- The paper reveals that VLMs experience performance degradation when processing conflicting image-caption pairs, showing inherent modality biases.
- The study employs probing and clustering analyses to demonstrate that biases stem from deeper attention head layers rather than encoding failures.
- Manipulating specific attention heads, like router and promotion heads, improves target-modal fidelity and cross-dataset generalization.
Introduction
The integration of multimodal inputs has become essential in advancing AI systems that operate in varied and complex environments. The paper investigates how Vision-LLMs (VLMs) handle inconsistent information across modalities, using inputs like an image of a dog accompanied by a caption "A photo of a cat." This study is significant as it reveals differential treatment of conflicting modalities among VLMs, with some preferring image data and others text. Furthermore, the researchers explore how certain attention heads facilitate or bias this preference.
The paper's experimental setup involved creating inconsistent image-caption pairs and evaluating models on their ability to report information correctly based on a specified target modality, either visual or textual. The main findings highlight performance degradation across all tested models when exposed to these conflicting inputs, with models like InstructBLIP showing a pronounced bias towards visual information in contradictory settings.

Figure 1: Examples of inconsistent image and caption pairs. Models need to report image or caption information based on the target modality.
Internal Representational Analysis
To understand the underlying causes behind VLM behavior, the researchers employed probing techniques to assess whether models encode unimodal information adequately. It was found that VLMs do encode independent modal information accurately, suggesting that the performance drop isn't due to an encoding failure. Instead, clustering analysis revealed that the models' bias towards a modality is embedded within deeper layers of the network, influencing decision-making based on the target modality prompt.
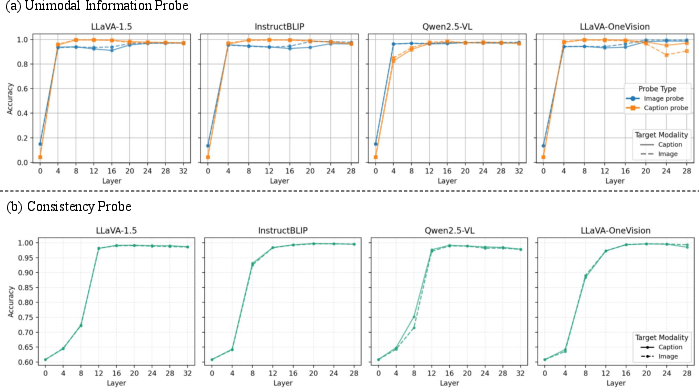
Figure 2: Accuracy of unimodal and consistency probes indicate VLMs effectively encode modality-specific information, in addition to detecting consistency.
Attention Head Role in Modality Preference
The study identifies specific attention heads responsible for dynamically restructuring representations according to the target modality. These include modality-agnostic "router heads" and modality-specific "promotion heads." By manipulating these heads, researchers demonstrated the ability to adjust the models’ output preference, improving target-modal fidelity when processing conflicting inputs.
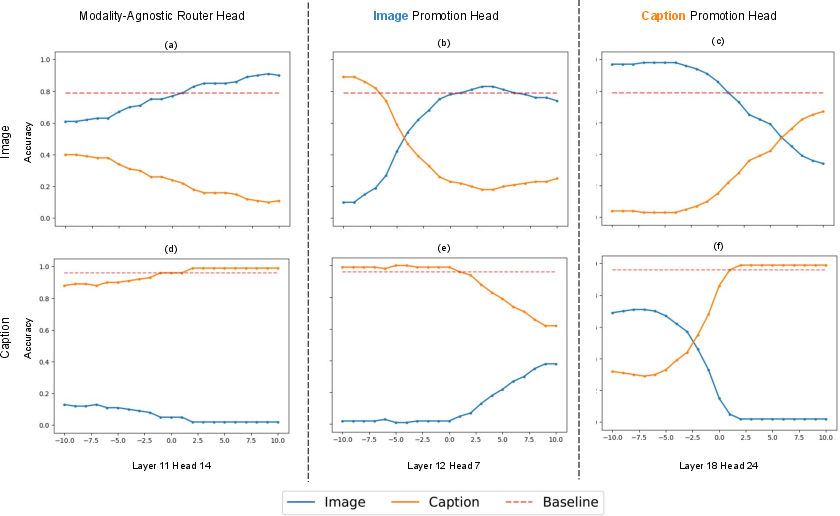
Figure 3: Different attention head types in Qwen2.5-VL, showing their influence on modality-specific answers.
Cross-Dataset Generalization and Intervention
Intervention studies revealed that altering the functionality of these attention heads can generalize to other datasets. This finding suggests the potential for utilizing attention head manipulation to enhance VLM accuracy in diverse real-world scenarios involving conflicting multimodal information.
Conclusion
The paper provides insights into the adaptability of VLMs when dealing with cross-modal information conflicts. The identification of attention heads that modulate modality preference is a key step toward developing more reliable multimodal AI systems. Future research should investigate the scalability of these findings across larger model architectures and broader modality datasets to more fully harness the potential of VLMs in practical applications. Through continuous exploration and manipulation of attention structures, AI systems may efficiently resolve information conflicts, leading to more coherent and contextually aware multimodal interactions.