ConsistEdit: Highly Consistent and Precise Training-free Visual Editing
Abstract: Recent advances in training-free attention control methods have enabled flexible and efficient text-guided editing capabilities for existing generation models. However, current approaches struggle to simultaneously deliver strong editing strength while preserving consistency with the source. This limitation becomes particularly critical in multi-round and video editing, where visual errors can accumulate over time. Moreover, most existing methods enforce global consistency, which limits their ability to modify individual attributes such as texture while preserving others, thereby hindering fine-grained editing. Recently, the architectural shift from U-Net to MM-DiT has brought significant improvements in generative performance and introduced a novel mechanism for integrating text and vision modalities. These advancements pave the way for overcoming challenges that previous methods failed to resolve. Through an in-depth analysis of MM-DiT, we identify three key insights into its attention mechanisms. Building on these, we propose ConsistEdit, a novel attention control method specifically tailored for MM-DiT. ConsistEdit incorporates vision-only attention control, mask-guided pre-attention fusion, and differentiated manipulation of the query, key, and value tokens to produce consistent, prompt-aligned edits. Extensive experiments demonstrate that ConsistEdit achieves state-of-the-art performance across a wide range of image and video editing tasks, including both structure-consistent and structure-inconsistent scenarios. Unlike prior methods, it is the first approach to perform editing across all inference steps and attention layers without handcraft, significantly enhancing reliability and consistency, which enables robust multi-round and multi-region editing. Furthermore, it supports progressive adjustment of structural consistency, enabling finer control.













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple overview
This paper introduces ConsistEdit, a new way to edit images and videos with AI so the changes match your text instructions while keeping everything else the same. It focuses on making edits that are both strong (clearly visible) and consistent (the shape, identity, and background don’t get messed up), even across multiple edits or in videos.
Key goals and questions
The paper asks:
- How can we change exactly what the user wants (like color, material, or shape) without breaking the original structure or changing untouched areas?
- How can we let users control which parts stay the same (like structure/shape) and which can change (like color/texture)?
- How can we make this work well with newer AI models (called MM-DiT) that mix text and image information differently from older models?
How did they do it?
To understand the approach, here’s a quick background and the main idea behind ConsistEdit.
Background: how modern AI creates images and videos
- Many AI image/video tools start from random noise and slowly “clear it up” into a picture, guided by your text prompt.
- Inside the model, there’s a mechanism called attention. Think of attention like a smart “matchmaking” system:
- Q (Query) asks: “What am I looking for?”
- K (Key) says: “Where should I look?”
- V (Value) carries the actual information used to build the image.
- Older architectures (U-Net) kept text and image info more separate, so older editing tricks focused on “cross-attention” from text to image.
- Newer architectures (MM-DiT, used in models like SD3 and FLUX) combine text and image tokens together and use self-attention everywhere. That’s powerful—but it means old methods don’t work as well.
The three ideas behind ConsistEdit
The authors closely studied how MM-DiT handles attention and discovered three key insights. Based on those, ConsistEdit does three things:
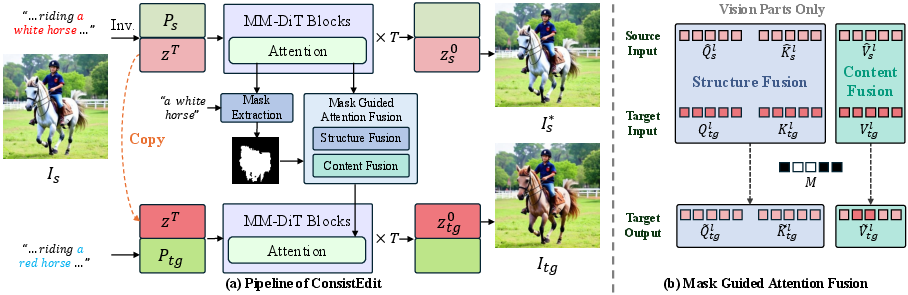
- Vision-only control: Only touch the “image parts” of attention, not the “text parts.” Changing the text tokens during editing made results unstable. Sticking to the image tokens keeps edits clean and reliable.
- Mask-guided pre-attention fusion: Before the attention step, blend “what to edit” and “what not to edit” using a mask (like coloring only inside the lines). This mask separates the edited region from the untouched background early in the process, which helps preserve structure and background.
- Different rules for Q, K, and V:
- Q and K (what and where to look) control structure/shape. Reusing these from the original image in certain places helps keep shapes (like hair strands or clothing folds) consistent even when changing color or material.
- V (the actual content) controls appearance/texture. Using original V for the background preserves colors and details outside the edited area.
There’s also a simple “consistency strength” slider (a parameter called α) that decides how strongly to preserve structure in the edited region:
- High α: shape stays almost identical (great for recoloring hair without changing hairstyle).
- Low α: more freedom to change shapes (like turning a round hat into a pointy one).
The method works across all steps and all attention layers automatically—no hand-tuning required.
Main findings and why they matter
What they tested:
- Images: tasks like changing color (e.g., “blue shirt → red shirt”), changing material (e.g., “wood → metal”), changing or adding objects, and style changes.
- Videos: making sure edits stay consistent across frames (so you don’t get flickering or drifting).
- Real photos: using “inversion” to reverse-engineer the model’s starting point from a real picture, then edit it.
How they measured success:
- Structure consistency: does the shape/edges remain the same where needed?
- Background preservation: are untouched areas unchanged?
- Prompt alignment: does the result match the text instruction?
What they found:
- ConsistEdit preserves structure in the edited region (e.g., same folds in clothes, same hairstyle) while making clear changes (like color or material).
- It leaves non-edited regions almost identical to the original—fewer unwanted changes or color shifts.
- It outperforms several recent methods on standard benchmarks.
- It supports multi-region edits (edit hair and shirt at once), multi-round edits (edit many times in a row without quality dropping), and video edits with fewer accumulated errors.
- It generalizes well to different MM-DiT models (like SD3, FLUX) and to video models (like CogVideoX).
Why this is important:
- You get precise, reliable edits with strong control, and fewer artifacts.
- It’s training-free, so you don’t have to retrain the AI model—just apply the technique during generation.
What this could mean going forward
- Better creative tools: Designers, artists, and video editors can make clean, targeted edits without breaking the rest of the image/video.
- More reliable multi-step workflows: You can edit in stages (color → shape → lighting) while keeping identity and background stable.
- Smoother video editing: Consistent edits across frames reduce flicker and visual drift.
- Future-proof approach: As more models adopt MM-DiT-style architectures, methods like ConsistEdit that understand and leverage MM-DiT’s attention will likely be the standard.
In short, ConsistEdit makes AI-powered editing more precise, stable, and controllable by smartly manipulating how the model “pays attention” to image regions—keeping what matters the same, and changing only what you ask for.
Knowledge Gaps
Below is a single consolidated list of concrete knowledge gaps, limitations, and open questions that remain after this work. These items are phrased to guide actionable follow-ups by future researchers.
- Mask extraction dependence: The method relies on attention-map-derived masks, but does not quantify robustness to mask errors (e.g., occlusions, small/overlapping objects, fine structures) or compare against external segmentation/user-provided masks; the impact of mask quality on edit fidelity and leakage remains unstudied.
- Temporal mask consistency: For video, it is unclear how masks are propagated or stabilized across frames; no mechanism or evaluation is provided for enforcing temporally consistent masks (e.g., mask jitter, drift, flicker), especially for long videos.
- Video metrics and long-form robustness: Video results are qualitative only; there is no quantitative evaluation of temporal consistency (e.g., tOF/tLPIPS, warping error) or performance over long sequences, nor analysis of edit stability with increasing duration.
- Inversion dependency: Real-image editing hinges on inversion (e.g., UniEdit-Flow), but the sensitivity to inversion quality, ablations across inversion methods, and failure cases arising from imperfect inversion are not quantified; cumulative error under multi-round edits is not measured.
- Runtime and memory overhead: Applying attention control across all layers and steps may be costly; there is no reporting of runtime/memory overhead relative to baselines, scaling with resolution, number of regions, or video length.
- Generalization breadth: Validation spans SD3 Medium, FLUX.1-dev, and CogVideoX-2B; transferability to other MM-DiT variants (e.g., SD3.5-Large, PixArt, HunyuanVideo) and hybrids with cross-attention is not demonstrated, nor are clear adaptation guidelines provided.
- High-resolution scaling: The method’s behavior at high resolutions (e.g., 1024–2048 px) is not evaluated; potential memory constraints, quality retention, and boundary integrity at higher pixel densities remain open.
- Theoretical grounding of Q/K/V roles: The claim that vision-only Q/K control structure and V controls content is supported empirically but lacks a deeper theoretical or head-wise/layer-wise analysis; the specialization of heads and potential head-selective control are unexplored.
- Consistency strength scheduling: The single hyperparameter α (ratio of steps) lacks an automatic or adaptive schedule; the effects of early vs. late-step scheduling, per-region α, and prompt/model-dependent normalization are not studied.
- Limits for structure-inconsistent edits: The trade-off between strong shape changes and identity/layout preservation is not systematically analyzed; failure cases for large geometric modifications or compositional edits are not characterized.
- Boundary handling and soft blending: Pre-attention fusion uses binary masks; the benefits of soft masks, adaptive dilation/feathering, or uncertainty-aware blending on boundary artifacts (in latent and pixel domains) are not measured.
- Prompt complexity and multilingual robustness: Robustness to long/complex/multilingual prompts, multi-attribute edits, and conflicting instructions is not evaluated; interaction effects in multi-region edits with distinct prompts are not analyzed.
- Sampler and step-count sensitivity: Although some samplers are tried, a broad sampler/solver study (e.g., DPM-Solver++, Heun, iPNDM) and sensitivity to step count are missing, as are rectified-flow vs. diffusion-specific behaviors under identical settings.
- Quantitative evaluation scope: Benchmarks emphasize noise-to-image rather than real-image edits; there is no user study, identity preservation metric (e.g., face-ID similarity), or broader semantic faithfulness metrics beyond CLIP; video lacks quantitative evaluation entirely.
- Real-world failure modes: The paper does not document failure categories (e.g., texture spillover, color shifts in non-edited regions under extreme lighting, edits on small objects, cluttered scenes) or provide systematic stress tests.
- Integration with external controls: Compatibility with image-conditioned references (e.g., style/reference images), ControlNet-like conditions, or other conditioning modalities is not explored; how to combine ConsistEdit with such controls is open.
- Multi-region scaling: While multi-region edits are shown, there is no analysis of cross-region interference, priority handling when prompts conflict, or how performance and compute scale with increasing region count.
- Ethical and safety considerations: Potential for misuse (e.g., identity manipulation, deepfakes), interaction with base-model safety guardrails, and mechanisms for provenance/watermark preservation or edit detection are not discussed.
- Reproducibility and specification gaps: Several equations contain typographical inconsistencies; key implementation details (e.g., exact mask extraction procedure, default α, per-layer schedules, per-head behavior) are deferred to the appendix/website, creating barriers to faithful reproduction.
- Hybrid training opportunities: The benefits of lightweight learned components (e.g., a learned mask predictor, α-scheduler, or per-head gating) while keeping the backbone frozen are not investigated; the potential for semi-supervised or reinforcement-tuned control remains open.
- 3D/multi-view consistency: Application to multi-view or 3D-aware generation/editing, and the preservation of cross-view consistency during edits, are not addressed.
- Photometric/relighting validation: Claims of better lighting/shading adaptation are qualitative; there is no quantitative evaluation on material/relighting datasets or metrics (e.g., photometric consistency, reflectance plausibility).
- Text compliance under full-layer control: Editing across all layers may interact with text alignment in nontrivial ways; prompt-sensitivity analyses, especially under extreme or ambiguous prompts, are missing.
Practical Applications
Immediate Applications
Below is a curated list of concrete, deployable use cases that leverage ConsistEdit’s training-free, MM-DiT–tailored attention control (vision-only token manipulation, pre-attention mask fusion, differentiated Q/K vs V handling), multi-round/multi-region editing, and progressive consistency control. Each item includes target sector(s), candidate product/tool concept, and key assumptions/dependencies.
- Consistent recoloring and material edits of product assets for e-commerce catalogs (e-commerce, advertising)
- Tools/workflows: Batch “variant generator” that recolors fabrics, paints, plastics, metals while preserving structure and background; integrates with PIM/DAM and brand color libraries; multi-region single pass for logos + garments.
- Assumptions/dependencies: Access to MM-DiT models (e.g., FLUX.1-dev, SD3), reliable prompt engineering, GPU inference; legal compliance with model licenses.
- Brand-compliant creative localization at scale (advertising, marketing)
- Tools/workflows: Creative localization pipeline that updates color schemes, textures, packaging labels per region while locking identity/layout; CI pipeline with consistency-strength slider for QA sign-off.
- Assumptions/dependencies: Automated mask extraction quality, governance rules for brand assets, content provenance logging.
- Film/TV/VFX continuity fixes (media/entertainment, post-production)
- Tools/workflows: Shot-by-shot video recoloring (props, wardrobe), relighting tweaks, material changes with temporal consistency; NLE plugin (After Effects, Premiere) with per-shot consistency controls.
- Assumptions/dependencies: CogVideoX or similar video MM-DiT weights; high-quality inversion for real-shot footage; compute budget; watermark/provenance workflows.
- Fashion and apparel digital try-ons and lookbooks (fashion-tech, retail)
- Tools/workflows: Interactive editor to swap garment colors/materials, adjust folds and drape without identity drift; multi-round edits for styling sequences.
- Assumptions/dependencies: Accurate region masks; user-facing UI; model license fit for commercial use.
- Interior/exterior design visualizations (architecture, real estate)
- Tools/workflows: Rapid material/finish swaps (paint, flooring, stone), daylight relighting, fixture changes; multi-region edits for rooms/facades.
- Assumptions/dependencies: High-resolution MM-DiT inference; careful prompt curation; provenance tracking for client deliverables.
- Game asset variants and skin pipelines (gaming)
- Tools/workflows: Texture/material swaps for NPCs/props while preserving mesh-structure cues in 2D renders/sprites; batch asset editors integrated with content pipelines.
- Assumptions/dependencies: Stable output across all attention layers; model integration with art pipelines; licensing compatibility.
- Social media/photo apps “precision edit” modes (consumer software)
- Tools/workflows: Mobile/desktop feature to recolor hair/clothing/objects while locking background; per-feature slider to control structure vs texture changes.
- Assumptions/dependencies: Lightweight MM-DiT inference (cloud, possibly on-device for images), UX for mask confirmation; safety filters.
- Product compliance updates (regulatory labels, warnings) with layout preservation (manufacturing, compliance)
- Tools/workflows: Update label color/material and minor text regions without shifting layout; audit logs with edit masks and consistency strength metadata.
- Assumptions/dependencies: Strong provenance/traceability; policy adherence; controlled editing scope.
- Editorial corrections for news/press images with minimal collateral changes (media, journalism)
- Tools/workflows: Correct color/material misrepresentation while preserving scene integrity; log edits (Q/K/V manipulations, masks) for transparency.
- Assumptions/dependencies: Editorial guidelines; disclosure policies; watermarking.
- Teaching and research on multimodal attention disentanglement (academia, education)
- Tools/workflows: Classroom labs that demonstrate structure (Q/K vision tokens) vs texture/content (V vision tokens) editing; open benchmarks and ablations.
- Assumptions/dependencies: Access to open MM-DiT models; reproducible scripts; permission for dataset usage.
- Dataset curation and augmentation with structural fidelity (academia, ML ops)
- Tools/workflows: Generate consistent color/material variants for balanced datasets while preserving geometry; audit masks and steps for documentation.
- Assumptions/dependencies: Clear labeling of synthetic edits; data governance; model license compliance.
- Interactive “consistency strength” slider in pro editors (software)
- Tools/workflows: UI control to smoothly dial structure preservation vs prompt-driven shape change; presets for “color-only,” “material-only,” or “shape+texture.”
- Assumptions/dependencies: Parameter exposure via API; UX affordances; user education.
- Multi-region, single-pass edits for complex scenes (creative tools)
- Tools/workflows: One-pass workflow to edit multiple disjoint regions (e.g., car paint + sky tone + signage) reliably without drift across layers/steps.
- Assumptions/dependencies: Robust mask extraction; compositing QA; GPU capacity for larger scenes.
- Batch brand color conformance checker and auto-fixer (advertising QA, enterprise tooling)
- Tools/workflows: Analyzer verifies color targets across assets; auto-corrects mismatches while preserving structure/background; integrates with content compliance systems.
- Assumptions/dependencies: Color profile management; ICC integration; quantization-aware inference.
Long-Term Applications
Below are forward-looking use cases that are feasible with further research, scaling, or integration, including dependencies and assumptions that may influence adoption.
- Real-time, on-device video editing with consistent multi-region control (mobile, AR/VR)
- Tools/workflows: Live relighting/recoloring filters that preserve identity and layout across frames; AR try-ons with structure-locked garments.
- Assumptions/dependencies: Model distillation/acceleration, GPU/NPUs on device, efficient inversion-free pipelines.
- Broadcast/streaming “live continuity correction” (media, sports, events)
- Tools/workflows: Real-time correction of jersey colors, sponsor logos, lighting artifacts with temporal coherence; operator-controlled consistency slider.
- Assumptions/dependencies: Low-latency inference, robust temporal mask tracking, integration with production switchers.
- Robotics and simulation domain randomization with structure-preserving edits (robotics)
- Tools/workflows: Generate consistent visual variants (materials, lighting, backgrounds) without altering geometry for sim2real training.
- Assumptions/dependencies: Proven correlation with downstream performance; integration with simulators; safety controls.
- Digital twin maintenance: non-destructive visual updates (industrial, smart cities)
- Tools/workflows: Update textures/materials of assets in digital twins (e.g., corrosion stages, signage refresh) while keeping structural fidelity.
- Assumptions/dependencies: 3D/NeRF/CAD integration; cross-view consistency; audit/provenance.
- 3D-aware editing (NeRFs, Gaussian splats, CAD) via extended attention control (3D content creation)
- Tools/workflows: Structure-preserving edits across views; disentangled texture/material updates in 3D pipelines.
- Assumptions/dependencies: Multiview-consistent attention mechanisms; 3D-aware MM-DiT extensions; geometric priors.
- Standardized provenance, watermarking, and audit trails for training-free edits (policy, trust & safety)
- Tools/workflows: Embedded edit metadata (masks, consistency strength, Q/K/V fusion logs), interoperable with C2PA-like standards.
- Assumptions/dependencies: Industry adoption; legal frameworks; model vendor cooperation.
- Medical imaging data augmentation with strict structure locks (healthcare, research)
- Tools/workflows: Non-diagnostic visual adjustments (e.g., anonymization color/material overlays) that preserve structural landmarks; training-set enrichment.
- Assumptions/dependencies: Regulatory adherence; clinical validation; strong provenance; limited to non-clinical use.
- Collaborative, multi-user, versioned editing in cloud studios (enterprise creative, media)
- Tools/workflows: Concurrent edits with region-level locks; version control of masks and consistency settings; conflict resolution workflows.
- Assumptions/dependencies: Scalable cloud services; permissioning; enterprise IAM integrations.
- Agentic pipelines that decompose edits into structure vs texture subtasks (software, LLM + vision)
- Tools/workflows: Planner agents choose Q/K (structure) vs V (content) operations per region; iterate until target CLIP/brand metrics hit thresholds.
- Assumptions/dependencies: Reliable auto-masking, prompt planning, feedback loops, safety filters.
- Automated continuity auditing in long-form video (media QA)
- Tools/workflows: Detect and flag inadvertent shifts in non-edited regions across cuts; propose fixes that minimize drift.
- Assumptions/dependencies: Temporal analytics; scalable indexing; integration with editing suites.
- Cross-modal extension (text + sketch + segmentation) for precise edits (software, design tools)
- Tools/workflows: Hybrid inputs to anchor masks and desired edits; combine text goals with user-provided geometry hints.
- Assumptions/dependencies: Multimodal token fusion research; UI support; robust mask synthesis.
- Benchmarks and metrics for fine-grained structural vs texture consistency (academia, standards)
- Tools/workflows: Public datasets with region annotations and consistency targets; standardized SSIM-on-edges + background PSNR/SSIM + temporal metrics.
- Assumptions/dependencies: Community consensus; open licenses; reproducibility.
General Assumptions and Dependencies (cross-cutting)
- Model access and licensing: Availability and legal use of MM-DiT models (e.g., SD3, FLUX.1-dev, CogVideoX); adherence to TOS.
- Compute and scalability: GPU/accelerator requirements for high-res images and especially video; potential need for distillation or efficient samplers/inversion-free variants.
- Mask quality and prompts: Reliable mask extraction (attention-derived or user-specified), prompt clarity; human-in-the-loop where precision matters.
- Provenance and safety: Watermarking, edit logs, disclosure in sensitive contexts; content moderation for misuse (deepfakes, misinformation).
- Integration: Plugins/APIs for major creative tools (Photoshop, After Effects, Blender), DAM/PIM systems, CI/CD in creative ops.
- Evaluation: Use of consistency metrics (e.g., SSIM on Canny edges for structure, PSNR/SSIM on non-edited regions, CLIP alignment) to enforce quality gates.
These applications reflect both the immediate practicality of ConsistEdit in today’s MM-DiT-based creative and production environments and the trajectory toward real-time, 3D-aware, provenance-anchored pipelines that will benefit industry, academia, policy, and daily life.
Glossary
- Ablation study: A controlled evaluation that removes or varies components to assess their contribution to overall performance. "Ablation study on attention control for structure consistency."
- Attention control: Training-free techniques that manipulate attention components to steer generative models during editing. "training-free attention control methods"
- Attention mechanism: The operation in transformers that computes weighted interactions among tokens using query, key, and value. "the attention mechanism,"
- BG preservation: Short for background preservation; keeping non-edited regions identical to the source image or video. "BG preservation"
- Canny edge maps: Edge detections from the Canny algorithm, often used to measure structural similarity. "Canny edge maps"
- CLIP similarity: A semantic alignment metric using CLIP embeddings to compare images with text prompts. "CLIP similarity"
- Consistency strength (alpha): A hyperparameter controlling how strongly structural consistency is enforced across timesteps. "the consistency strength () is set to 0.3"
- Content Fusion: The strategy of using source value tokens in non-edited regions to preserve colors and details. "We refer to following strategy as Content Fusion."
- Cross-attention: An attention form where queries attend to keys/values from another modality (e.g., text guiding vision). "cross-attention layers"
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion generative modeling. "diffusion transformers (DiT)"
- Dual-network architecture: A setup with two passes (sharing weights) for reconstructing the source and producing the edited target. "dual-network architecture"
- Euler sampler: A numerical sampler used during iterative generative inference steps. "we use the Euler sampler"
- Flow matching: A generative approach that models flows between distributions used in diffusion-like generation. "flow matching"
- Hadamard product: The element-wise product of matrices or tensors. "Hadamard product"
- Inversion: The process of reversing generation to recover the initial noise that reconstructs a given image/video. "The inversion procedure aims to accurately reverse the generation process"
- Latent diffusion: Performing diffusion in a compressed latent space rather than pixel space. "latent diffusion"
- Latent space: The compact feature space where images/videos are represented for generation or editing. "the latent space"
- Mask-guided pre-attention fusion: Fusing editing and non-editing regions via a mask before computing attention. "mask-guided pre-attention fusion"
- MLP modulation: Conditioning or modifying token features via multilayer perceptron operations within attention blocks. "MLP modulation"
- MM-DiT: A Multi-Modal Diffusion Transformer that jointly processes text and vision with self-attention. "MM-DiT is a self-attention-only architecture"
- PCA decomposition: Principal component analysis used to visualize and analyze token/feature distributions. "PCA decomposition visualization"
- Pre-attention transformation: Operations applied before attention (e.g., normalization, modulation) to produce Q, K, V. "pre-attention transformation"
- Prompt-to-Prompt (P2P): A training-free editing method that manipulates cross-attention using source and target prompts. "Prompt-to-Prompt (P2P)"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric comparing reconstructed or edited content to a reference. "PSNR"
- Q, K, V tokens (query, key, value): The triplet of vectors used by attention to compute weights and aggregate information. "query (Q), key (K), and value (V) tokens"
- Rectified Flow: A flow-based generative modeling technique used as an alternative to standard diffusion. "rectified flow"
- Self-attention: Attention computed within a single set of tokens to capture pairwise interactions. "self-attention"
- SSIM: Structural Similarity Index; a perceptual metric for image similarity, often computed on edges. "SSIM"
- State-of-the-art (SOTA): The best reported performance level in a field at a given time. "state-of-the-art (SOTA) performance"
- Structure Fusion: The method of blending source Q and K (vision parts) in edited regions before attention to preserve structure. "We refer to this method as Structure Fusion."
- Structure-consistent editing: Edits that change attributes like color or material while preserving the original structure. "structure-consistent editing tasks."
- Structure-inconsistent editing: Edits that alter structure or shape to satisfy the target prompt. "structure-inconsistent editing tasks."
- U-Net: An encoder–decoder convolutional architecture used in earlier diffusion models with separate cross- and self-attention. "U-Net"
- Vision-only attention control: Restricting attention manipulation to vision tokens to improve stability and consistency. "Vision-only attention control"
Collections
Sign up for free to add this paper to one or more collections.