- The paper introduces a hybrid deterministic-stochastic policy (TRFP) that overcomes the unimodal limitations in MaxEnt RL through one-step sampling.
- It employs flow straightening regularization and a decoupled architecture to mitigate gradient instability and reduce inference latency.
- Empirical results validate TRFP's ability to maintain multimodal coverage and competitive returns on standard benchmarks.
Truncated Rectified Flow Policies for Multimodal Reinforcement Learning with Efficient One-Step Sampling
Introduction and Motivation
This paper addresses an intrinsic representational bottleneck in maximum entropy reinforcement learning (MaxEnt RL): the reliance on unimodal Gaussian policy parameterizations. Although MaxEnt RL, exemplified by SAC, enhances exploration and robustness via entropy regularization, standard Gaussian policies cannot model complex multimodal action distributions required for many real-world and multi-goal tasks. The paper systematically critiques this limitation and surveys recent literature on generative policy parameterizations—especially diffusion probabilistic models (DPMs) and continuous normalizing flows (CNFs)—which offer enhanced expressivity at the cost of computational tractability and inference complexity. The two dominant challenges in prior diffusion/flow-based policies are (1) intractable action likelihoods impeding stable entropy maximization and (2) multi-step iterative generation causing both backpropagation instability and prohibitive inference latencies.
The paper introduces the Truncated Rectified Flow Policy (TRFP), a hybrid deterministic-stochastic policy architecture that enables tractable surrogate entropy-regularized RL, resolves the inference bottleneck via one-step sampling, and yields competitive or superior empirical performance on multimodal and standard RL benchmarks.
Methodology
Hybrid Policy Architecture
TRFP divides the policy generation trajectory into a deterministic prefix and a stochastic tail. The prefix segment (ODE-driven) transports a latent variable from an isotropic Gaussian prior toward the target action distribution, exploiting the straight-line geometric bias induced by rectified flow (RF) training. The tail segment (SDE-driven) introduces stochasticity, enabling a tractable surrogate likelihood computation over the augmented trajectory, and facilitating sample diversity for robust exploration.
This architectural decoupling supports adaptive trade-offs between expressivity and inference efficiency. During training, the stochastic tail enables Q-weighted actor updates and entropy estimation via a tractable surrogate. During inference (and in evaluation-ablation modes), the stochastic tail can be omitted, using only the deterministic transport, drastically reducing sampling cost.
Surrogate Entropy Optimization and Truncated Gradients
In the MaxEnt RL framework, stable entropy regularization depends on evaluating the log-likelihood of the policy, which is generally intractable for ODE-based flows due to Jacobian divergence integration. TRFP circumvents this with a surrogate likelihood, which only accounts for the stochastic tail, omitting the (deterministically volume-preserving) transport prefix. The error in this surrogate is upper-bounded by the trajectory divergence, which is minimized by the flow straightening regularizer.
Gradient instability—especially with deep, multi-step generation chains—is handled via truncated optimization. Gradients are not backpropagated through the prefix transport; the RL updates only affect the stochastic tail. This ensures training stability even with longer rollout horizons.
Flow Straightening Regularization
Flow straightening is enforced via self-distillation, where deterministic (zero-noise) rollouts generate trajectory endpoints that serve as targets for the ODE vector field. By regressing the flow field to a constant vector (source to target), the deterministic prefix approximates an optimal transport map, minimizing both geometric curvature and the entropy surrogate error. This in turn justifies efficient low-NFE (number of function evaluations) or even one-step rollout at deployment, which is critical for real-time control scenarios.
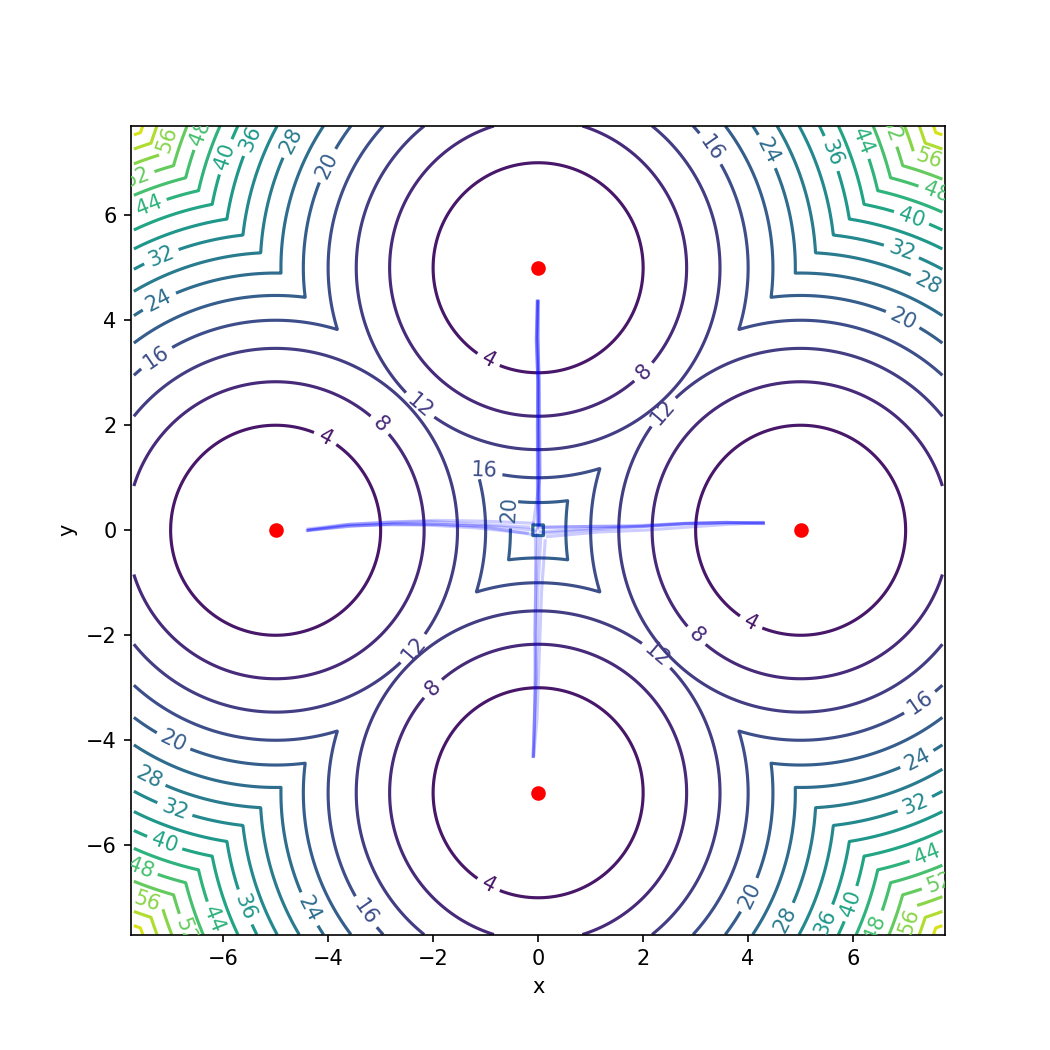
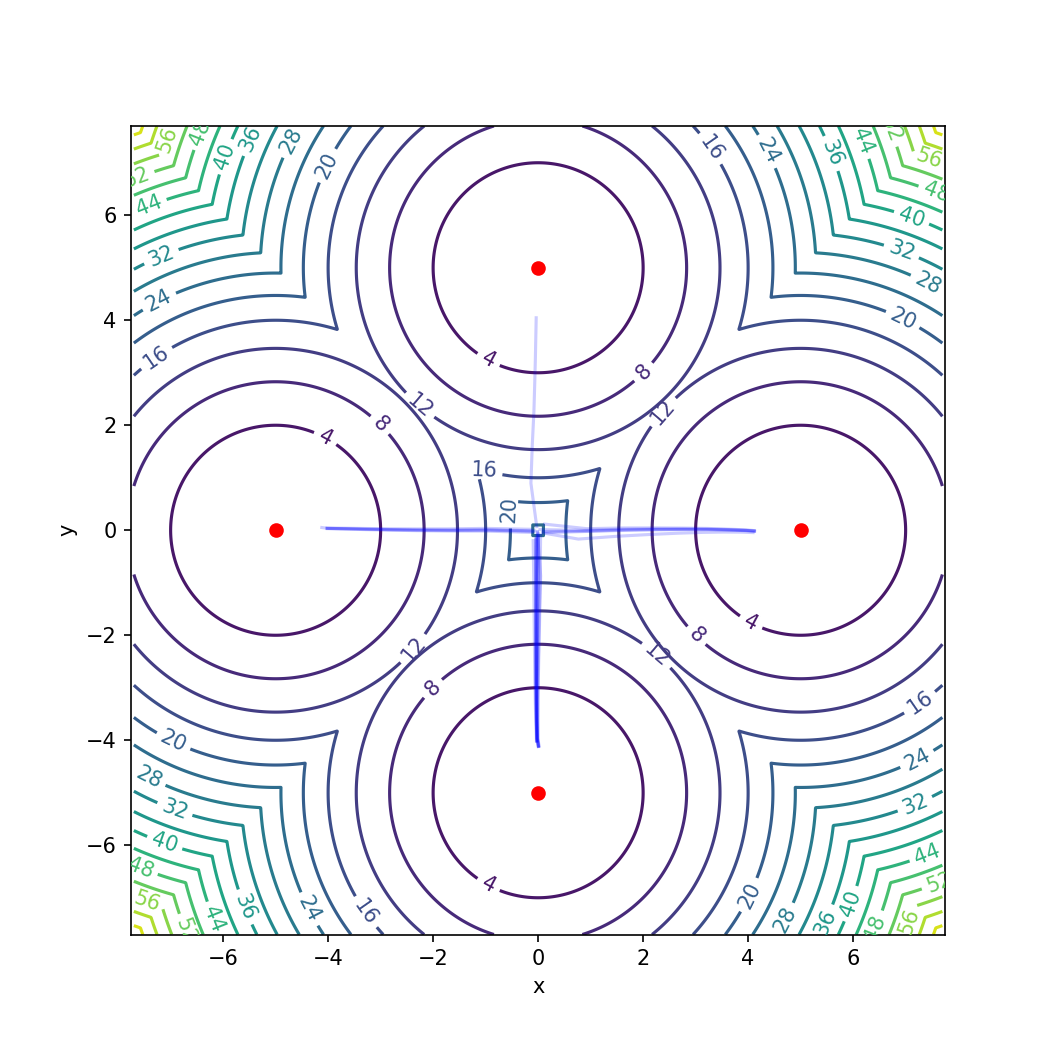
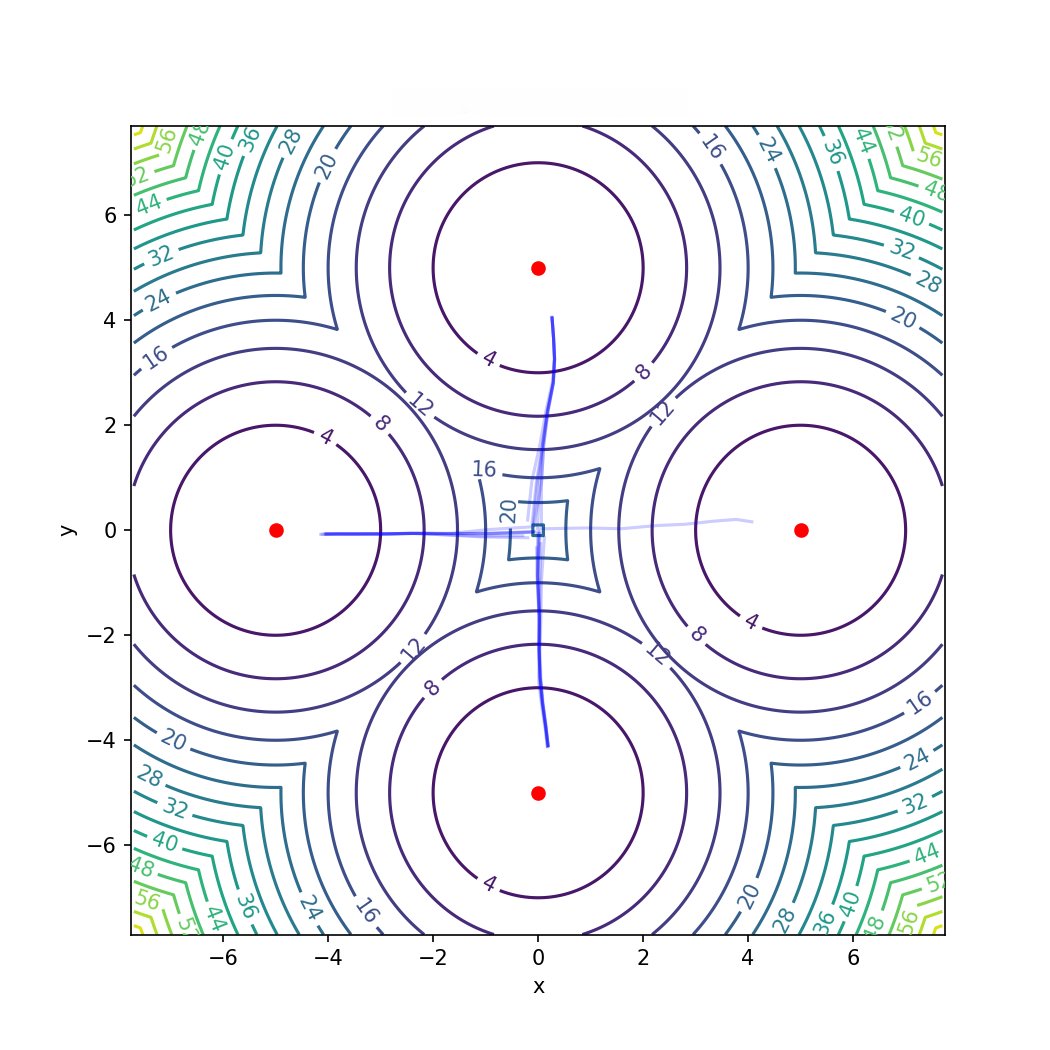
Figure 1: TRFP exhibits uniform multimodal coverage in the multi-goal setting, where baseline Gaussian policies fail to explore symmetrically.
Empirical Results
Multimodality and Policy Capacity
TRFP’s efficacy in representing multimodal policies is validated in a symmetric multi-goal toy environment. Unlike SAC and TD3, which collapse to a subset of goals, TRFP maintains balanced coverage, directly evidencing enhanced expressive capacity (Figure 1).
Benchmark Comparisons and Inference Efficiency
On 10 standard MuJoCo-v5 benchmarks, TRFP is compared against SAC, TD3, and recent diffusion policy baselines (SDAC, MaxEntDP). Under standard sampling (K=4), TRFP matches or outperforms all baselines in cumulative returns. When compressed to one-step inference (K=1), TRFP’s performance remains highly competitive, with minimal degradation, greatly outperforming other generative models at equivalent inference budgets.
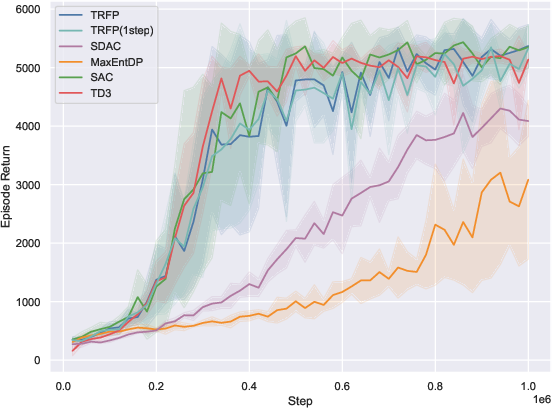
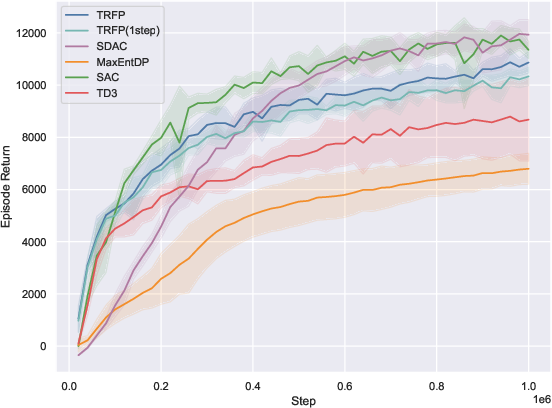
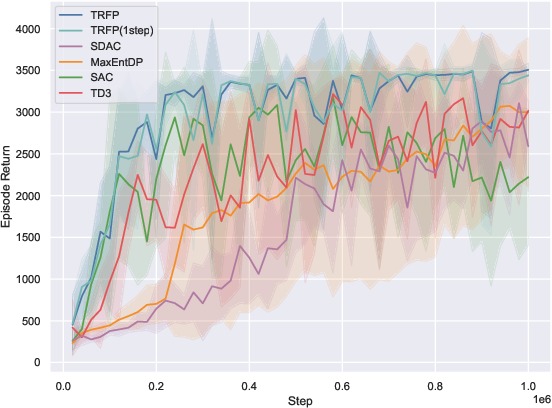
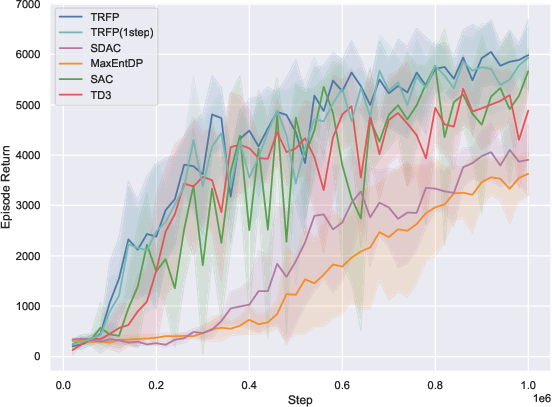
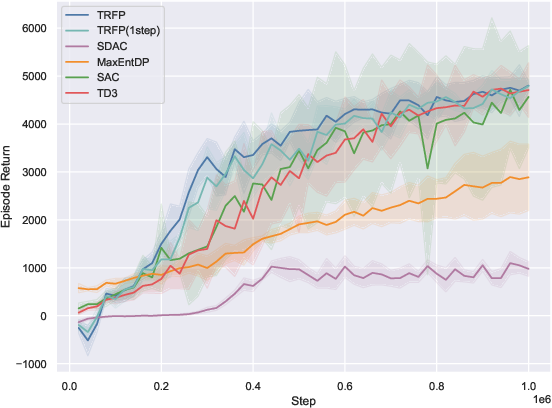
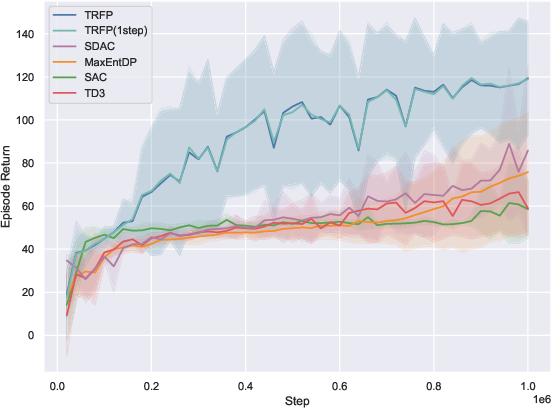
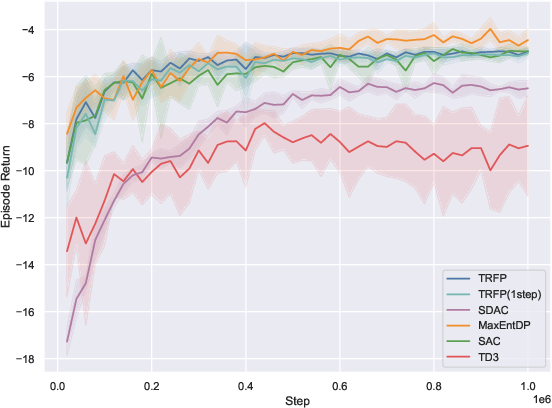
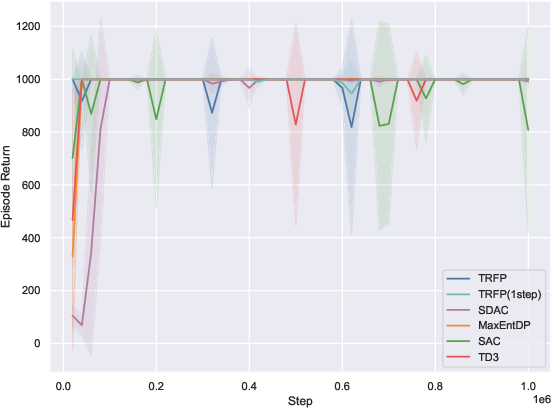
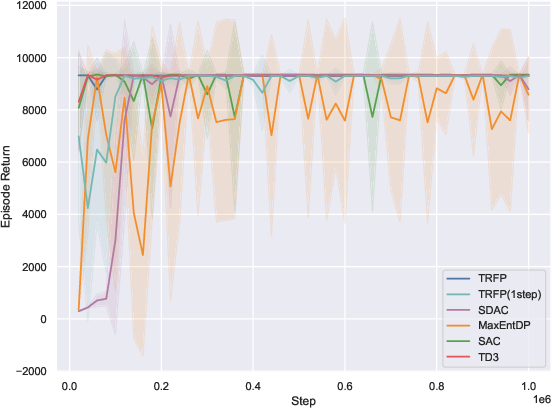
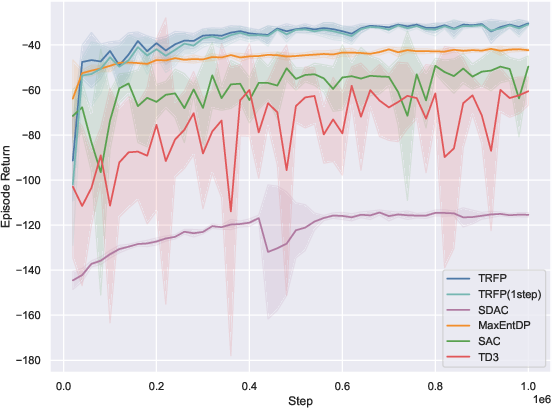
Figure 2: TRFP achieves top returns under both standard and one-step sampling regimes, with lower inference costs compared to prior generative policy methods across MuJoCo benchmarks.
The one-step evaluation demonstrates the effectiveness of flow straightening: high return is maintained with a singular deterministic step, minimizing inference latency—a distinct practical advantage, particularly for real-time applications.
Ablation Analyses
A series of ablations isolate the effect of core architectural and algorithmic components:
- Removing flow straightening (Lfm) drastically reduces one-step performance, affirming its necessity for fast-sampling regimes.
- Disabling Q-guided action selection decreases cumulative return by approximately 10%, indicating the benefit of parallel candidate evaluation and value-guided selection in multimodal policy spaces.
- Omitting the stochastic tail impairs exploration and convergence on complex tasks like Humanoid, consistent with its role in supporting entropy-driven exploration and diversity.
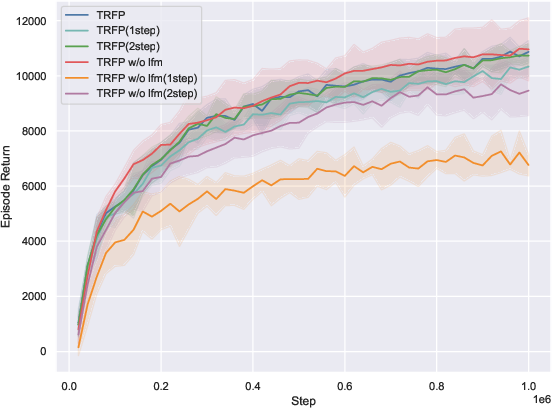
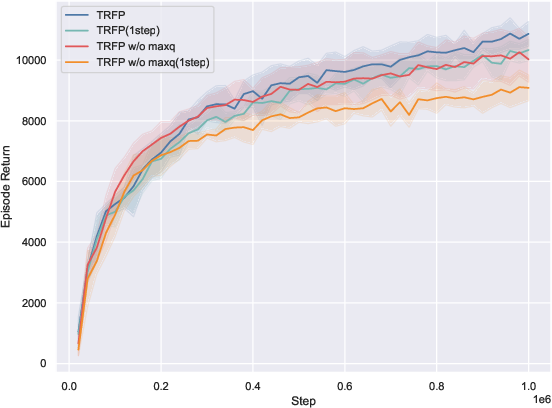
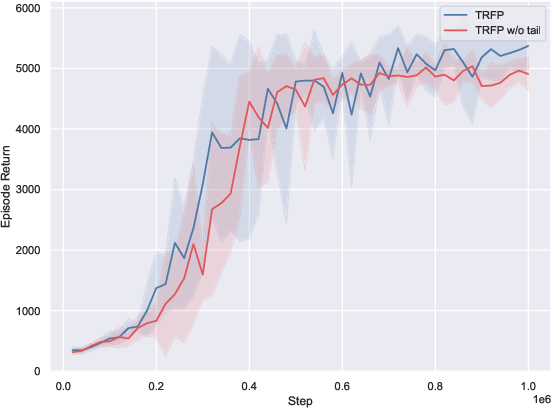
Figure 3: Ablations demonstrate that flow straightening is critical for one-step performance, Q-guided action selection improves robustness, and the stochastic tail accelerates exploration in complex environments.
Implications and Future Directions
TRFP demonstrates that generative, highly expressive flow-based policies can be reconciled with entropy-regularized RL objectives, stable training, and low-latency inference—addressing longstanding issues in the use of DPMs and CNFs for online RL. The hybrid prefix-tail architecture, surrogate likelihood, truncated gradients, and flow straightening regularization collectively deliver a method that is both theoretically sound and practically scalable.
Potential extensions include adapting TRFP to large-scale robot manipulation, real-world robotics, and long-horizon planning, as well as further theoretical refinement of surrogate likelihood error bounds and policy expressiveness. Additionally, TRFP’s decoupled training paradigm could inform future research in offline RL and the fine-tuning of value-conditioned latent-action (VLA) policies.
Conclusion
TRFP provides a principled and empirically validated approach to multimodal policy learning in MaxEnt RL, unifying expressivity, tractable entropy maximization, and efficient, low-latency inference. The experimental results substantiate its superiority over both unimodal and generative baselines across challenging control tasks. The hybrid deterministic-stochastic scheme and flow straightening regularization are of particular importance, serving as essential design choices for future generative policy architectures in RL.