- The paper introduces MFPO, which leverages a learned mean velocity field to reduce integration steps from 16–20 to just 2, boosting sample efficiency.
- The paper integrates an average divergence network and adaptive self-normalized importance sampling for accurate likelihood estimation and stable policy improvement.
- The paper demonstrates state-of-the-art performance on benchmarks like MuJoCo and DeepMind Control Suite with significantly reduced training and inference times compared to diffusion methods.
Mean Flow Policy Optimization: Accelerating Expressive Policy Learning in MaxEnt RL
Introduction
Mean Flow Policy Optimization (MFPO) presents a significant methodological advance in continuous action reinforcement learning (RL), leveraging the recent MeanFlow generative model formalism to circumvent the computational bottlenecks inherent in diffusion-based expressive policy representations. The work systematizes a maximal entropy (MaxEnt) RL paradigm around efficient MeanFlow model integration, introducing novel estimators for action likelihood and policy improvement, and demonstrating compelling empirical and computational performance on high-dimensional continuous control benchmarks.
Background and Motivation
Standard RL approaches in continuous control predominantly utilize unimodal policy classes—either deterministic mappings or Gaussian parameterizations. While such parameterizations are theoretically capable of representing optimal policies, they exhibit poor sample efficiency in environments characterized by multi-modal reward landscapes, often resulting in policy collapse around local optima. Recent efforts have thus adopted diffusion and flow models as policy classes due to their capacity for supporting highly multi-modal, expressive distributions. However, these advances have led to an unfavorable trade-off: high-quality exploration comes at the cost of slow, iterative sample generation, as diffusion models typically require 10–20 step ODE integration per policy evaluation and gradient update.
The MeanFlow methodology modifies the underlying objective by directly learning the average velocity field of the sample transport ODE, reducing the error induced by coarse discretization and enabling accurate generative modeling with as few as two sampling steps. The formal apparatus underlying MeanFlow models thus strikes an improved balance between expressivity and computational cost, motivating its adoption as a policy class in online RL.
The MFPO method represents policies as solutions to an ODE parameterized by the average velocity field uθ, enabling a generative mapping from prior noise to actions via a few-step integration (typically T=2). The model operates under the MaxEnt RL objective, incorporating both external reward and policy entropy into the optimization, and is optimized by soft policy iteration.
Key to this integration are:
Experimental Analysis
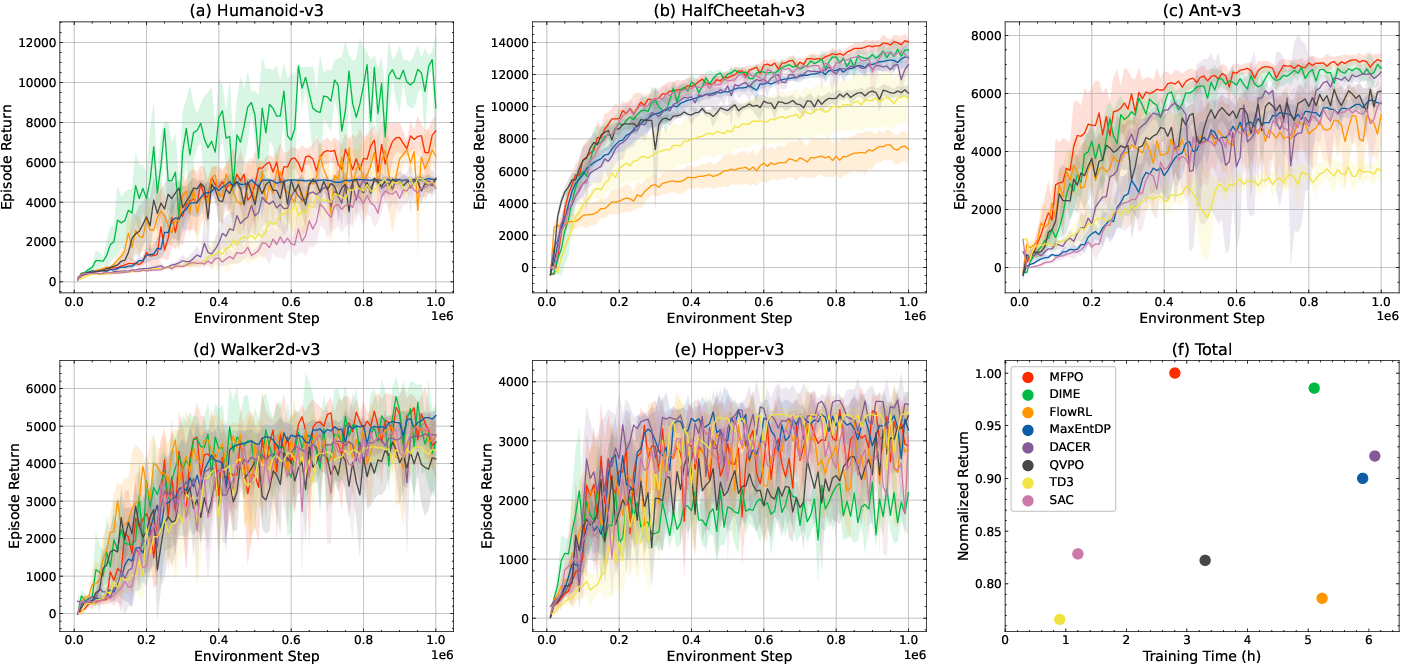
MFPO is empirically evaluated on MuJoCo and DeepMind Control Suite locomotion benchmarks, against state-of-the-art diffusion RL (DIME, FlowRL, MaxEntDP, DACER, QVPO) and classical baselines (TD3, SAC). The results manifest several clear outcomes:
Ablation and Hyperparameter Studies
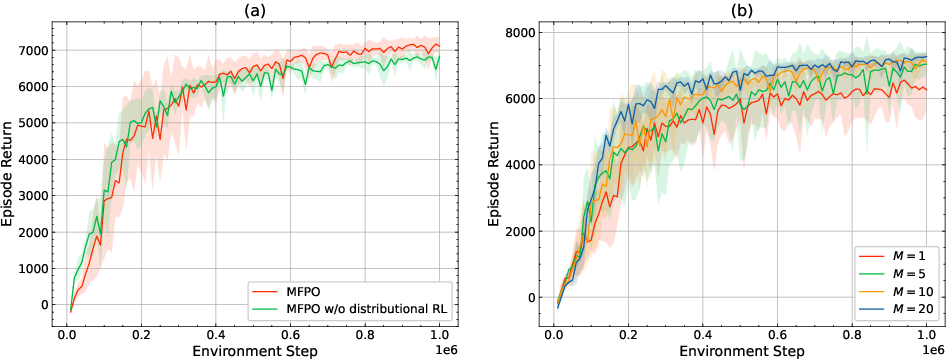
Ablation experiments highlight the necessity of core MFPO components:
- MeanFlow Objective vs. Standard Flow Matching: Replacing the average velocity objective with instantaneous velocity field matching induces significant discretization error, degrading data efficiency and policy return, particularly when limited to a small number of integration steps.
- Average Divergence Network: Disabling the divergence estimator results in collapsed entropy estimates and unstable updates.
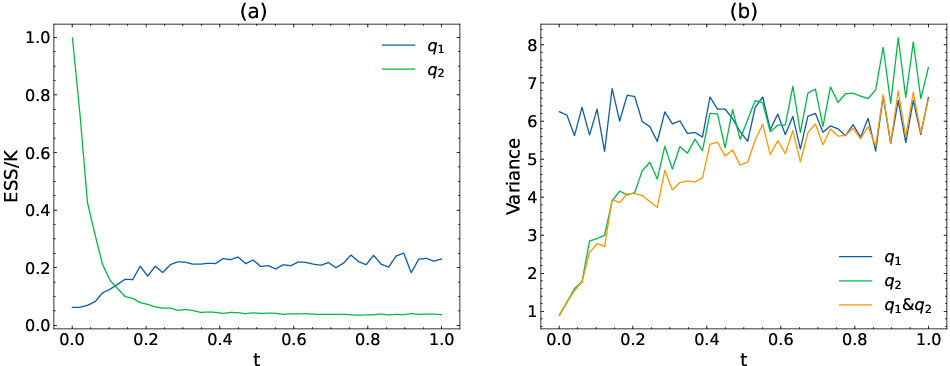
- Adaptive SNIS: Combining Gaussian and policy proposals yields reduced estimator variance and improved policy updates, as confirmed by consistent performance across sampling ratio configurations.
- Temperature Tuning: Adopting automatic temperature adjustment (SAC-style) ensures robust entropy control and stable convergence across environments and reward scales.

Figure 3: Ablations on HalfCheetah-v3 demonstrate effects of various velocity modeling, divergence estimation, proposal mixing ratios, and entropy targets.
Additional Analyses
Practical and Theoretical Implications
MFPO demonstrates that mean-field-based flow models, constructed to be compatible with the MaxEnt RL paradigm via learned divergence approximators and robust policy improvement estimators, can reconcile expressive policy gradients with real-time training and deployment constraints. This reframing challenges the assumption that efficient expressive policy learning necessitates deep ODE integration.
Theoretically, MFPO illustrates the importance of aligning generative policy learning objectives (average-velocity field fitting) with RL training requirements (tractable likelihoods for entropy and importance weighting), opening pathways for extending expressive RL policy families to even lower-latency regimes.
Conclusion
MFPO constitutes a technically principled synthesis of mean-velocity-field-based flows and MaxEnt RL, resolving long-standing challenges in tractable entropy estimation and high-variance policy improvement for expressive, multi-modal policies. The dual estimator system for policy improvement and likelihood estimation enables few-step policy evaluation and improvement without compromise to return or sample efficiency.
While a two-step integration presently remains necessary to maintain expressivity-performance trade-offs, future directions include the design of single-step mean flow policy models, advanced proposal mechanisms, or leveraging shortcut consistency frameworks for further acceleration.