- The paper demonstrates that nuFormer leverages transformers and self-supervised objectives to model financial transactions and improve predictive accuracy.
- It introduces an innovative joint fusion approach combining transaction embeddings with tabular data to capture deep cross-interactions.
- Experimental results at Nubank reveal that larger models and longer context lengths significantly enhance recommendation performance and risk analysis.
Introduction
The paper "Your Spending Needs Attention: Modeling Financial Habits with Transformers" investigates the application of transformer-based models to transaction data in the financial domain, proposing a novel approach to enhance predictive modeling tasks within financial institutions. By leveraging rich raw data from user transactions, the authors aim to capture detailed behavioral insights that can be used to drive significant performance improvements in recommendation systems, risk prediction, and fraud detection.
Transformer models, particularly those employing self-supervised learning (SSL), have demonstrated remarkable success in various domains such as NLP, vision, and sequential recommendation systems. Traditional approaches in the financial sector have relied heavily on manual engineering of tabular features from transaction data. This paper proposes an alternative method, nuFormer, which aims to streamline this process by automating feature extraction using transformers.
The key challenge in applying transformers to financial transaction data lies in the complexity and scale of the data, which often includes both structured and textual information. Here, the authors address three main limitations of existing methods like CoLES and NPPR: the exclusion of textual data, the use of less effective RNNs for long-range dependencies, and issues arising from the scale of financial data.
The paper introduces a unique transaction modeling approach inspired by the text-is-all-you-need paradigm. Transactions are defined as sequences of embeddings created from numerical, categorical, and text data, including transaction descriptions. By representing transaction attributes as tokens and employing a causal transformer architecture, the model can learn from the sequence to predict future transactions using SSL objectives such as next-token prediction.
The approach uses special tokens to represent key transaction attributes (e.g., amount, date) and applies byte-pair encoding for text components, ensuring efficient embedding handling even with longer transaction histories.
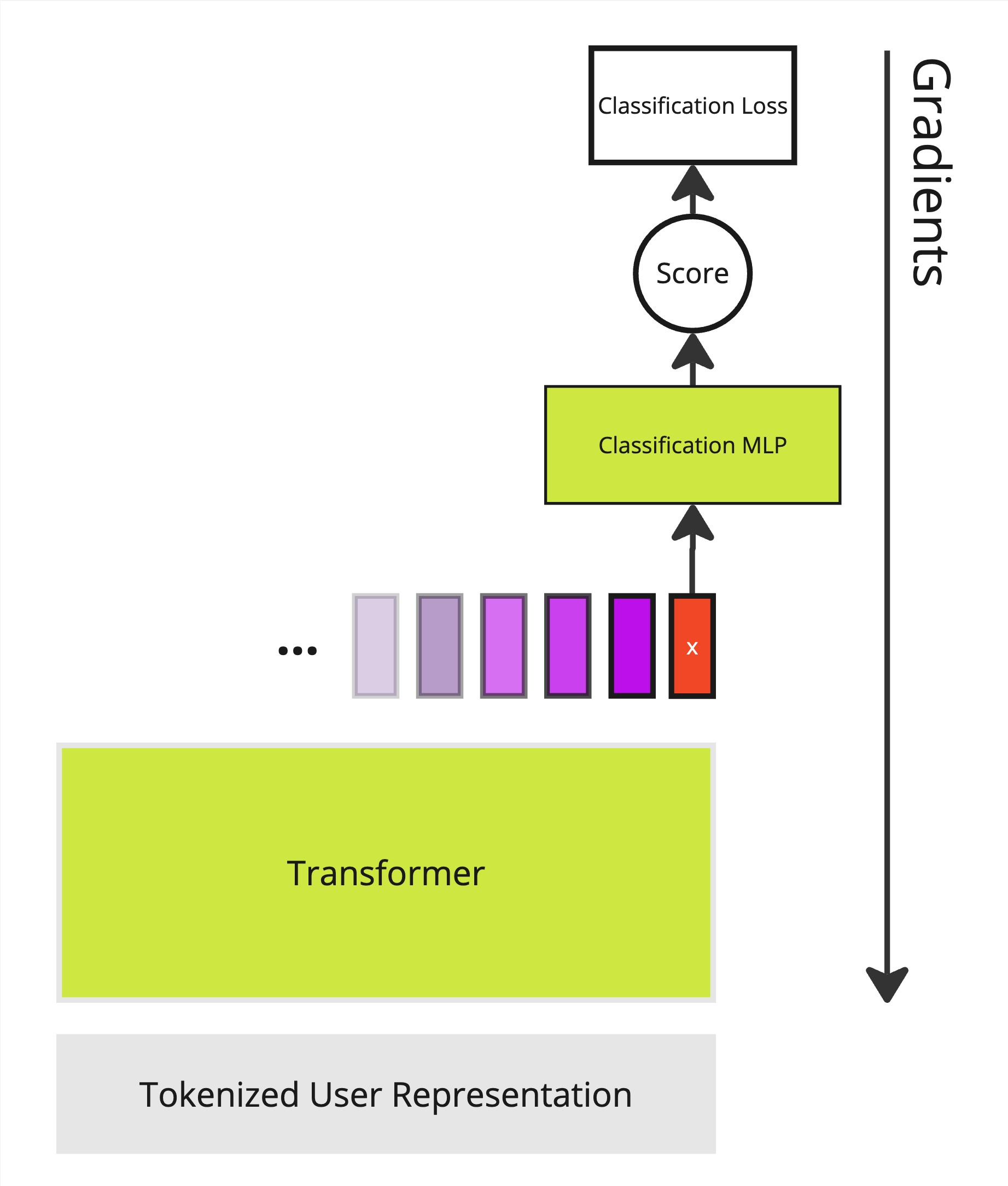
Figure 1: This figure shows how a pre-trained transaction foundation model is augmented for finetuning (green indicates trainable parameters). We add an MLP which produces a score from the final output embedding. Both, the MLP and transformer are optimized to minimize the classification loss.
Joint Fusion with Tabular Features
Building on the foundation model, the authors propose an innovative joint fusion approach, nuFormer, which combines learned embeddings with tabular features in an end-to-end trainable system. Unlike traditional early or late fusion methods that may overlook intricate relationships in data, nuFormer integrates both categorical and numerical feature embeddings in a DCNv2 framework, which allows modeling of deep cross-interactions and blending of transaction embeddings seamlessly.
Implementing techniques like numerical feature embeddings and regularization strategies improved the performance parity between DNN and traditional tabular models like LightGBM. This joint fusion framework was shown to outperform baseline models consistently across different configurations.
Experimental Evaluation
The authors conducted extensive experiments on a real-world recommendation problem at Nubank, using data consisting of multiple transaction sources. They investigated the effects of varying model parameters such as size, context length, and the volume of training data. A consistent trend was observed: larger models with longer context lengths and more training data showed pronounced improvements in performance.
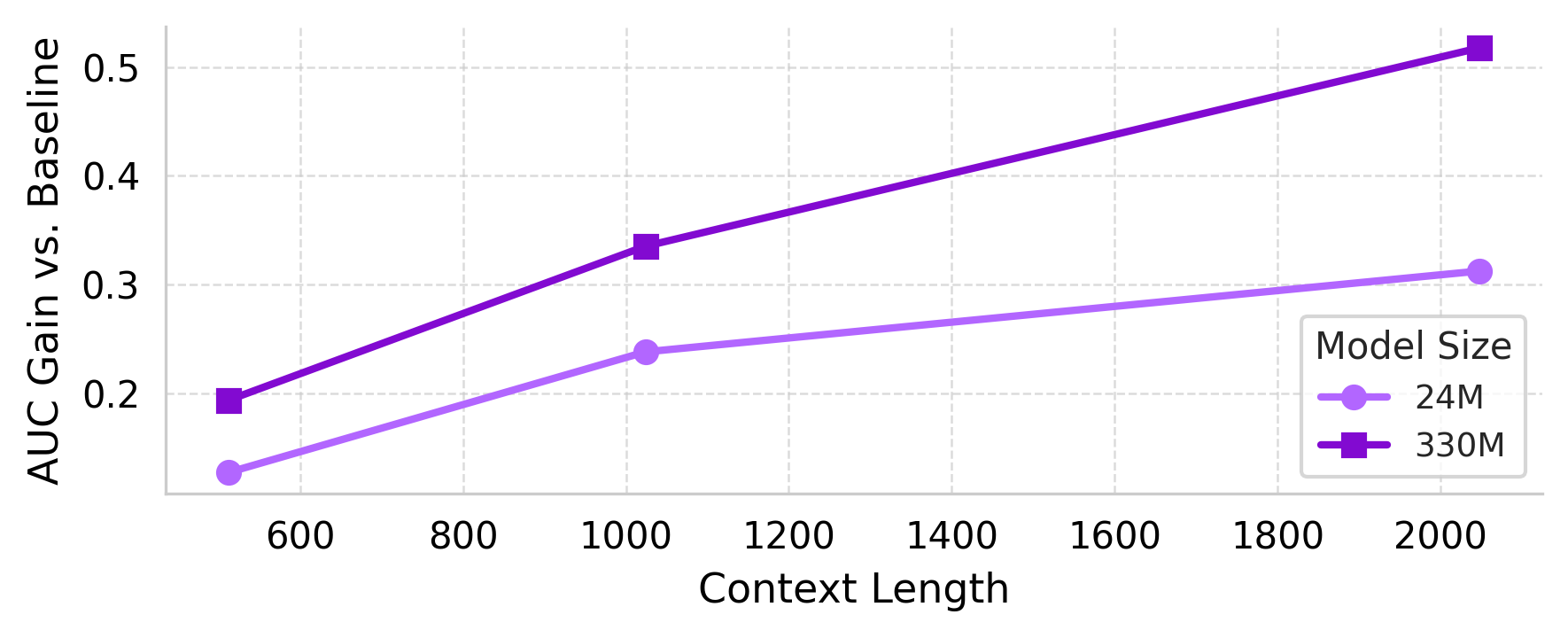
Figure 2: nuFormer test AUC for different context lengths (512, 1024, 2048) with 24M and 330M models.
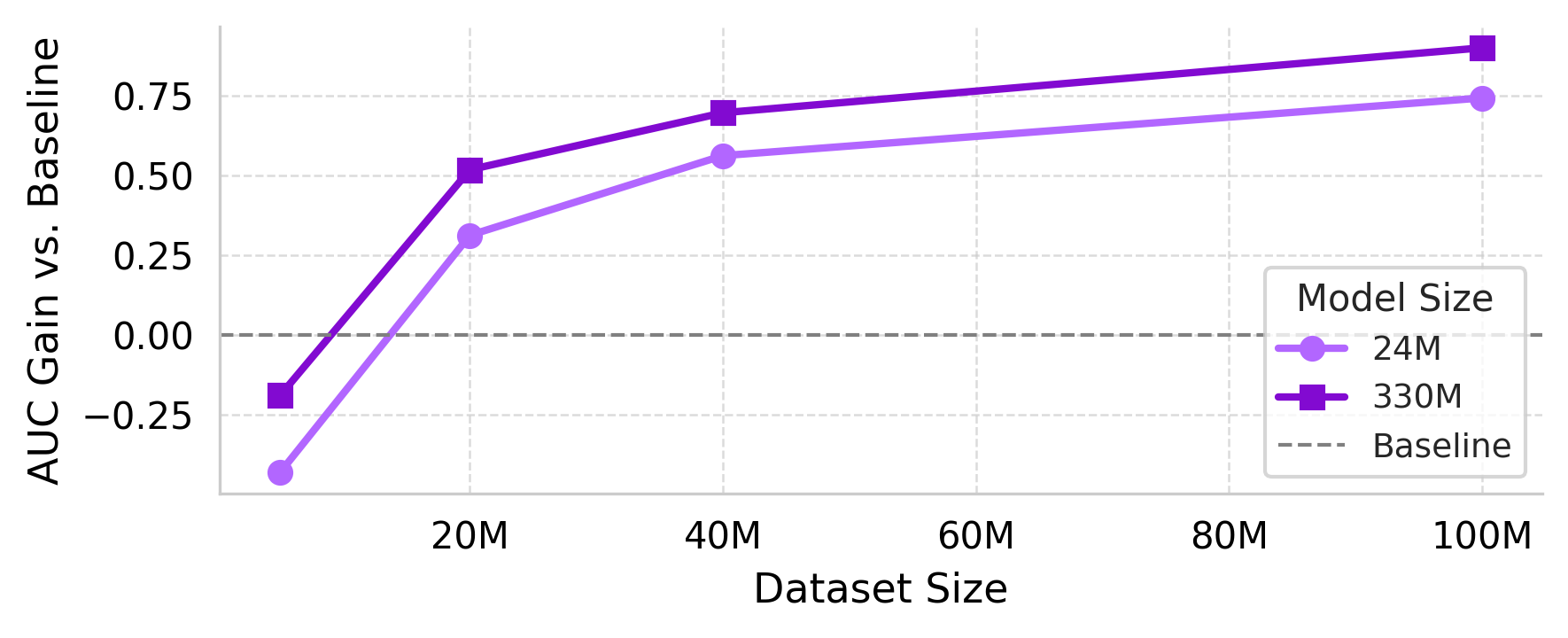
Figure 3: nuFormer test AUC for different amounts of training data (5M, 20M, 40M, 100M) with 24M and 330M models.
The practical implications of these findings were validated through deployment in Nubank's recommendation systems, resulting in substantial improvements in terms of user engagement and reduced churn.
Conclusion
The integration of transformer-based models in financial data processing offers a promising pathway to enhance predictive tasks across the industry. By circumventing traditional feature engineering and exploiting SSL techniques, nuFormer lays the groundwork for more effective utilization of large-scale transaction data, unlocking new potential in understanding customer behavior.
Future developments could further explore scalability and generalization of such models across other domains within fintech, establishing robust foundation models capable of addressing diverse business needs.
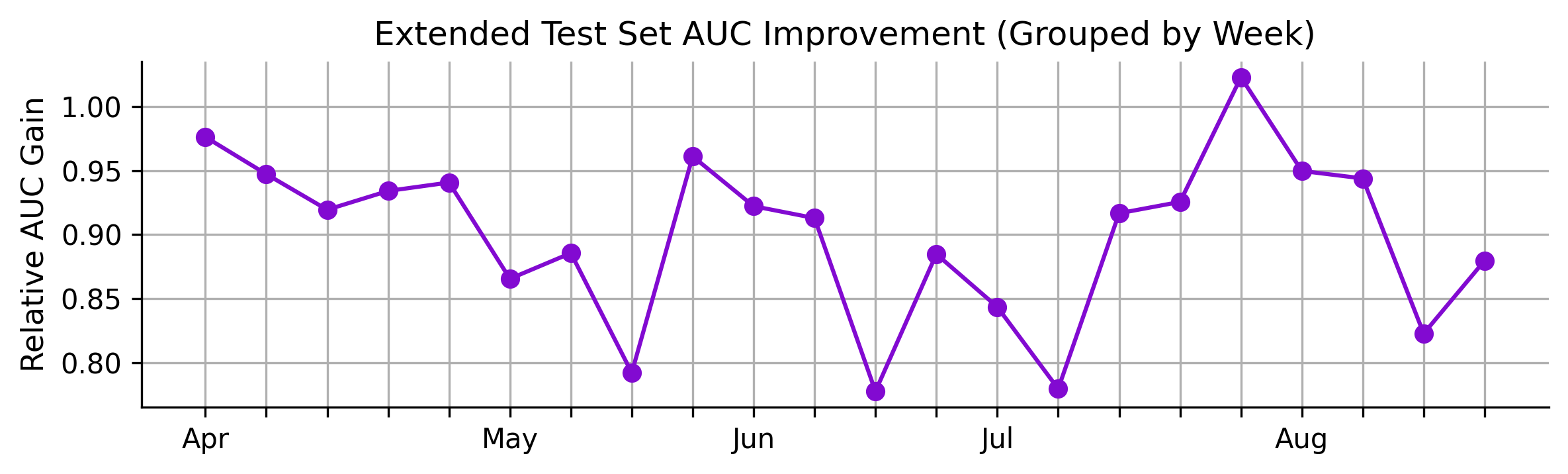
Figure 4: Extended test set (out-of-time) stability analysis. Compares nuFormer and the baseline.

