- The paper introduces a novel scaling law that optimizes the trade-offs in FP4 quantized training for large language models.
- The paper presents the Quartet algorithm with custom CUDA kernels, achieving competitive accuracy and up to 2x speedup over FP8 baselines.
- The paper demonstrates that native FP4 training efficiently balances computational cost and model accuracy for billion-scale language models.
Quartet: Native FP4 Training for LLMs
The paper "Quartet: Native FP4 Training Can Be Optimal for LLMs" explores the possibility of training LLMs using the FP4 precision format, aiming to address the growing computational demands of LLMs by leveraging efficient low-precision computations. The proposed algorithm, Quartet, focuses on end-to-end training in FP4 precision, utilizing NVIDIA's Blackwell architecture and its support for the microscaling format, MXFP4.
Introduction to FP4 Training
The increasing computational resources required for training LLMs present a significant challenge. Lowering precision in computations, such as those executed by MatMul operations, can lead to improvements in both throughput and energy efficiency. The NVIDIA Blackwell architecture supports ultra-low arithmetic precision operations, including FP4, offering potential efficiency gains. However, previous attempts at FP4 training have suffered from accuracy degradation, often reverting to higher precision computations as a fallback.
Quartet Framework and Contributions
Quartet introduces a systematic FP4 training approach by analyzing and utilizing a newly proposed scaling law to optimize the accuracy-versus-computation trade-offs. This scaling law is tailored to account for varying bit-widths during training. Quartet is implemented through custom CUDA kernels optimized for execution on NVIDIA Blackwell GPUs, aiming to achieve high-FLOP performance.
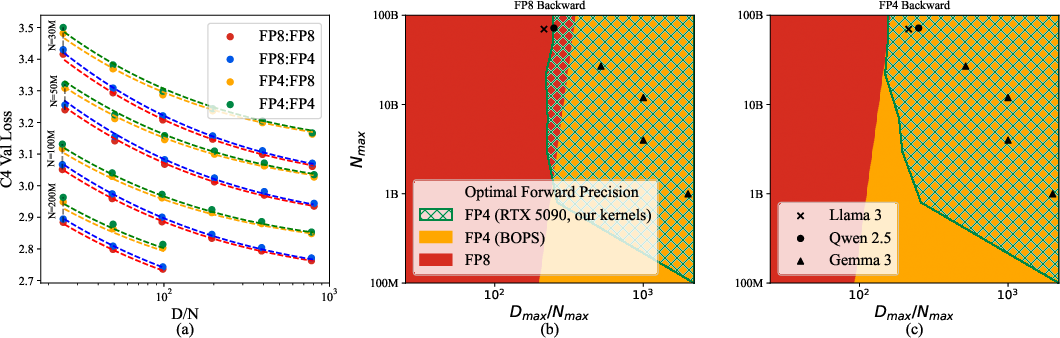
Figure 1: Analysis of Quartet: (a) Scaling-law fit and various model precisions evaluated.
Key Contributions
- Quantized Training Scaling Law: Quartet proposes a new scaling law that captures the performance trade-offs involved in low-precision training. This law serves as the basis for comparing different quantized training methods and predicting optimal precision setups based on computational and data budgets.
- Algorithm for Optimal MXFP4 Training: The Quartet algorithm demonstrates competitive accuracy for LLMs trained entirely in FP4 format while achieving significant computational efficiency improvements over FP8 baselines.
- CUDA Kernels for Efficient Execution: Quartet's implementation employs optimized CUDA kernels that align with the specific execution capabilities of Blackwell architecture, enabling efficient low-precision matrix multiplications.
Technical Details
Scaling Law and Efficiency Metrics
The scaling law, a pivotal aspect of Quartet, encompasses parameters for assessing efficiency relative to model size (N) and dataset size (D). Two derived metrics, parameter efficiency (effN) and data efficiency (effD), guide the method towards achieving optimal training configurations.
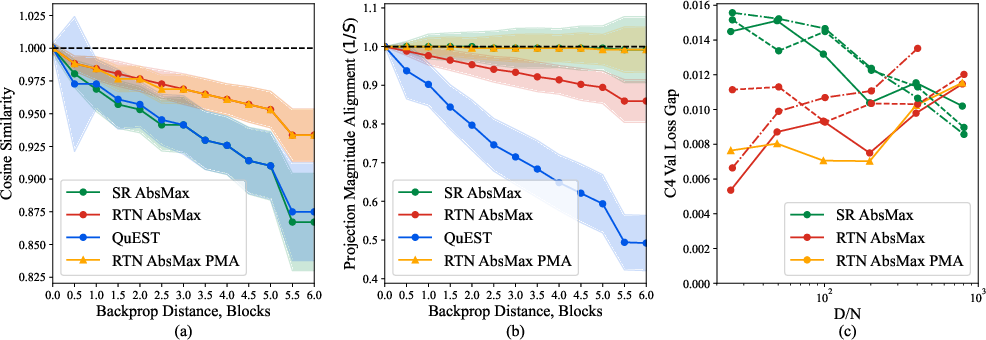
Figure 2: The effect of backward pass quantization on training gradient quality and performance.
Mixed-Precision Trade-Offs
Quartet addresses the inherent trade-offs of mixed-precision training by balancing parameter efficiency with computational gains achieved from low-precision formats. The optimization strategy involves minimizing forward-pass quantization error while ensuring unbiased gradient estimation in the backward pass.
Quartet achieves state-of-the-art (SOTA) results for FP4 precision training, outperforming existing mixed-precision methods in both accuracy and computational speed. The approach shows promise for training billion-scale models while maintaining resource efficiency.
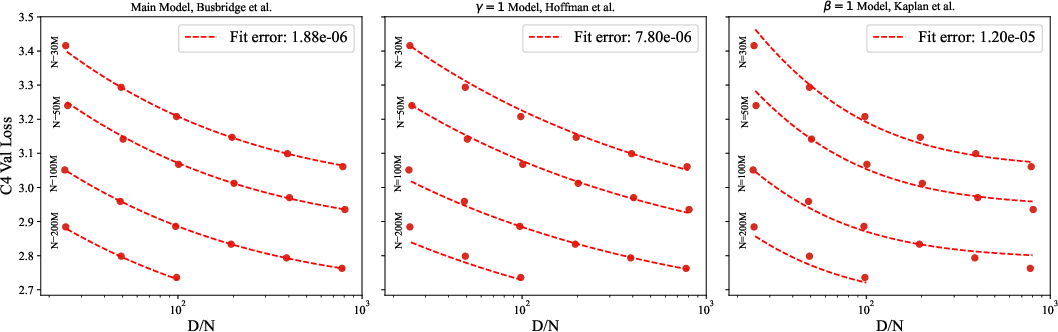
Figure 3: Comparison of various scaling law fits and their associated errors.
Empirical Validation
The empirical analysis validates Quartet’s performance on Llama models, indicating significant advantages in accuracy over competitive methods. The Quartet implementation achieves up to 2x speedup relative to well-optimized FP8 baselines and demonstrates training stability on models with billions of parameters.
Conclusion
Quartet extends the frontier of low-precision training by enabling LLMs to be trained effectively and efficiently in FP4. This contribution aligns with broader industry goals of reducing the computational loads associated with large-scale AI models, making it a viable alternative to traditional precision approaches. Future work can build on this foundation by exploring adaptations for various hardware architectures and extending the framework to accommodate novel quantization formats.