- The paper introduces SEA-Eval, a benchmark that quantitatively measures self-evolving agents through formal definitions and sequential task evaluation.
- It employs a dual-hub 'Evolutionary Flywheel' architecture to distill experience and reduce execution costs over correlated task sequences.
- Experimental results reveal that tracking success rate alone is insufficient, emphasizing the importance of memory-driven adaptation and cost convergence.
SEA-Eval: Systematic Evaluation of Self-Evolving Agent Architectures
The formalization and evaluation of Self-Evolving Agents (SEAs) exposes a fundamental challenge not addressed by existing LLM-based agent benchmarks: capturing cross-task knowledge accumulation and persistent adaptation. Traditional evaluation paradigms, constrained by the episodic agent architecture, enforce memory resets at every episode, precluding measurement of agents' capacity for experience-driven evolution across sequential tasks. The paper "SEA-Eval: A Benchmark for Evaluating Self-Evolving Agents Beyond Episodic Assessment" (2604.08988) rigorously defines the SEA, introduces the Evolutionary Flywheel architecture as the minimal sufficient mechanism for cross-task evolution, and presents SEA-Eval as the first benchmark specifically addressing quantitative evaluation of SEAs.
A Self-Evolving Agent is defined as a tuple (E,A,M,Φ,Ψ), where E models the open-ended environment, A is an extensible action space subject to autonomous tool synthesis, and M is a persistent, multi-level memory. The experience distillation function Φ abstracts structured knowledge from execution trajectories, and Ψ selectively integrates abstractions into memory. This architecture mandates digital embodiment—requiring system-native operation beyond fixed API schemas—and continuous, multi-turn memory evolution.
Figure 1: The Self-Evolving Agent (SEA) architecture, coupling an Execution Hub for digital embodiment and a Cognition Hub for persistent experience distillation, forming the Evolutionary Flywheel.
A key architectural insight is the dual-hub mechanism: the Execution Hub (digital limb) operates over perception and action primitives with autonomous tool expansion; the Cognition Hub (cognitive core) orchestrates memory-based guidance and knowledge abstraction. This closed-loop system is termed the Evolutionary Flywheel, encapsulating (i) execution, (ii) distillation, and (iii) augmented execution, which together drive progressive reduction in execution overhead and enhanced capability transfer.
Evolutionary Dynamics and Failure Modes
Successful operation of the Evolutionary Flywheel is empirically signaled by monotonically converging execution costs (T) over task sequences while maintaining high success rates (SR). Distillation failure (inadequate abstraction by Φ) or retrieval failure (ineffective Ψ-driven recall under environmental drift) both manifest as pseudo-evolution: high E0 with linearly growing or fluctuating E1, indicating absence of practical knowledge consolidation.
The SEA-Eval Benchmark and Evaluation Methodology
SEA-Eval systematically decomposes evolutionary evaluation into intra-task reliability and long-term evolution. The evaluation pipeline is structured to reveal both immediate execution robustness and cumulative learning across sequential task streams.
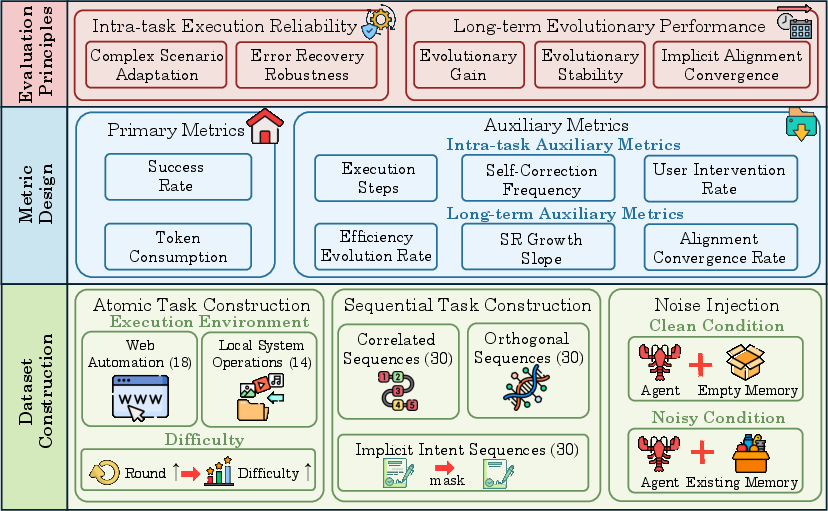
Figure 2: SEA-Eval design pipeline, illustrating the three-layered approach to capture intra-task execution reliability and long-term evolutionary performance.
The dataset consists of 32 atomic tasks (Web Automation and Local System Operations), stratified into three difficulty levels and composed into correlated, orthogonal, and implicit intent sequences. Sequence construction—with variable slot design—controls for answer memorization, ensuring observed efficiency gains derive from transfer and abstraction, not rote recall. Noise injection (skill bloat) further stresses retrieval mechanisms, decoupling memory congestion effects from core evolutionary capability.
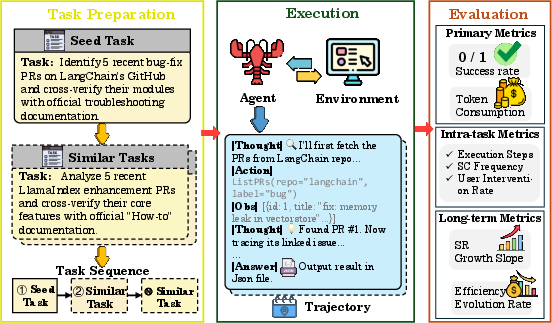
Figure 3: The evaluation pipeline, highlighting ordered task streams, memory persistence, and explicit measurement of evolutionary gain, stability, and implicit alignment.
Primary metrics are E2 and E3, with auxiliary measurements including execution steps, self-correction and user intervention frequencies, efficiency evolution rate (E4), SR growth slope (E5), and alignment convergence rate (E6).
Experimental Results and Comparative Analysis
Static evaluation finds both OpenClaw and GenericAgent achieve 100% E7 on atomic tasks, yet their aggregate token consumption differs by an order of magnitude (OpenClaw: 27,364K vs. GenericAgent: 3,918K; individual tasks up to 31.2E8 divergence). This exposes that merely tracking E9 creates an illusion of agent parity; execution cost (A0) provides greater discriminative power when assessing agent quality.
Under sequential analysis, the contrast is stark. GenericAgent demonstrates genuine evolutionary dynamics: its A1 monotonically decreases across sequential variants of structurally similar tasks, reflecting effective distillation and reuse of procedural knowledge. In the academic database retrieval task, A2 contracts from 520K to 117K. In contrast, OpenClaw's A3 fluctuates and fails to converge, revealing pseudo-evolution and an inability to leverage past experience. In complex multi-variant settings, OpenClaw frequently collapses (null output in latter variants), whereas GenericAgent exhibits robust error-correction and alignment capability.
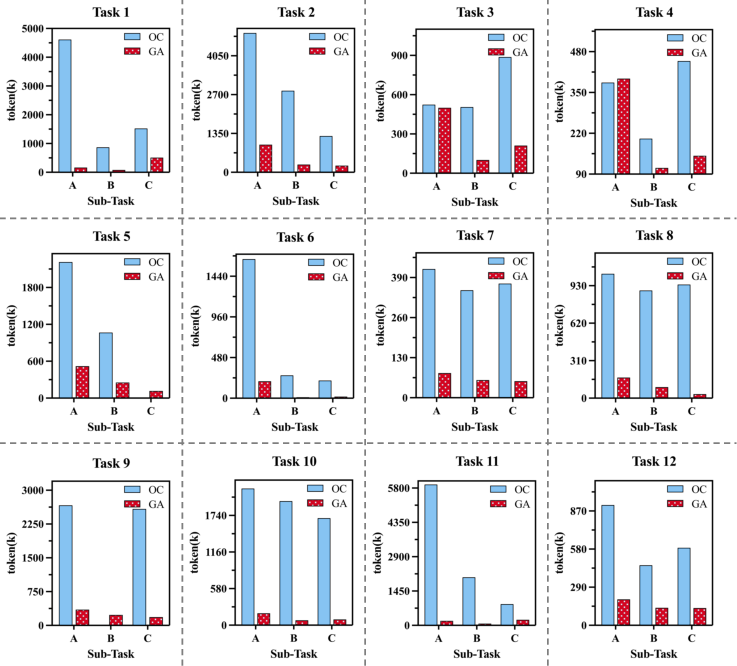
Figure 4: Evolutionary trajectories of OpenClaw and GenericAgent over correlated task streams; only GenericAgent achieves monotonic reduction and stability in token consumption, the empirical signature of genuine evolution.
Notably, even with identical A4, OpenClaw's lack of cost convergence reveals fundamental evolutionary bottlenecks. Efficient experience distillation and retrieval—rather than brute-force model scale—are critical for practical deployment.
Theoretical and Practical Implications
The SEA-Eval framework establishes that episodic evaluation fundamentally mismeasures agentic capability in open-ended environments. By centering its evaluation protocol on sequential cost convergence and memory-driven adaptation, it delivers critical insights into the architectural and systemic requirements for robust SEAs.
Key practical implications include:
- Just metric parity in A5 is insufficient for distinguishing genuinely adaptive systems. Persistent cost reduction (A6 convergence) across task streams must be a primary criterion.
- Pseudo-evolution, prevalent in static benchmarks, is exposed as a substantial barrier to deployment efficiency and reliability. Absent memory-driven adaptation, agent architectures cannot amortize the cost of repeated operations and remain brittle under distribution shift.
- Memory architecture and retrieval robustness are principal levers for agent improvement, paralleling findings in recent works on lifelong learning and agentic memory systems.
The framework explicitly identifies open research frontiers: autonomous bootstrapping of memory, latency/performance trade-offs in multi-model orchestration, collective evolution in multi-agent societies, subjective user alignment, and the integration of systemic governance for safety in agents capable of self-modification.
Future Directions
Addressing the cold-start challenge (enabling agents to initiate their own evolution without external scaffolding), mitigating the latency overhead imposed by reliance on foundation models for cognition, and extending the framework to the multi-agent regime are critical research directions. Furthermore, evaluation protocols that advance beyond behavioral proxies toward subjective alignment metrics—quantifying the depth of user preference internalization—are needed for deployment in high-stakes domains.
Conclusion
"SEA-Eval: A Benchmark for Evaluating Self-Evolving Agents Beyond Episodic Assessment" (2604.08988) provides a formal, reproducible methodology for differentiating genuinely self-evolving agents from superficially competent, cost-inefficient models. By operationalizing sequential performance convergence as the signature of robust evolution and presenting a comprehensive benchmark, the study lays a foundation for designing and evaluating next-generation agentic systems with persistent, cross-task memory and adaptation capabilities. This work delineates the necessary evaluation standards for progress toward practical, reliable, and safe autonomous agents, and signals concrete directions for both architectural innovation and rigorous evaluation methodology.

