- The paper demonstrates that structured hypothesis decomposition with multi-agent orchestration accurately predicts multilingual model performance in evidence-sparse scenarios.
- The system leverages comprehensive typological and linguistic feature libraries to enhance cross-lingual transfer and stabilize predictions across diverse tasks.
- Empirical results reveal significant error reduction and superior performance compared to baselines, setting a new standard for multilingual evaluation benchmarks.
Litmus (Re)Agent: Structured Predictive Evaluation for Multilingual Models
Problem Motivation and Benchmark Construction
Multilingual NLP models are increasingly evaluated across diverse tasks and languages. However, the availability of direct benchmark data for the myriad of task–model–language (TML) combinations remains highly incomplete, particularly for low-resource languages and newly released model families. Performance estimation for TML triples without direct evidence is critical in practical deployment, requiring systems that can robustly infer missing results from incompletely observed research literature.
To address this gap, the paper introduces a controlled, large-scale benchmark and the Litmus (Re)Agent system. The benchmark comprises 1,500 TML queries spanning six core NLP tasks (code generation, mathematical reasoning, QA/VQA, classification/NLI, summarisation, and machine translation) across five evidence scenarios with controlled corpus restriction. Each scenario systematically varies the accessible evidence so that systems must extrapolate or transfer from related TML instances, simulating real-world evidence gaps.
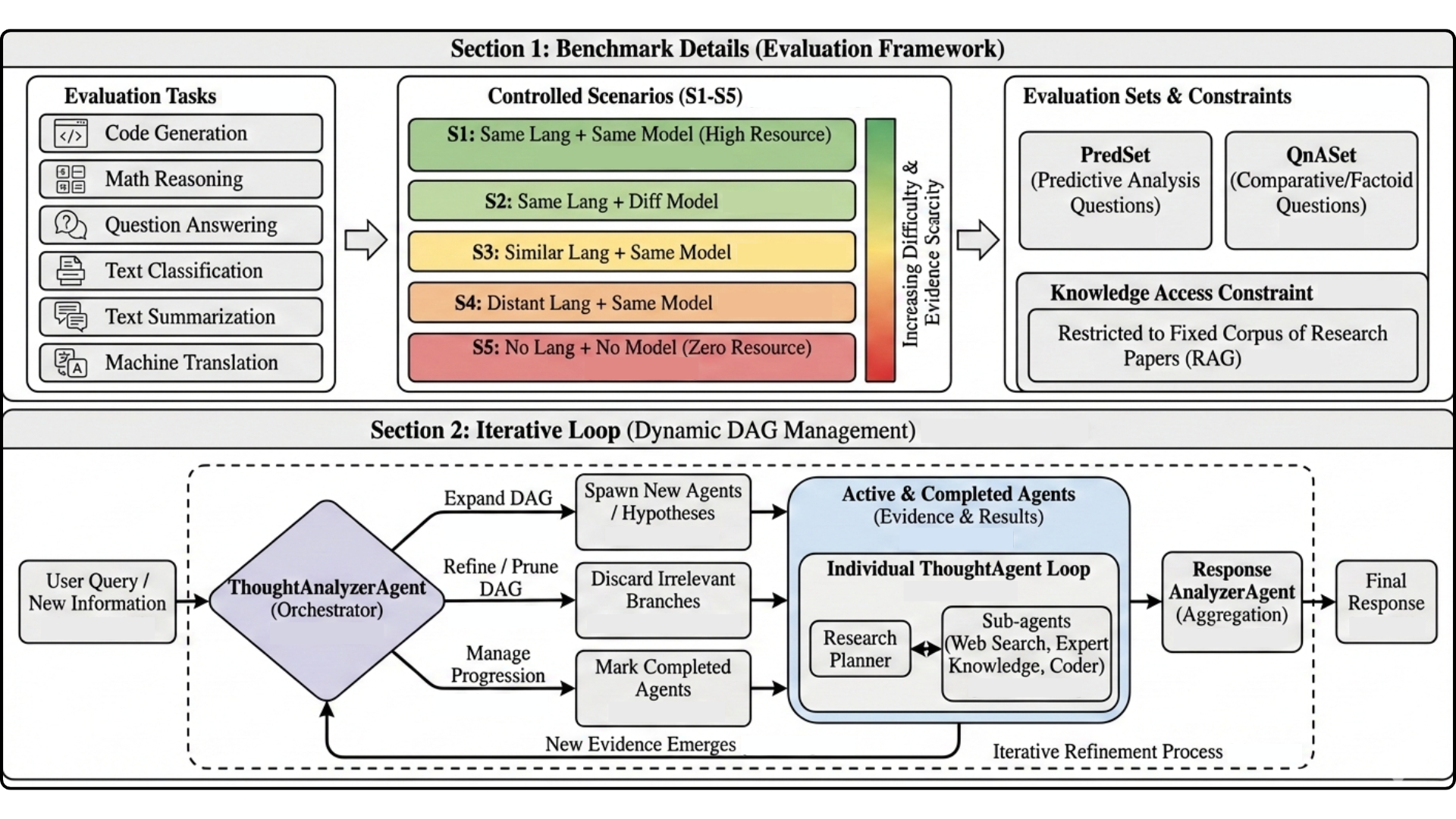
Figure 1: Overview of the benchmark and Litmus (Re)Agent. Top: six tasks, five controlled scenarios (S1–S5), two query types, and restricted paper-corpus access. Bottom: dynamic DAG orchestration in which specialised agents spawn and prune hypotheses, gather evidence, and aggregate results into the final response.
Given this design, the benchmark uniquely separates accessible evidence (for inference) from ground truth (for evaluation), enabling controlled analysis of predictive methods under incomplete literature access.
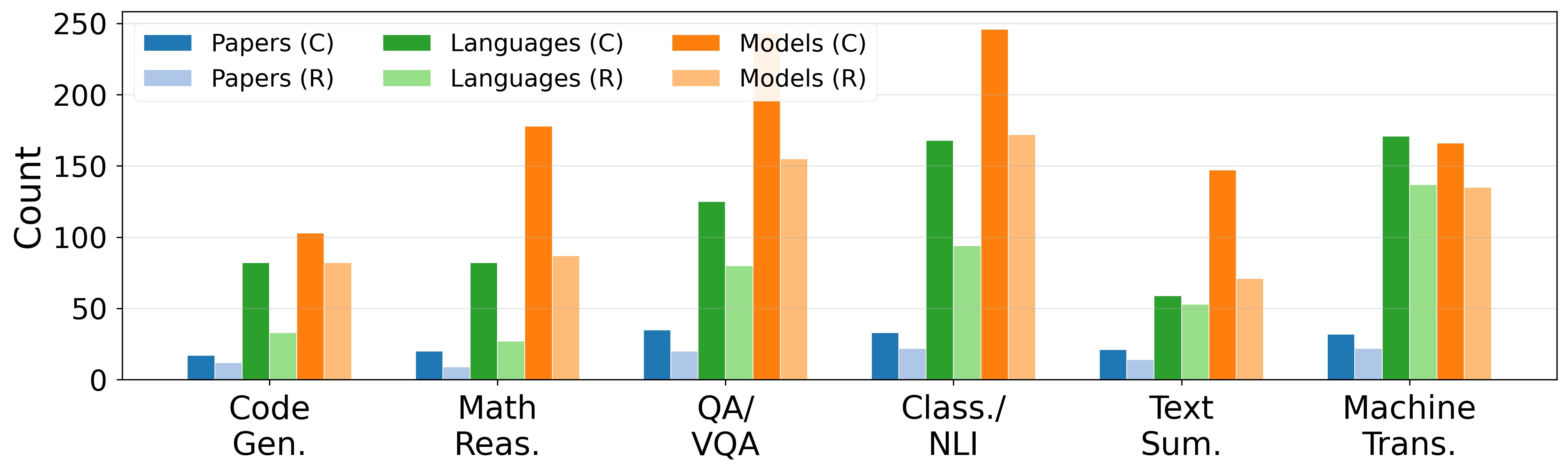
Figure 2: Combined versus reduced corpus statistics per task.
Litmus (Re)Agent: Agentic Architecture for Hypothesis-driven Prediction
Litmus (Re)Agent is a dynamic DAG-orchestrated multi-agent system tailored for predictive multilingual evaluation under restricted evidence. At the core of the system is a decomposition of each TML query into a cascade of hypotheses, each pursued by specialised agent threads ("ThoughtAgents"). Orchestration is governed by a controller agent that coordinates hypothesis creation, management, and aggregation.
Key innovations in Litmus (Re)Agent include:
- Expanded Expert Knowledge Base: Incorporation of a wide-ranging set of cross-lingual evaluation studies and structured, reusable expert strategies.
- Linguistic Feature Libraries: Extended access to typological (lang2vec, URIEL) features for over 7,000 languages, enabling computation of typological/phylogenetic/geographic similarity and informed regression modeling.
- Prompt Stabilization and Modular Tooling: Carefully engineered prompts to match expert evaluation workflows and mitigate hallucination or brittle tool usage, with explicit guidance on evidence gathering, feature analysis, and hypothesis testing.
The modular architecture allows concurrent evaluation of hypotheses, facilitating robust evidence tracing and transparent rationales. The system supports both numeric (PredSet) and comparative (QnASet) reasoning.
Empirical Evaluation and Error Analysis
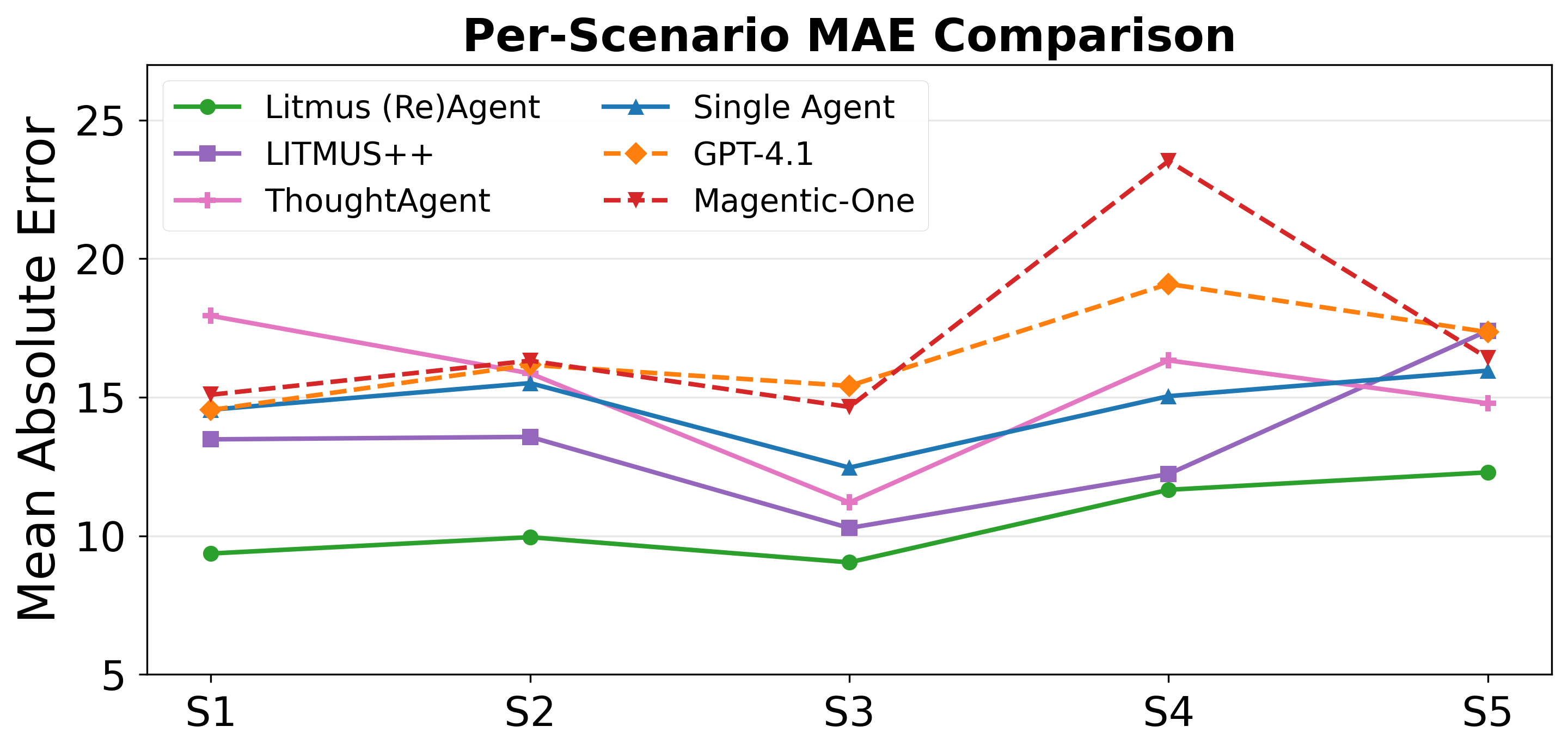
Litmus (Re)Agent is benchmarked against five baselines, including direct LLM prompting (GPT-4.1), a prior DAG-based agentic system (LITMUS++), single- and multi-agent non-DAG variants, and a domain-agnostic multi-agent orchestrator (Magentic-One). Evaluation is performed on MAE for numeric prediction and accuracy for comparative queries.
Strong numerical results include:
Task-wise, code generation and mathematical reasoning exhibit both the largest gains from the system and the highest error, highlighting the challenge of extrapolating in transfer-heavy and evidence-sparse settings.
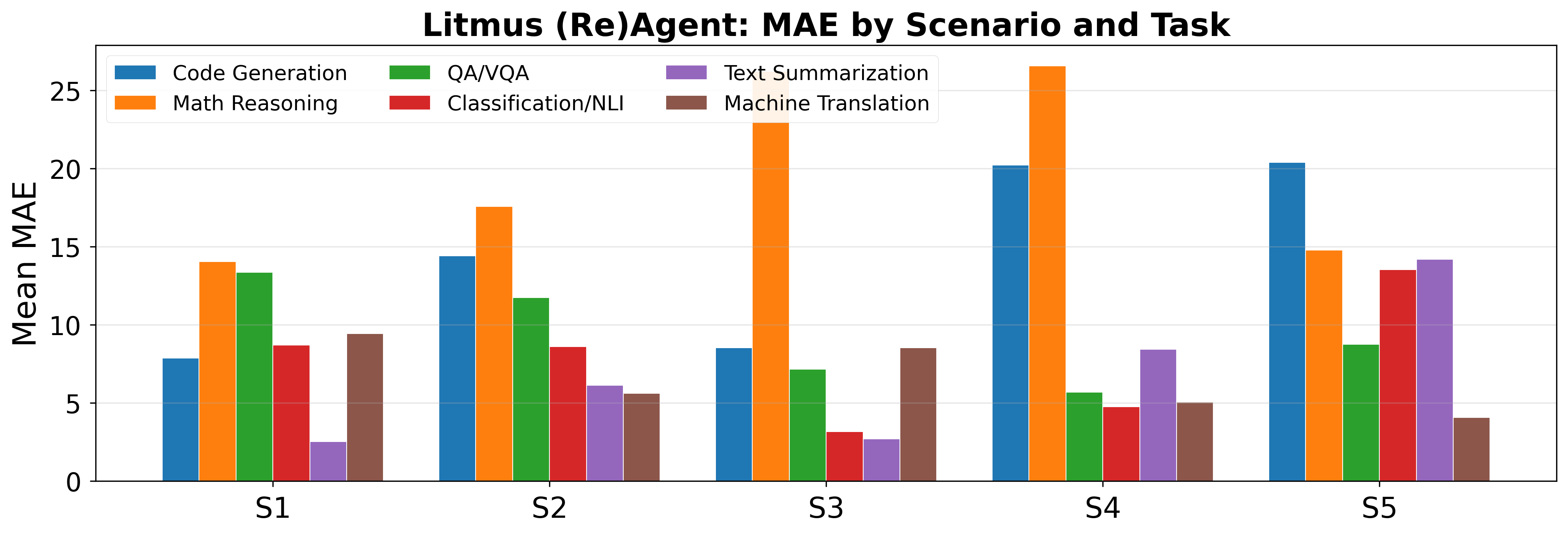
Figure 4: Litmus (Re)Agent: mean MAE by scenario and task. Each group of bars corresponds to one scenario (S1–S5), with tasks shown as different colours. Code generation and mathematical reasoning show higher and more variable error than other tasks.
Error distribution analysis reveals that, particularly in code generation and math reasoning, wide-tailed error persists in the most challenging transfer scenarios, while overlap-based tasks (summarisation, translation) exhibit tighter error distributions.
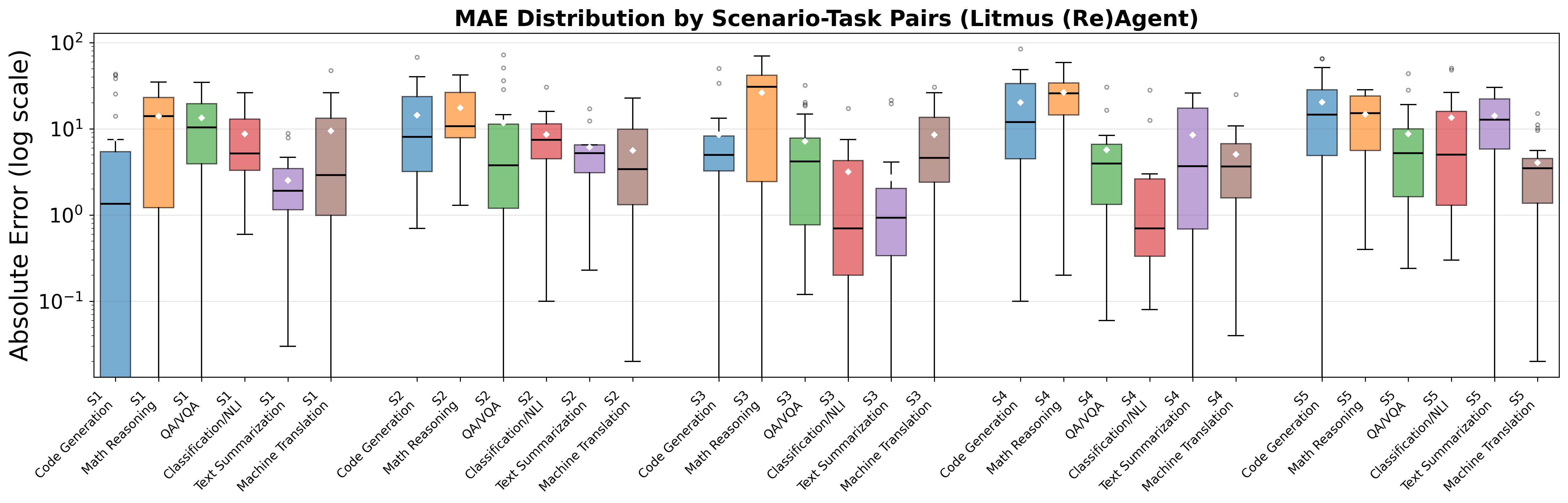
Figure 5: Distribution of per-question absolute errors for Litmus (Re)Agent, grouped by scenario–task pairs (log scale). Diamonds indicate means; horizontal lines indicate medians. Wider boxes and more outliers appear in code generation and math reasoning, especially in transfer-heavy scenarios.
Agentic Reasoning Behavior and Feature Utilization
Diagnostic metrics confirm robust agentic behavior: high hypothesis faithfulness (93.9%), strong feature selection correctness (91.6%), and high evidence retrieval relevance. The system’s main remaining bottleneck is in programmatic code execution (success rate 30.6%), partly due to tool and environment limitations.
Feature heatmap analysis demonstrates consistent use of typological and phylogenetic features, especially in scenarios requiring strong cross-lingual transfer. The Coder agent adaptively selects from a suite of regression models, with Random Forest and XGBoost dominating high-variance, low-data regimes.
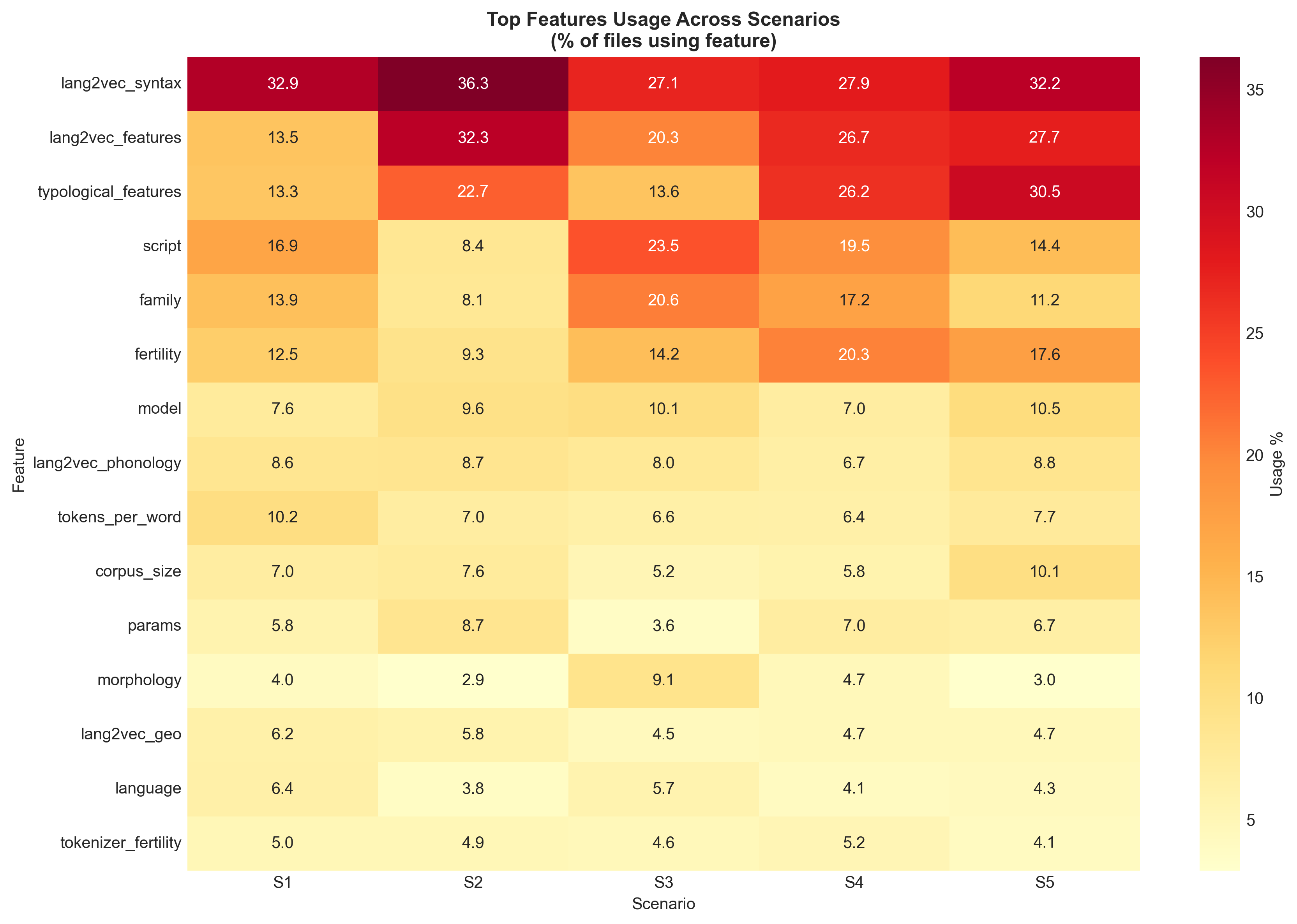
Figure 6: Feature usage heatmap across tasks. Rows represent feature categories (typological, preprocessing, model-based); columns represent tasks. Darker cells indicate higher usage.
Automated LLM-judge quality evaluations, scored along four axes, show that Litmus (Re)Agent leads all systems on predictive plausibility and feature selection (both >4.5/5), while direct GPT-4.1 outputs lead on surface-level coherence and citation formatting.
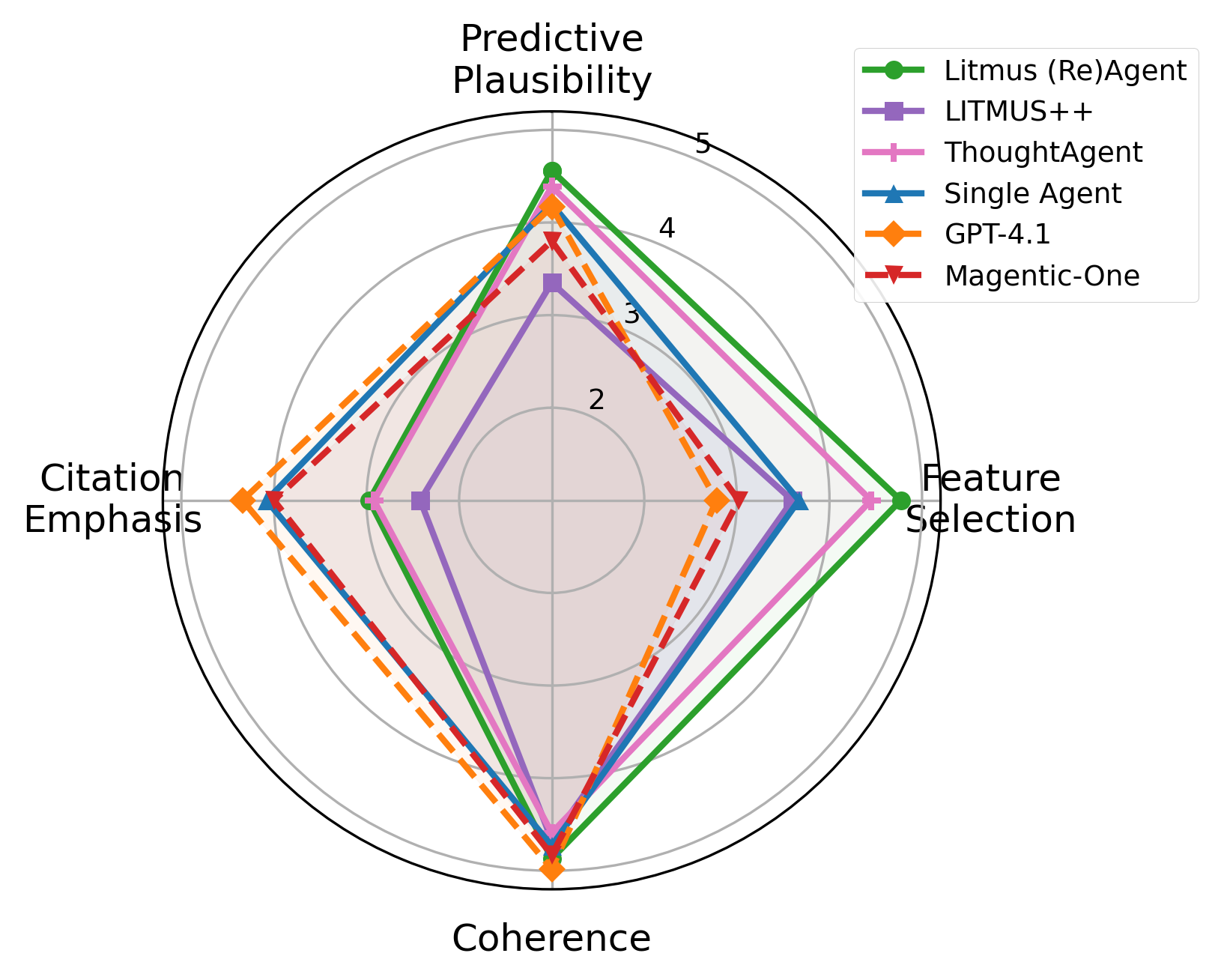
Figure 7: LLM-judge quality metrics (1–5) averaged across all tasks for each system. Litmus (Re)Agent leads on predictive plausibility and feature selection; GPT-4.1 leads on coherence and citation emphasis.
Human Evaluation: Utility for Researchers Across Experience Levels
A within-subjects human evaluation demonstrates that Litmus (Re)Agent substantially improves interpretability, justification, and actionability of predictions for both novice and expert participants, especially for challenging code generation estimation tasks. Novices, in particular, see the largest gains in actionable insight, though at the cost of increased time per task. Experts report that justification quality improves most, pointing to the value of explicit evidence tracing and feature-based reasoning.
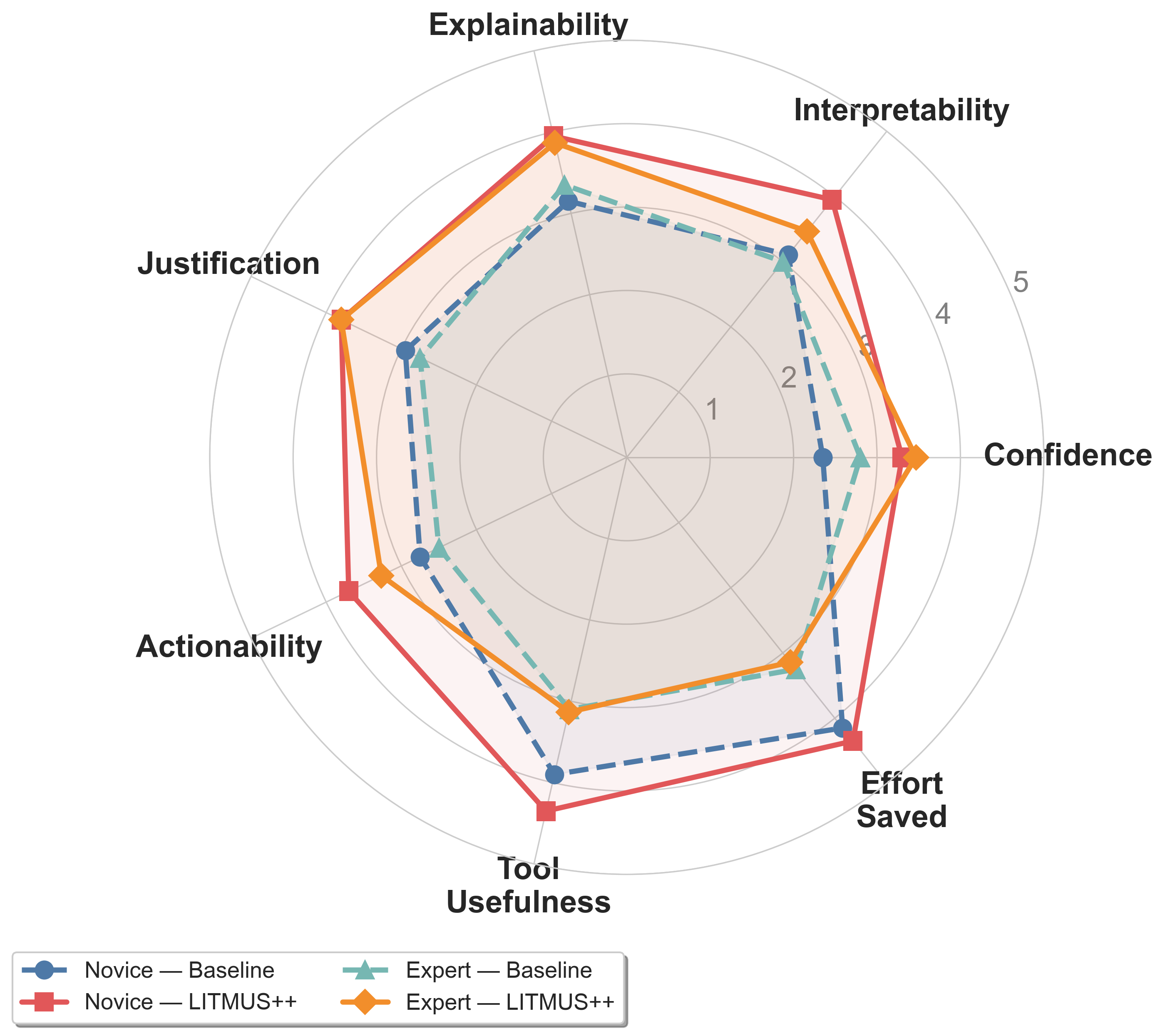
Figure 8: Human evaluation quality metrics by participant type (novice vs. expert) and phase (baseline vs. Litmus (Re)Agent).
Implications and Future Directions
Litmus (Re)Agent provides a proof of principle for agentic, feature-aware, and citation-grounded performance prediction under controlled evidence restriction. The results strongly support the necessity of structured, explicit hypothesis decomposition, especially for tasks and scenarios where direct evidence is weakest and transfer must rely on rich notion of typological relatedness and expert analytic patterns.
The benchmark establishes a new standard for future predictive evaluation studies, supporting fine-grained ablation of system, task, and scenario variables. Architecturally, the findings imply that generic multi-agent scaffolding, while attractive for complex scientific workflows, cannot match the performance of domain-specific, expert-aligned orchestration under evidence scarcity. This insight has direct ramifications for the design of robust evaluation planning tools intended for deployment in under-benchmarked settings.
Given the modular extensibility of the system and the benchmark’s clear separation of accessible evidence versus held-out ground truth, further research directions include:
- Integration with open-source and smaller LLM backbones to test architecture generality beyond GPT-4.1.
- Extension to multimodal and dialogue evaluation, where literature evidence is even more heterogeneous.
- Automated meta-learning of feature selection and orchestration paths, leveraging the structured traces produced by the agentic system.
- Exploration of calibration and uncertainty quantification, especially in regions of the TML space with extreme evidence deprivation.
Conclusion
Litmus (Re)Agent operationalizes structured, agentic reasoning for predictive multilingual evaluation, demonstrating state-of-the-art results in controlled evidence-sparse settings. The combination of dynamic hypothesis decomposition, rich feature modeling, and citation-grounded aggregation enables both robust numeric and comparative prediction for unseen TML triples, advancing the methodology of multilingual evaluation planning and predictive performance estimation under real-world resource constraints (2604.08970).