- The paper introduces HiF4 as a hierarchical 4-bit block floating-point format that improves quantization accuracy for LLM inference by balancing dynamic range and hardware cost.
- It employs a novel three-level scaling metadata structure, reducing quantization error by 24% to nearly 50% compared to state-of-the-art 4-bit formats.
- The design optimizes hardware mapping with a 64-element grouping that minimizes multipliers and power consumption, enhancing robustness across various language models.
Introduction
The proliferation of LLMs has heightened the demand for enhanced throughput and memory efficiency while preserving accuracy and minimizing hardware energy footprint. Recent trends in accelerated deep learning have emphasized aggressive quantization, focusing on sub-8-bit formats. However, in the 4-bit regime, existing schemes such as MX4, MXFP4, and NVFP4 present fundamental trade-offs among dynamic range, quantization error, and implementation cost. The "HiFloat4 Format for LLM Inference" (2602.11287) introduces HiF4, a 4-bit hierarchical block floating-point (BFP) format that balances these constraints by integrating a novel three-level scaling hierarchy and 64-element group size, with tailored metadata distribution and hardware-centric design, advancing both inference accuracy and compute efficiency for LLMs.
Design and Specification of HiF4
HiF4 encodes each block of 64 in-group 4-bit elements together with 32 bits of shared scaling metadata, resulting in a net cost of 4.5 bits/value. The metadata implements a three-level scaling hierarchy: a top-level 8-bit E6M2 floating-point scale (with six exponent and two mantissa bits), an 8-way 1-bit mid-level micro-exponent, and a 16-way 1-bit bottom-level micro-exponent. The in-group data utilizes a sign-magnitude S1P2 representation, optimizing significand precision for sub-8-bit accuracy.
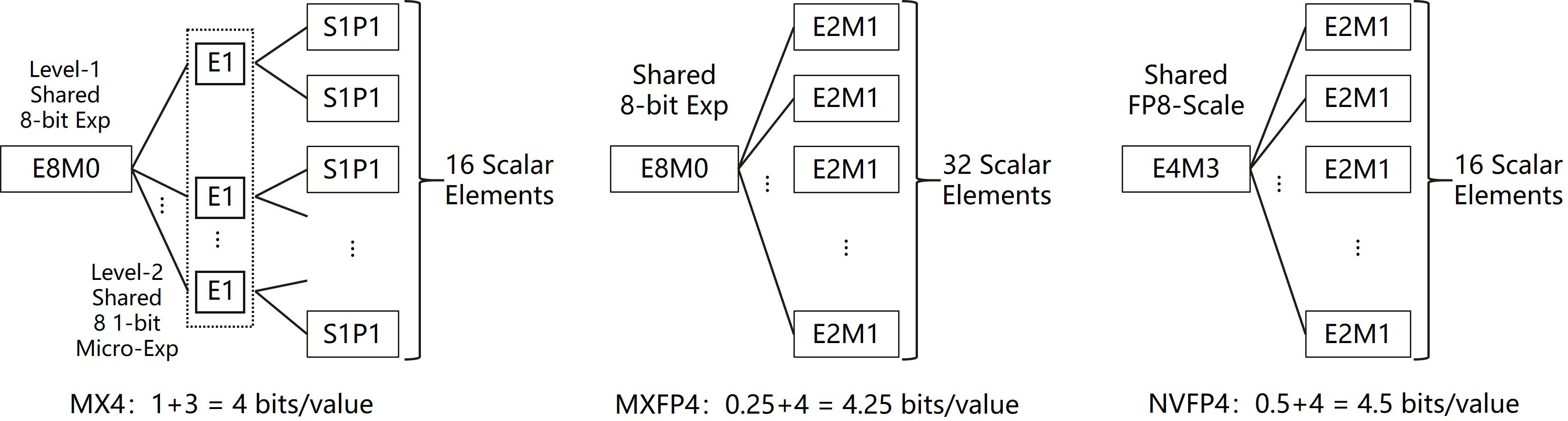
Figure 1: The structure and scaling metadata organization of three influential 4-bit BFP formats compared in the study.
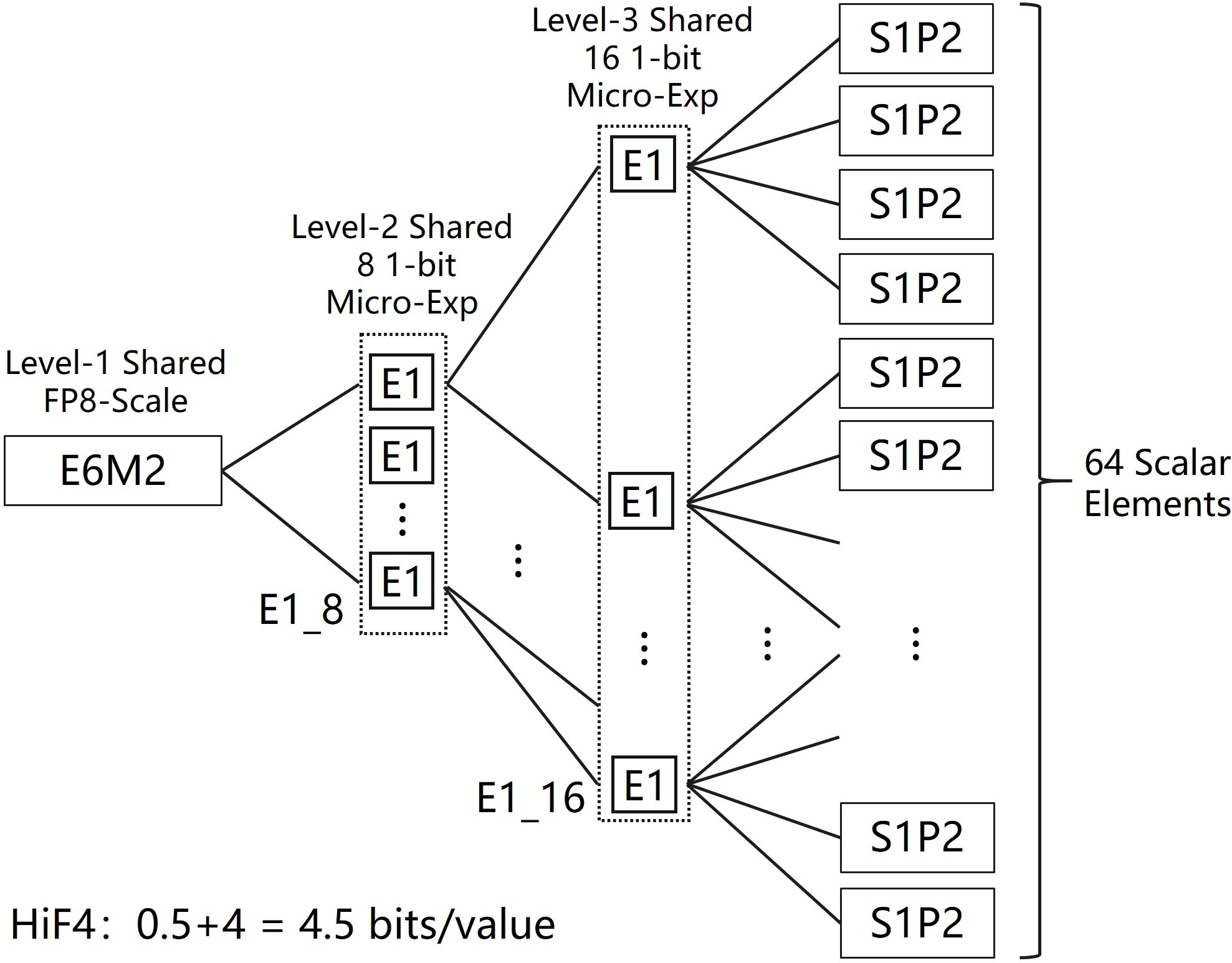
Figure 2: Architecture of the HiF4 Block Floating-Point format, showing three-level scaling metadata and group mapping.
Critically, the metadata structure enables HiF4 to support a global dynamic range of 69 binades, with a local (intra-group) range of 4.81 binades—both surpassing NVFP4’s 22 binade global and 3.58 binade local ranges. Unlike MX4 and MXFP4, which suffer from serious losses in accuracy due to either overhead or reduced significand precision, HiF4’s 0.5 bit/value overhead is amortized across a larger group and maintains 3-bit significand digits. This architecture allows HiF4 to capture both inter-group and intra-group statistical diversity typical in LLM weights and activations.
Conversion of high-precision tensors (e.g., BF16) to HiF4 is realized by hierarchical tree reduction to extract local/group maxima and subsequent quantization using hierarchical scaling. Rounding follows standard round-half-to-even or round-half-away-from-zero schemes. The E6M2 reciprocal computation is facilitated via a minimal-lookup-table-driven instruction. Fused multiply-compare and multiply-convert instructions are recommended for high-throughput HiF4 conversion on dedicated AI hardware.
Quantization Error Analysis
A comparative mean squared error (MSE) analysis demonstrates HiF4’s quantization advantages versus MXFP4 and NVFP4. When evaluated on high-variance synthetic Gaussian matrices, HiF4 consistently yields lower normalized MSE across a full range of scales, reducing error by 24% relative to NVFP4 and by nearly 50% relative to MXFP4.
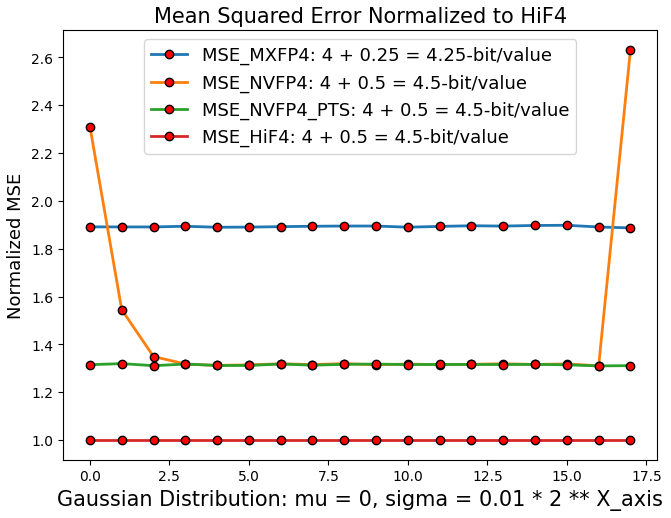
Figure 3: Normalized quantization error (MSE) comparison across three 4-bit BFP formats; HiF4 achieves lower error throughout the evaluated dynamic range.
NVFP4’s error surges for values outside its limited range, forcing reliance on pre-quantization per-tensor scaling (PTS), incurring additional software and memory traffic overhead. HiF4, in contrast, handles the full range without additional preprocessing or nontrivial quantization artifacts.
Dot Product Computation and Hardware Implications
The HiF4 dot-product flow leverages the large group size to map directly onto wide datapaths (e.g., 64-element parallel dot) in compute elements like tensor cores or matrix-multiply engines. Both level-2 and level-3 micro-exponents reduce to shifts prior to multiplication, enabling accumulation to progress in purely fixed-point fashion with minimized floating-point operations until terminal reduction.
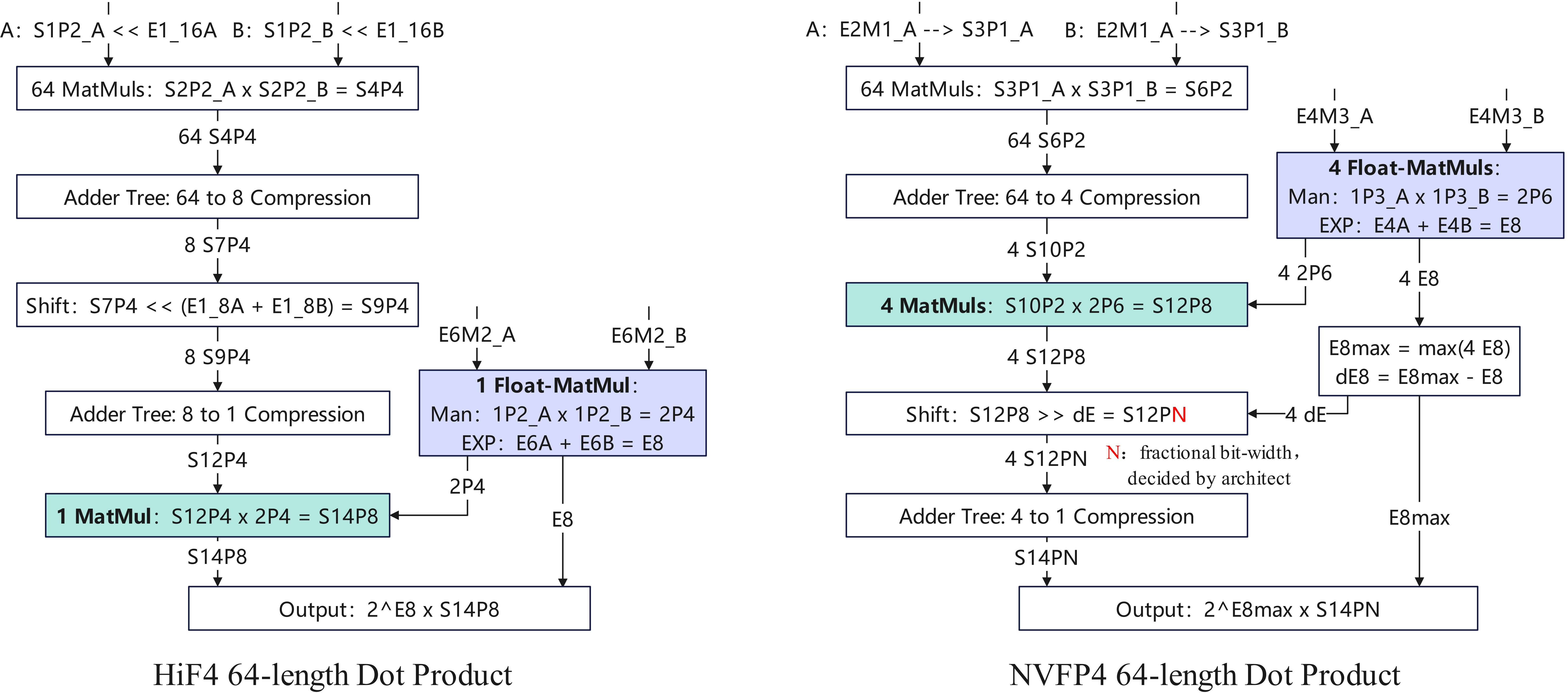
Figure 4: Compute flow for 64-element dot products in HiF4 and NVFP4; HiF4 reduces floating-point operation requirements.
Due to the 64-element block structure, HiF4 reduces both the number of required multipliers (six fewer than NVFP4 per block, in a typical implementation) and minimizes the floating-point accumulation footprint, yielding approximately one-third the incremental die area and 10% lower power than NVFP4 for equivalently sized compute units.
LLM Inference Results
Extensive ablation and benchmark results underpin HiF4’s superiority for quantized LLM inference. The evaluation encompasses direct-cast and PTS-enhanced flows for HiF4 and NVFP4 on mid-sized and large LLMs (LLaMA2-7B, LLaMA3-8B, Qwen2.5-14B, Mistral-7B, DeepSeek-V3.1-671B, LongCat-560B), spanning standard NLP benchmarks such as ARC, BoolQ, HellaSwag, and MMLU.
HiF4 direct-cast consistently surpasses NVFP4 direct-cast and NVFP4+PTS in top-1 accuracy and mean retention across all models except for pathological failure cases wherein NVFP4 exhibits catastrophic accuracy drop (“crashes”) due to dynamic range limitations—scenarios where HiF4 remains robust.
Moreover, HiF4 is compatible with state-of-the-art PTQ methods such as GPTQ—with a straightforward adaptation to exploit HiF4’s hierarchical block structure, further narrowing the gap to unquantized baselines and occasionally outperforming BF16 accuracy on specific evaluation slices.
Theoretical and Practical Implications
HiF4’s architecture exposes new trade-offs in constrained-precision DNN computation: large group size mitigates metadata overhead and improves hardware utilization, while hierarchical scaling and higher significand precision elevate quantization fidelity. From a theoretical lens, it demonstrates that 3-bit significand (S1P2/E1M2) architectures in combination with multi-level micro-exponents and proper metadata structuring deliver quantization properties unattainable in simpler BFP or strictly floating-point schemes with limited mantissa or exponent width.
Practically, HiF4’s design facilitates efficient integration within existing hardware units (tensor/matrix cores) originally tailored for higher-precision FP/BFP arithmetic, without the performance and area/power sacrifices imposed by 16-element block or excessive floating-point dependencies. The result is a framework with implications for both training and inference, notably when applied to large-scale LLMs and high-throughput deployments specialized for 4-bit quantization.
Future Directions
The methodology underlying HiF4 opens several research avenues:
- Extension and characterization of HiF4 for end-to-end training (not just PTQ/inference), building upon its expansive dynamic range.
- Architectural exploration for further metadata compression or adaptive block sizing to better fit context-dependent workload properties.
- Application of HiF4 to other domains, including vision transformers or large-scale foundational models in multimodal setups, where quantization stability is paramount.
Conclusion
The HiF4 format advances the state of the art in 4-bit BFP quantization for deep learning, offering superior quantization error, scalability, and implementation efficiency compared to previously adopted formats such as MXFP4 and NVFP4 (2602.11287). Empirically, HiF4 confers consistent improvements in inference accuracy across a spectrum of LLMs, delivers greater resilience in adverse scenarios, and optimally matches the architectural profile of contemporary AI accelerators. Its introduction marks a reference architecture for subsequent BFP designs targeting the intersection of accuracy and hardware efficiency for next-generation AI workloads.