- The paper presents an extensive review of Transformer variants, summarizing key architectural modifications for improved efficiency and adaptability.
- It introduces advanced methodologies like sparse and linearized attention to address the quadratic complexity in traditional models.
- The study highlights applications across NLP, computer vision, and audio, and outlines future directions for research.
Transformers have emerged as a dominant model architecture within the field of artificial intelligence, demonstrating significant success across various domains, including NLP, computer vision (CV), and audio processing. Originally developed as a sequence-to-sequence model for machine translation, Transformers have since spawned a multitude of variants, collectively known as X-formers, all seeking to enhance the efficiency, generalizability, and adaptability of the vanilla Transformer. The survey, "A Survey of Transformers" (2106.04554), provides an extensive and systematic review of these Transformer variants, offering insights into their architectures, pre-training methodologies, and expansive applications.
The vanilla Transformer architecture consists of an encoder-decoder structure, with both parts comprising multiple identical blocks. Each encoder block includes multi-head self-attention and a position-wise feed-forward network (FFN), both wrapped with a residual connection followed by layer normalization. The decoder stacks are slightly more complex with an inserted cross-attention mechanism between self-attention and FFN to facilitate dependency tracking across the sequence. The Transformer model relies on positional encodings or representations to capture token ordering, and operates with a computational limitation due to the quadratic complexity of self-attention with respect to sequence length.
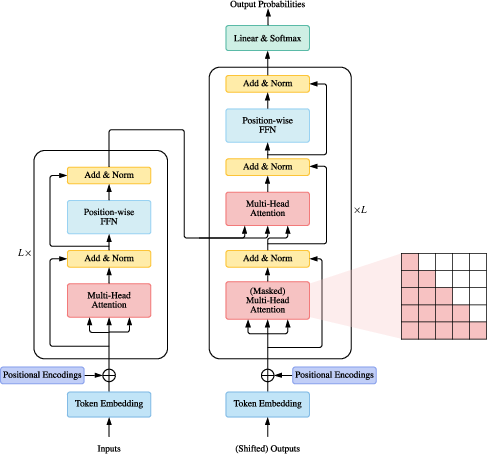
Figure 1: Overview of vanilla Transformer architecture.
Despite these advances, the inefficiency in processing long sequences because of computational overhead in the self-attention module remains a challenge (Figure 2).
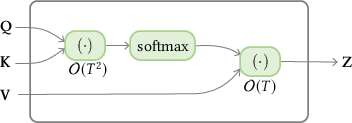
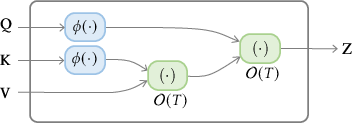
Figure 2: Illustration of complexity difference between standard self-attention and linearized self-attention.
Architectural Modifications of Transformers
An extensive body of work has emerged to address the computational inefficiency and lack of structural bias in Transformers. One major area of investigation is the development of Sparse Attention mechanisms (Section 4.1). Instead of computing full attention across all pairs of tokens, sparse attention restricts the number of query-key pairs, leveraging structural biases to improve efficiency. Position-based sparse attention, for example, limits attention computation to predefined patterns such as global attention, band attention, and dilated attention (Figure 3).
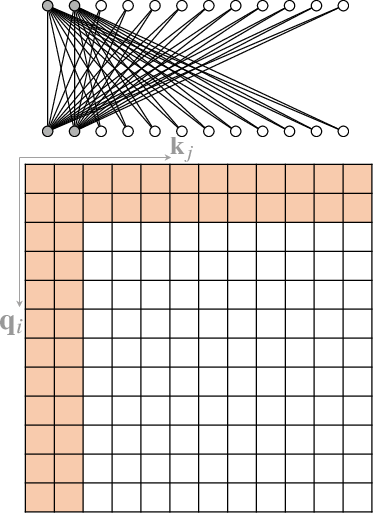
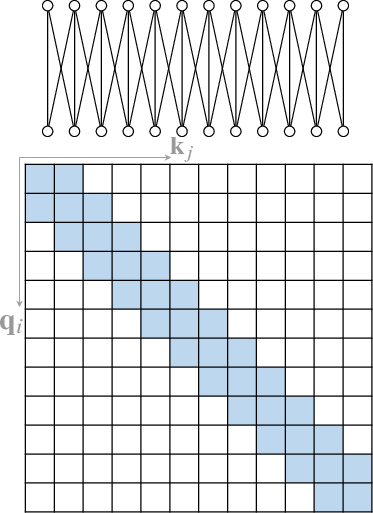
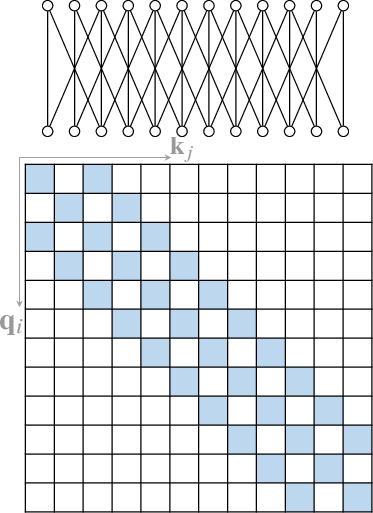
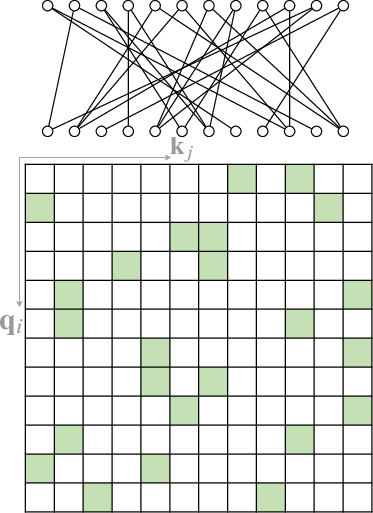
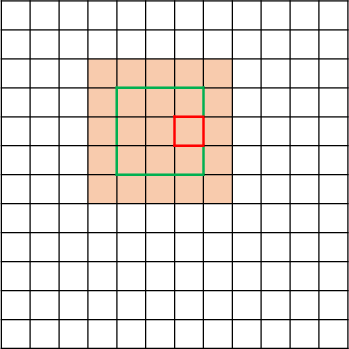
Figure 3: Some representative atomic sparse attention patterns. The colored squares mean corresponding attention scores are calculated and a blank square means the attention score is discarded.
Other novel solutions to reduce the computational complexity include Linearized Attention (Figure 2) that disentangles the attention mechanism using kernel feature maps to approximate the attention distribution matrix. Different studies propose various feature maps to achieve this linearization while ensuring stability and accuracy.
Other Module-Level Modifications
Aside from attention mechanisms, there is also significant research effort towards modifying other components of the Transformer architecture, such as the FFN and layer normalization. These include exploring different activation functions, enhancing FFNs with layers like Mixture-of-Experts or switching to alternative inter-head aggregation schemes. Modifications have frequently shown significant efficiency gains, allowing for longer sequence modeling without linearly scaling costs.
Application Areas
Transformers have successfully transcended their origins in NLP, being applied to a plethora of fields:
- Natural Language Processing: Including language modeling, machine translation, and named entity recognition.
- Computer Vision (Figure 4): Adapted for tasks like image classification and object detection.
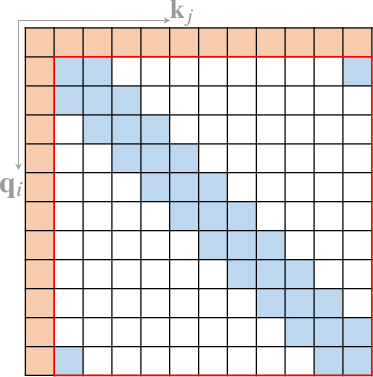
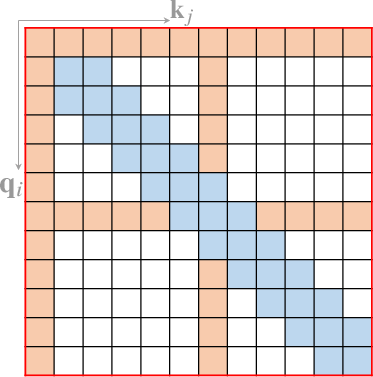
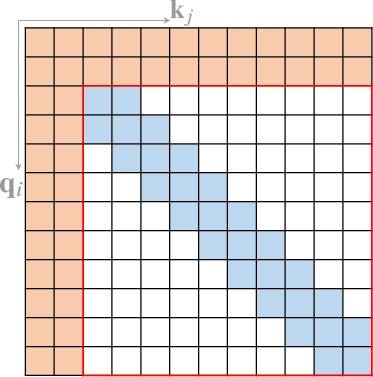
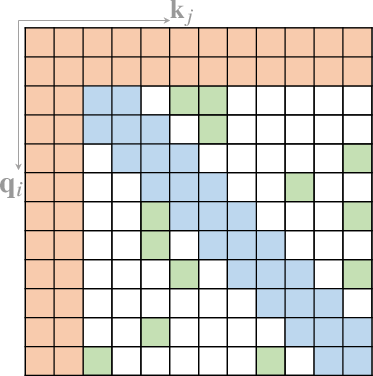
Figure 4: Some representative compound sparse attention patterns. The red boxes indicate sequence boundaries.
Conclusion
The survey on transformer models and their variants provides an exhaustive overview of the current research landscape regarding Transformer developments, categorizing them mainly by architectural modifications, pre-training techniques, and application fields. While substantial progress has been made in terms of efficiency and adaptability, ongoing research still targets enhancing Transformer’s theoretical backing and exploring alternative architectural paradigms that can potentially lead to improvements in terms of computational efficiency and generalization ability. Future work will likely focus on exploring more efficient attention variants, developing universally adaptive architectures, and establishing unified frameworks for handling multimodal data.