.
- Inpaint content that blends structurally and visually, rather than generic patch filling.
- Maintain object and background integrity over complex temporal dynamics.


Figure 7: Prompt-guided local edit: EditCtrl accurately changes flower color while preserving scene texture.


Figure 8: Additional comparisons: EditCtrl edits scenes ("Add a hot air balloon", "Turn the sunglasses shiny red") with high spatial and temporal consistency.


Figure 9: EditCtrl enables semantic object replacement or augmentation across frames ("Turn the donkey into a zebra", "Add a bandana to the dog").

Figure 10: EditCtrl supports simultaneous multi-prompt generation for distinct regions.

Figure 11: Content propagation visualizations, maintaining temporal integrity during autoregressive edit extension.
Implications and Future Directions
EditCtrl’s disentangled framework critically addresses the scalability bottlenecks in video generative editing and inpainting. The architectural separation sets the stage for future developments in:
- Integration of motion-aware and geometry-aware context cues.
- Efficient cross-frame edit propagation in unconstrained or dynamic video feeds.
- Plug-and-play augmentation for domain-specific editing models (e.g., AR, VR, cinema post-production).
- Adaptation of the local/global paradigm to multi-modal generative control (e.g., joint audio/video/text editing).
Theoretical implications include the efficient exploitation of pretrained generative priors under localized supervision, modularity in control parameterization, and minimal perturbation of large foundation models during task adaptation.
Conclusion
EditCtrl presents a principled solution to high-fidelity, interactive, and real-time generative video editing with diffusion models, leveraging the disentanglement of local and global context for prompt-guided inpainting. Empirical evidence supports both efficiency and quality claims: compute scales with mask size, adapters guarantee generative priors are preserved, and content propagation unlocks practical deployment scenarios. With this method’s modularity and extension potential, EditCtrl is positioned as a robust foundation for advanced, scalable video editing frameworks.
