- The paper demonstrates that HiFloat4 significantly reduces computation and storage requirements in LLM pre-training with less than 1.5% loss relative to BF16.
- It employs a hierarchical scaling design tailored to Ascend NPU architecture, enabling efficient dot-product execution with reduced stabilization overhead.
- Empirical results confirm that HiFloat4 maintains a sub-1% relative error in large models like Llama3-8B and Qwen3-MoE-30B, proving its robustness across architectures.
Introduction
The computational and memory demands imposed by large-scale LLM pre-training create immediate pressures for efficient hardware utilization and aggressive numerical compression. This work systematically evaluates the HiFloat4 (HiF4) numerical format, a 4-bit floating-point representation customized for Huawei Ascend NPUs, and benchmarks it against MXFP4, the Open Compute Project's de facto FP4 standard. The study focuses on quantization strategies, stabilization mechanisms, and hardware alignment, reporting results from experiments with both dense Transformer-based LLMs and Mixture-of-Experts (MoE) architectures.
Strong empirical evidence is presented for the effectiveness of HiF4 in enabling ≈90% of both computation and storage in FP4 with less than 1.5% loss relative to BF16 pre-training, while requiring less stabilization overhead than MXFP4. Key insights include the criticality of format-specific stabilization and the influence of scaling architecture on overall training dynamics and final accuracy.
MXFP4 and HiF4 differ fundamentally in their scaling methodology and metadata allocation. MXFP4 employs private E2M1 element coding within 32-element blocks and a shared E8M0 scale; HiF4 implements a hierarchical three-level scaling design, with a coarse E6M2 top-level scaler, two further micro-exponent modulations, and S1P2 data element encoding across 64-element blocks. This hierarchy improves dynamic range adaptation and local representational flexibility, at the cost of a slight increase in metadata.
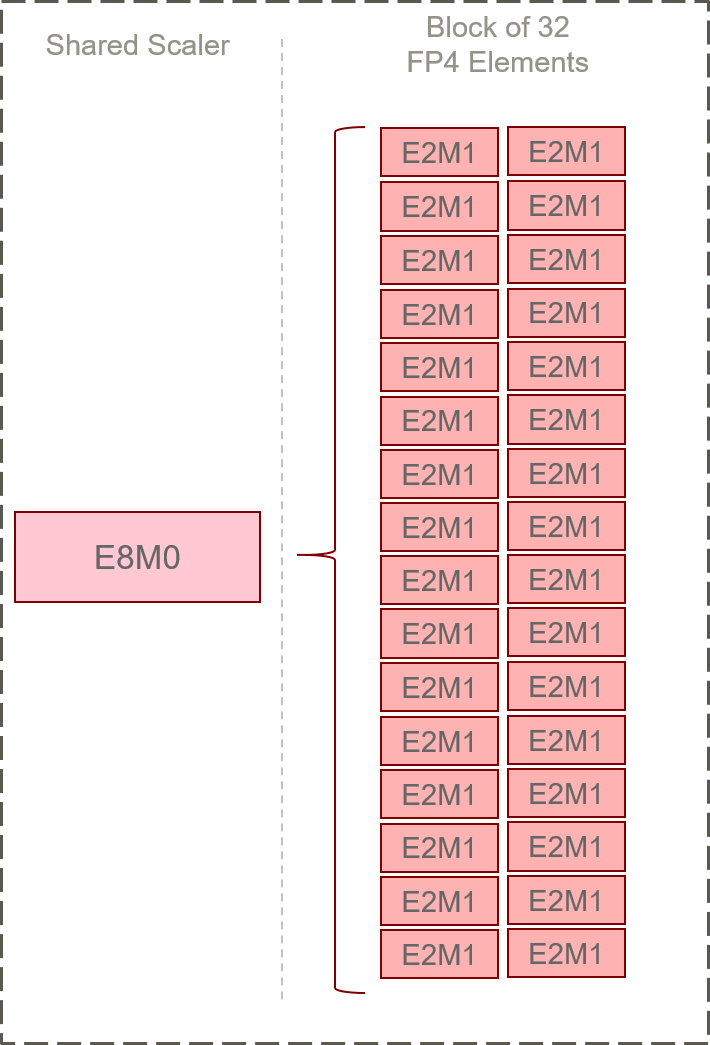
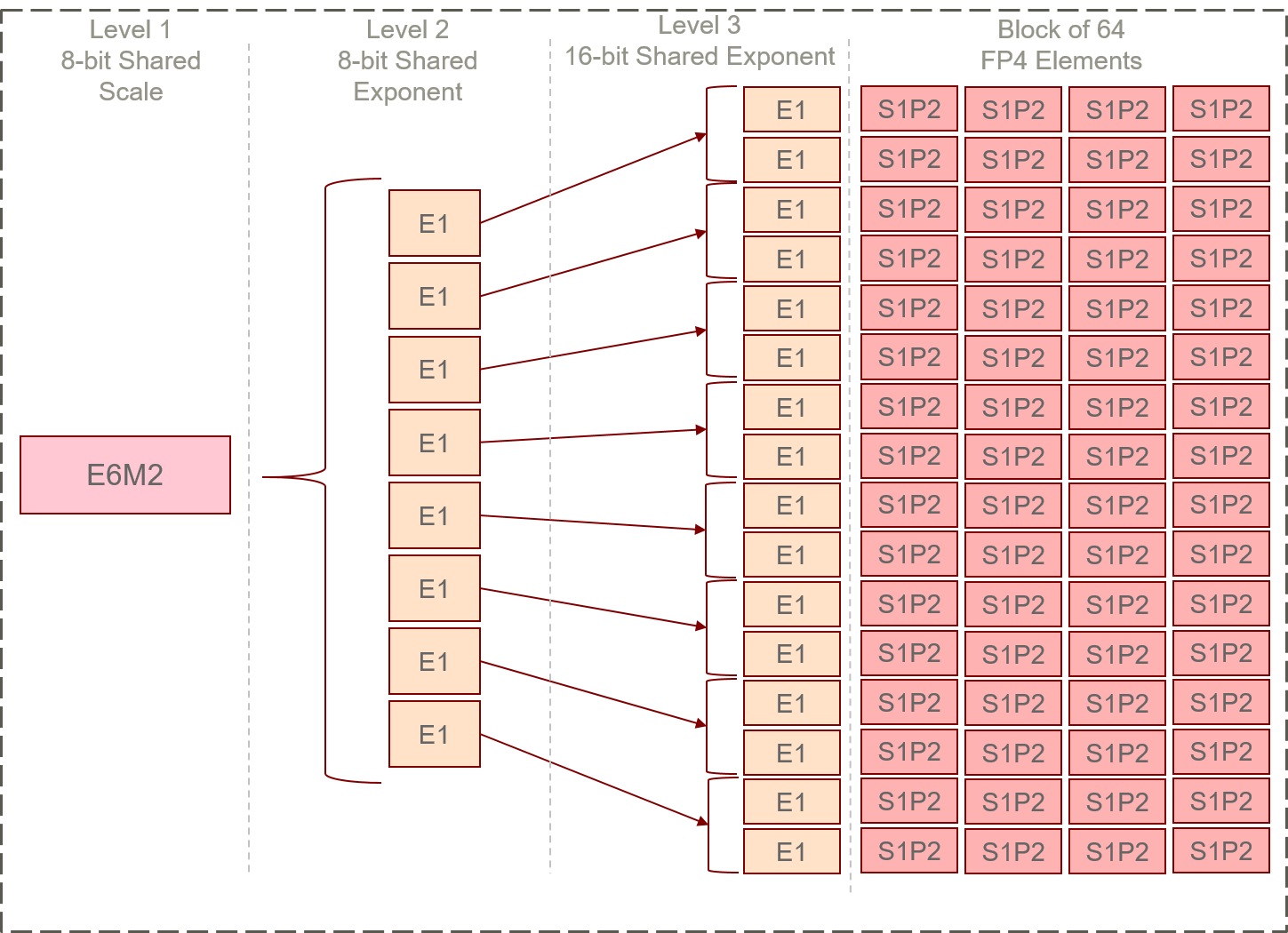
Figure 1: Structural contrast between MXFP4 (compact block scaling, minimal metadata) and HiF4 (hierarchical multi-level scaling, wider block size, and augmented metadata for improved dynamic range).
Alignment with the Ascend NPU architecture is strong: HiF4 block size is tailored to the 256-bit wide input of the Cube Unit’s processing element, permitting direct dot-product execution with minimal format conversion or reduction overhead.
Stabilization Techniques and Operator Placement
Both formats employ aggressive quantization throughout, but stabilization is achieved via distinct strategies. MXFP4 requires truncation-free block scaling, stochastic rounding (SR), and application of random Hadamard transforms (RHT) during weight-gradient computation to mitigate quantization bias, outlier misrepresentation, and value truncation. For HiF4, the inherent stability from hierarchical scaling allows for stable training with only the RHT applied to weight gradients, and nearest rounding (NR) suffices for gradients, a notable reduction in algorithmic overhead.
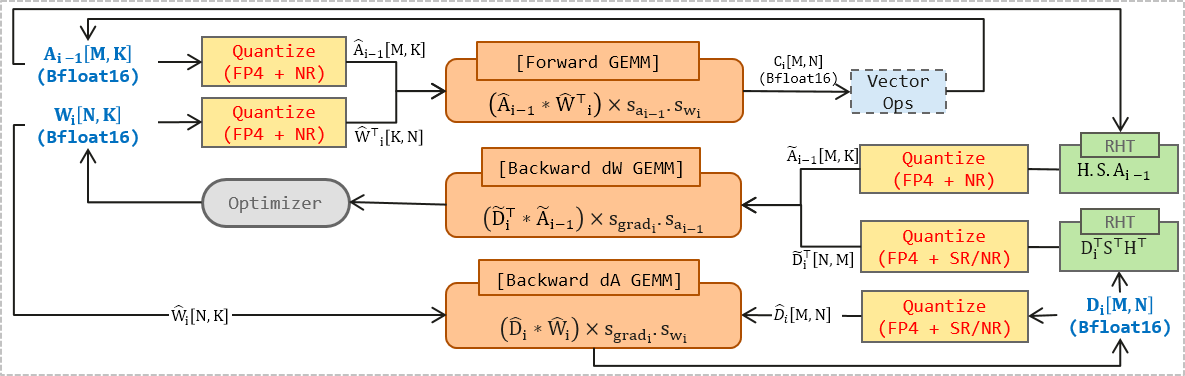
Figure 2: Operational flow for quantized GEMMs highlighting the quantization mode and RHT/SR placements across both forward and backward passes, specific to each FP4 format.
Analysis of Training Dynamics and Empirical Results
Model Coverage and Experimental Setup
Experiments were conducted with three architectures:
- Dense Transformers: OpenPangu-1B and Llama3-8B.
- Mixture-of-Experts: Qwen3-MoE-30B.
The range of models ensures that findings are robust across both dense and sparsely activated large-scale systems. FP4 computation fraction is consistently high, achieving up to 96% in the MoE setting.
Training Loss Evolution and Scaling Effects
HiF4 consistently achieves lower loss gap compared to MXFP4 across all model scales, with performance difference tightening at larger scales. For Llama3-8B and Qwen3-MoE-30B, the relative error remains below 1% for HiF4, confirming its efficacy in large models.
Figure 3: Loss curves for HiF4 and MXFP4 versus BF16 baseline—relative loss gap narrows with increasing model size, and HiF4 remains systematically closer to full-precision performance.
Ablation on Stabilization Components
Analysis of individual and combined stabilization strategies demonstrates that MXFP4’s reliance on all three techniques (RHT, SR, truncation-free scaling) is essential for sub-1.5% loss. HiF4, in contrast, is largely unaffected by SR, and its optimal tuning involves only RHT for weight gradients. This asymmetry is traced to HiF4’s scaling architecture that circumvents block-level value truncation and reduces block-wise representational collapse.
Practical and Theoretical Implications
Hardware Alignment
HiF4’s design parallels the width and data layout of Ascend NPU’s Cube Units, optimizing compute and memory traffic on domain-specific processors. This stands in contrast with NVFP4 and FP8, whose block sizes and scaling factors map less naturally to specialized hardware, resulting in higher energy and area costs.
Impact for Dense and Sparse Architectures
The demonstrated ability to train both dense and MoE models stably in near-end-to-end FP4 brings immediate relevance to efficiency-constrained scenarios such as edge deployment and training at scale under power/cost restrictions. The significant idle parameter footprint in MoE models further amplifies storage benefits without engaging compute in inactive expert branches.
Future Trajectories
The robust results for FP4 pre-training suggest the next research directions: extending ultra-low precision schemes to reinforcement learning (e.g., RLHF, GRPO), where optimization is highly sensitive to quantization noise, and examining stability in long-context or multimodal training regimes where cross-modal variance and activation heterogeneity may present further challenges.
Conclusion
This study establishes HiF4 as a highly competitive FP4 format for LLM pre-training, especially on Ascend NPU platforms. HiF4’s hierarchical scaling inherently stabilizes optimization and obviates much of the overhead necessary for other FP4 formats. As model scales increase, HiF4 maintains minimal loss degradation, making aggressive low-precision quantization an increasingly tenable strategy for efficient large model training. These findings position hardware-tailored numerical formats combined with format-aware stabilization as key to practical, energy-efficient foundation model development.
References:

