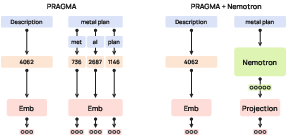
- The paper introduces PRAGMA, a foundation model that encodes multi-source banking event sequences with a novel tokenisation strategy for heterogeneous financial data.
- It leverages a modular, encoder-only Transformer architecture with separate profile state and event encoders to achieve significant improvements in credit scoring, fraud detection, and engagement metrics.
- The model employs parameter-efficient LoRA fine-tuning and rigorous evaluations, demonstrating strong transferability and outperforming task-specific baselines across diverse financial tasks.
PRAGMA: A Foundation Model for Multi-Source Banking Event Sequences
Introduction and Problem Setting
The PRAGMA architecture, introduced in "PRAGMA: Revolut Foundation Model" (2604.08649), constitutes an encoder-style foundation model targeting the heterogeneity and scale of multi-source banking event sequences. Unlike prior approaches that focus on narrow modalities (e.g., text-only financial models or single-source transaction modeling), PRAGMA is designed to encode diverse, irregular, and long-tailed histories of financial and platform events, jointly modeling variable-length event sequences and static user profile states for discriminative financial tasks.
The challenge addressed by PRAGMA arises from the structure of banking data: multi-field, event-centric histories with mixed categorical, numerical, and textual features, significant temporal and source heterogeneity, and regulatory privacy constraints. Standard NLP- or tabular-oriented architectures—such as LLMs processing serialised text, or tabular Transformers assuming flat schemas—perform suboptimally in this setting due to sequence length inflation, loss of field semantics, and inefficiency in modeling irregular temporal patterns.
Data Structure and Tokenisation
PRAGMA models user records as a combination of sequential events and contextual profile state, aggregating all historical interactions up to a domain-specific evaluation point.
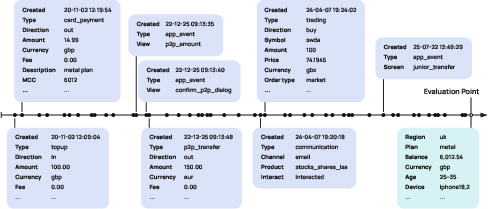
Figure 1: Each user record comprises a timeline of heterogeneous interactions and contextual profile attributes, all sharing a unified key–value–time schema.
Tokenisation in PRAGMA is critical for preserving data semantics and enabling efficient attention. Each record is decomposed into (1) a semantic type (key), (2) an associated value (numerical, categorical, or textual), and (3) a temporal coordinate. Numerical values are discretised into percentile buckets, categorical values are mapped one-to-one, and textual fields are tokenised using a BPE strategy. Time features are encoded as log-seconds to the previous event, further augmented with fixed calendar cycles (hour, day, week).
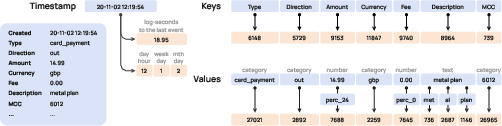
Figure 2: The tokenisation pipeline ensures that semantic types, values, and temporal features are distinctly represented, preventing dilution of categorical and ordinal structure.
This tokenisation scheme yields a disentangled representation space, enabling the model to distinguish among field types and learn over both local and global event contexts.
Architectural Overview and Pre-Training Protocol
PRAGMA's architecture is a modular, encoder-only Transformer, scaling across three parameterizations (10M, 100M, 1B). Its core consists of three main components:
- Profile State Encoder: Encodes static, event-level, and life-long user features with RoPE time encodings.
- Event Encoder: Processes each event independently, embedding field tokens with detailed time and structural encodings.
- History Encoder: Fuses the sequence of USR and EVT tokens, contextualising the entire record in a bidirectional manner.
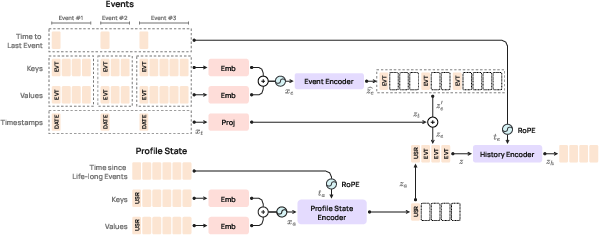
Figure 3: The hierarchical encoding process: profile and event branches feed into a global history encoder.
Pre-training employs a Masked Language Modeling (MLM) objective, incorporating token-level, event-level, and semantic-type masks to reconstruct partially observed sequences. Two downstream adaptation strategies are supported: (i) frozen embedding probes with linear heads, and (ii) LoRA fine-tuning, enabling efficient task adaptation with only 2–4% weight updates.
Evaluation and Main Empirical Results
PRAGMA is benchmarked across an unusually broad array of downstream banking tasks: credit scoring, fraud detection, communication engagement, product recommendation, recurrent transaction detection, and lifetime value estimation. Unlike prior transaction-ledger models that are often task-specific, PRAGMA demonstrates robust transfer performance across all tasks using a single shared backbone.
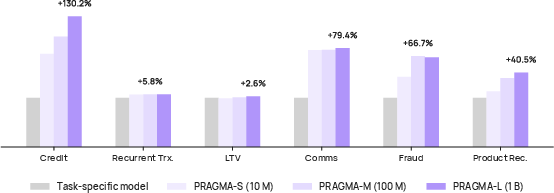
Figure 4: PRAGMA scales from 10M to 1B parameters and outperforms task-specific baselines across domains.
Key empirical highlights include:
- Credit scoring: PR-AUC increased by 130.2% and ROC-AUC by 12.4% over strong internal baselines.
- Communication engagement: PR-AUC improved by 79.4% and ROC-AUC by 20.4%.
- External fraud detection: Precision and recall improved by 16.7% and 64.7%, respectively.
- Product recommendation: Observed a 40.5% gain in mAP.
- Scaling analysis: Larger models (1B) yield significant PR-AUC gains on harder tasks (e.g., +35.2% for credit scoring); small models are already competitive for stable, pattern-rich objectives.
- Parameter-efficient adaptation: LoRA matches or outperforms full scratch-trained models in all settings, with +18.6% PR-AUC uplift in communication engagement relative to scratch.
- Profile state ablation: Adding the profile state encoder provides +31.8% PR-AUC for credit scoring; its importance is task-specific.
Ablations and Architectural Choices
PRAGMA's design enables targeted ablation studies:
Implications and Future Directions
PRAGMA demonstrates that it is possible to construct a universal encoder backbone for multi-source event histories in regulated domains, rendering much of bespoke feature engineering and task-specific modeling obsolete for a large set of discriminative tasks. The model's ability to outperform internal baselines across several financial service benchmarks—while greatly simplifying the modeling stack—is a strong endorsement of the foundation model paradigm in banking. The architecture's modularity (e.g., opt-in text encoders, separate profile/event branches) and efficient adaptation mechanisms (LoRA) further improve operational flexibility and model stewardship.
Practically, the consolidation of multiple risk, engagement, and analytics models into a single backbone has implications for governance, explainability, and regulatory approval pipelines. Theoretically, this work foregrounds the limitations of current foundation models in relational settings: capturing cross-entity relationships (as needed in AML and network fraud) is out of reach for isolated sequence encoders and necessitates explicit graph-relational extensions or cross-user attention mechanisms.
Conclusion
PRAGMA establishes a new baseline for foundation modeling in the financial event-sequence domain. Its key strengths include a principled tokenisation and encoding of heterogeneous data, a scalable encoder backbone with hierarchical contextualisation, and empirical superiority (by substantial margins) over task-specific approaches in key banking use cases. However, its focus on isolated event histories reveals the inherent limitations of current architectures for relational/graph-structured tasks, making relational augmentation a clear research priority. The architectural and empirical insights from PRAGMA are likely to generalize well to other domains characterized by multi-source, irregularly-timed, tabular event records, suggesting ample opportunity for future models operating at the intersection of structured and sequential data.