TradeFM: A Generative Foundation Model for Trade-flow and Market Microstructure
Abstract: Foundation models have transformed domains from language to genomics by learning general-purpose representations from large-scale, heterogeneous data. We introduce TradeFM, a 524M-parameter generative Transformer that brings this paradigm to market microstructure, learning directly from billions of trade events across >9K equities. To enable cross-asset generalization, we develop scale-invariant features and a universal tokenization scheme that map the heterogeneous, multi-modal event stream of order flow into a unified discrete sequence -- eliminating asset-specific calibration. Integrated with a deterministic market simulator, TradeFM-generated rollouts reproduce key stylized facts of financial returns, including heavy tails, volatility clustering, and absence of return autocorrelation. Quantitatively, TradeFM achieves 2-3x lower distributional error than Compound Hawkes baselines and generalizes zero-shot to geographically out-of-distribution APAC markets with moderate perplexity degradation. Together, these results suggest that scale-invariant trade representations capture transferable structure in market microstructure, opening a path toward synthetic data generation, stress testing, and learning-based trading agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Think of the stock market like a super busy digital marketplace where thousands of people and computers are constantly placing buy and sell offers. This paper introduces TradeFM, a large AI model that learns the “language” of these market events so it can generate realistic new market activity. The goal is to understand and simulate how trades happen minute by minute without hand‑coding lots of financial rules.
What questions the researchers asked
They set out to answer a few simple questions:
- Can one big model learn general rules of how trading works from billions of real trades across thousands of different stocks?
- Can it do this even if it only sees what a normal trader sees (not the full hidden order book)?
- Can it create realistic “fake” market data that follows well‑known patterns real markets show?
- Will it still work on different markets (like in Asia) that it never saw during training?
How they did it (in simple terms)
They combined three main ideas:
1) Turning raw trades into a common, comparable form
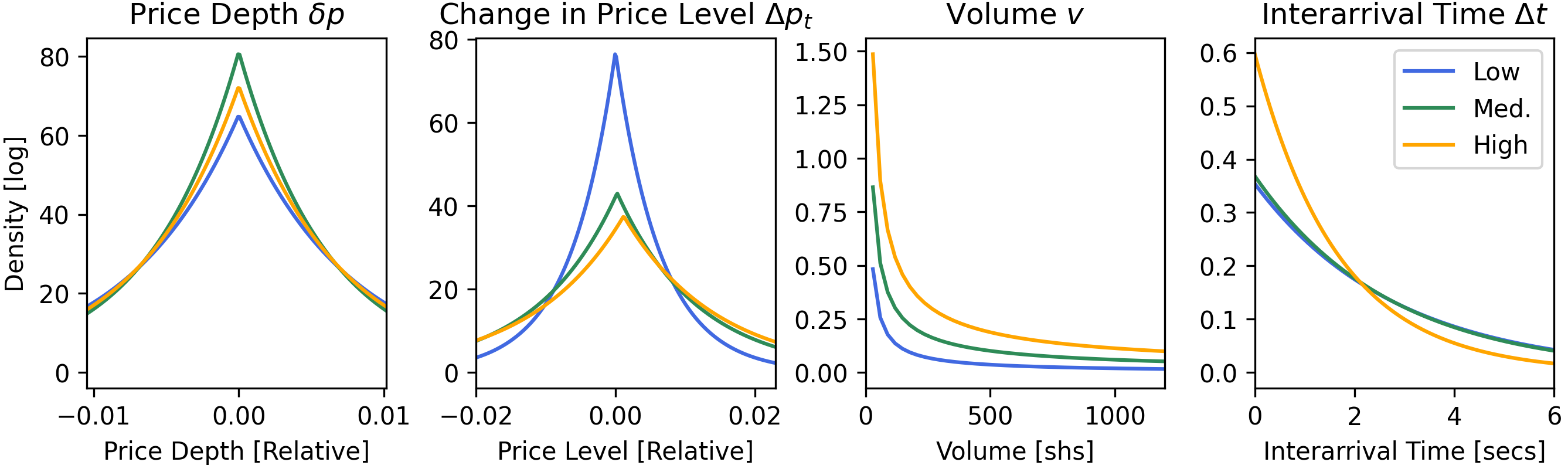
Different stocks look very different: a $5 stock and a$500 stock have prices, volumes, and speeds that aren’t directly comparable. The authors fix this by using “scale‑invariant” features—basically measuring in percentages and relative changes instead of raw dollars or shares. For example:
- Price moves are measured as percentage changes, not pennies.
- Trade sizes are compressed with a log scale so giant and tiny trades fit on the same scale.
- Time between trades is kept explicitly so the model can learn the rhythm of trading.
They also estimate a fair “middle” price from recent trades using a smarter average that favors bigger and more recent trades. You can think of it like giving more weight to the most important and freshest information.
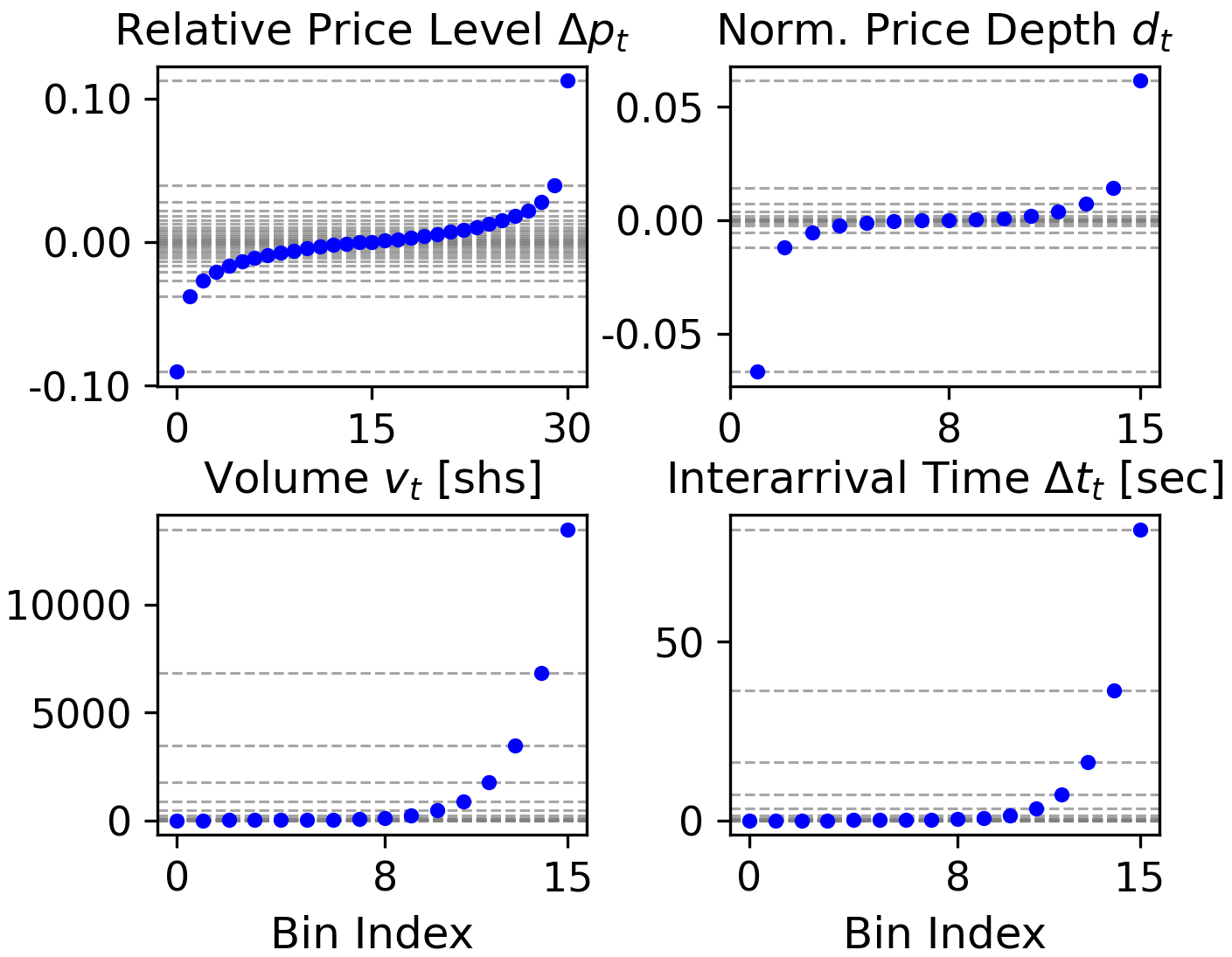
2) Turning each market event into a compact “code”
Each event (like “a buy order of 750 shares placed 8 seconds after the last trade, at 0.01% above the mid‑price”) has several pieces. They discretize each piece into bins (like putting ages into age groups), then pack those bins together into a single token (a code). This lets a text‑style AI model read the market as a stream of tokens, the way it reads words in a sentence.
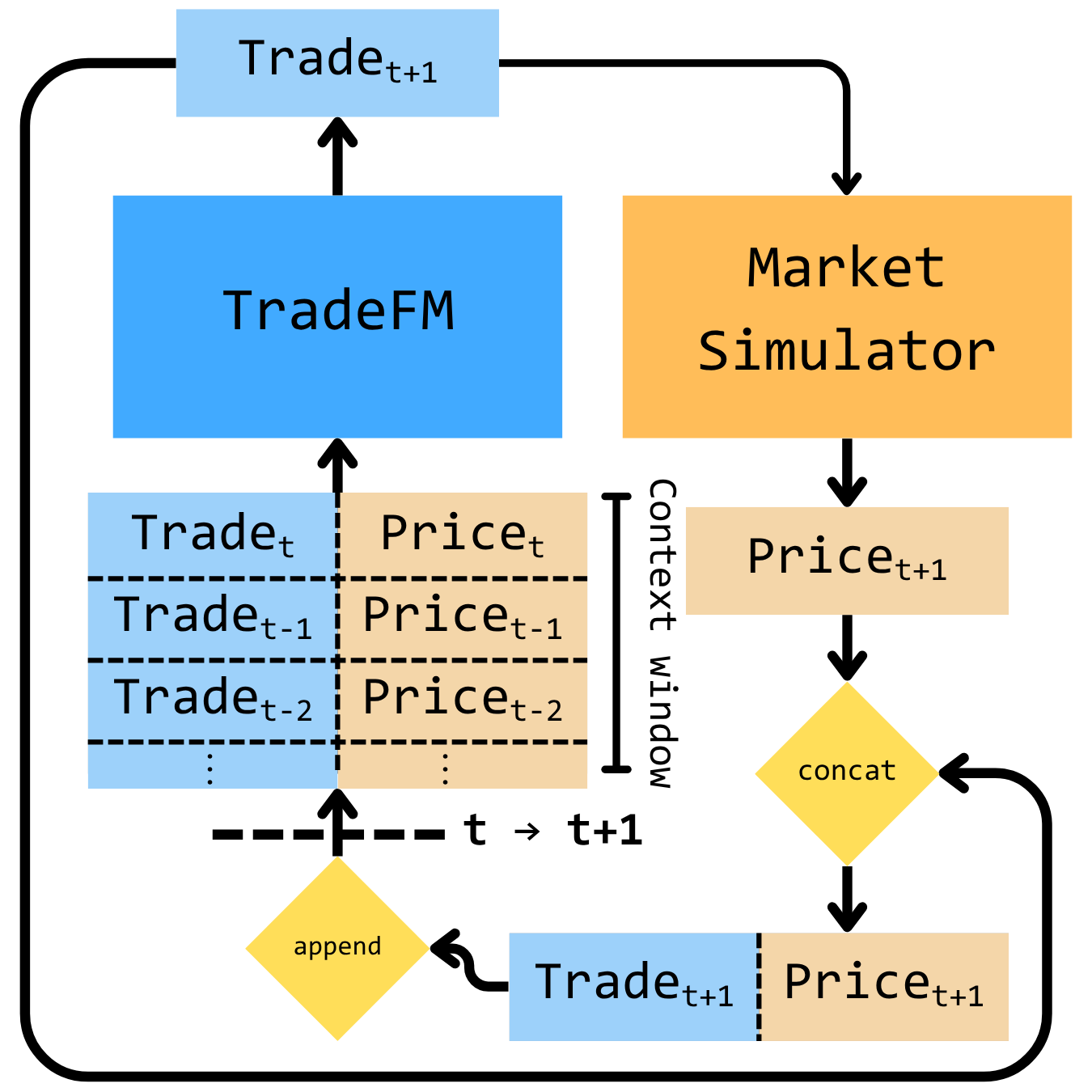
3) Training a large sequence model and testing it in a looped simulator
They use a Transformer (the same kind of model behind chatbots) with about 524 million parameters. It learns to predict the next event token from previous ones, like predicting the next word in a sentence. To check realism, they plug the model into a simple, rule‑based market “video game” (a simulator). The model generates an event, the simulator updates the market state, that new state feeds back into the model, and so on. This closed loop shows whether the model’s own actions lead to believable market behavior over time.
What they found and why it matters
The results show the model isn’t just memorizing; it’s learning the deeper patterns of trading.
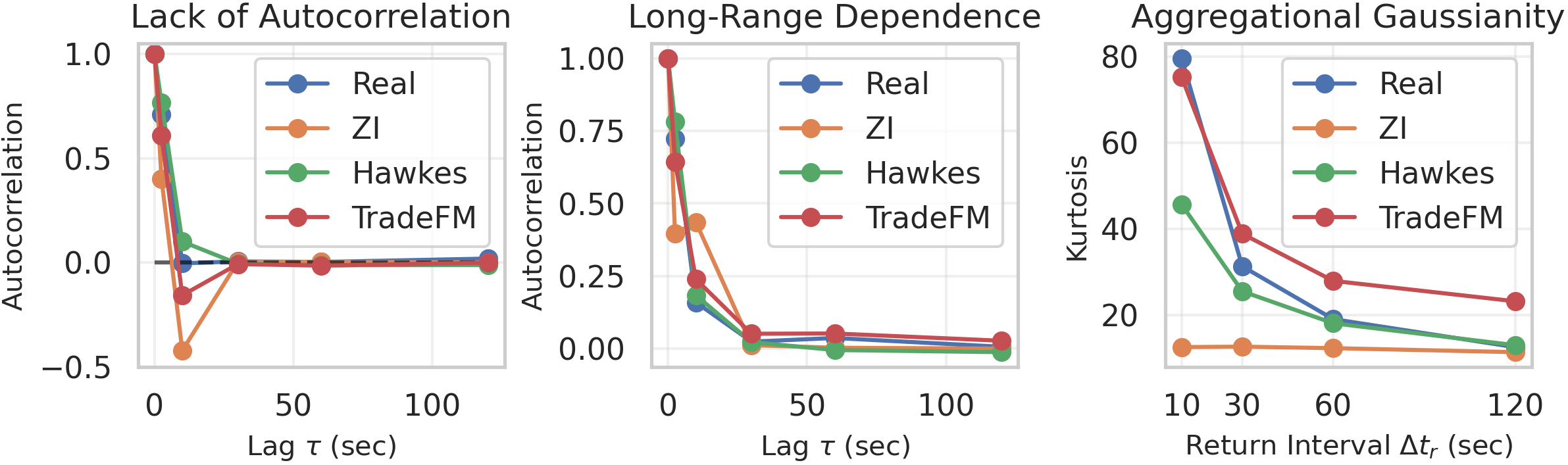
- It recreates famous, real‑world market patterns called “stylized facts.” These include:
- Heavy tails: Big price moves happen more often than a bell curve would suggest.
- Volatility clustering: Quiet times and hectic times come in bunches.
- Little to no simple predictability of the next price change: You can’t easily guess the next direction from the last one.
- It beats strong traditional models: Compared to a popular statistical model (a Compound Hawkes process), TradeFM makes market distributions that are 2–3 times closer to the real thing by standard error metrics.
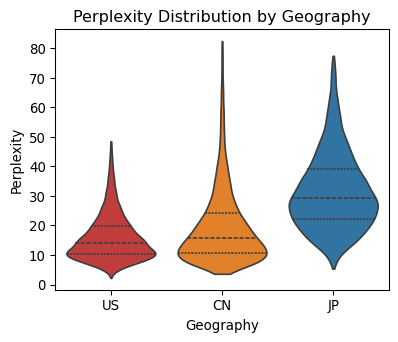
- It generalizes to new places: Even though it was trained only on US stocks, it still performs reasonably well on stocks from Japan and China—very different markets—without retraining. That suggests the features and the “market grammar” it learned are universal.
- It works with partial information: It only needs the stream of trade events (like what most participants see), not the complete hidden details of the order book. That makes it more practical and fair to compare to real users’ view.
Why this could be important
If an AI can reliably simulate realistic markets, several useful things become possible:
- Safer experimentation: You can stress test “what if?” scenarios (like sudden spikes in trading) without risking real money.
- Synthetic data: You can generate privacy‑preserving, realistic data for research on illiquid or sensitive assets.
- Smarter training for trading agents: Reinforcement learning agents can practice in a believable environment before going live.
In short, TradeFM shows that treating market events like a language—and using smart, scale‑free features—lets a single model learn how many different stocks and markets behave. That opens the door to better simulations, better testing tools, and more reliable learning‑based trading systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete, action-oriented list of what remains uncertain, missing, or unexplored in the paper.
- Simulator realism and coverage: The deterministic LOB simulator omits critical microstructure details (multi-venue fragmentation, latency/queue dynamics, hidden/iceberg liquidity, partial fills, pegged/IOC/FOK orders, maker–taker fees/rebates, halts/auctions, and exchange-specific rules). How does TradeFM behave when these features are introduced, and which omissions most materially affect closed-loop validity?
- Spread modeling weakness: TradeFM underperforms Compound Hawkes on spread distributions. What hybrid designs (e.g., explicit spread process + learned flow) best close this gap without sacrificing other fidelity metrics?
- Market impact and square-root law: The paper claims the setup enables study of price impact but provides no quantitative validation against empirical impact curves. Does TradeFM reproduce transient/permanent impact, concavity, and decay consistent with the square-root law across liquidity tiers?
- Long-horizon dynamics: Rollouts are limited to ~1k events (minutes to a few hours depending on liquidity). Can the model reproduce intraday seasonality (U-shaped volume/volatility), end-of-day dynamics, and multi-day memory when rolled out for full sessions or longer?
- Time-of-day and calendar effects: There is no explicit conditioning on time-of-day, day-of-week, month-end, or event times. How much does adding such conditioning improve seasonality, opening/closing auction behavior, and overnight-to-intraday regime alignment?
- Tokenization rigidity and drift: Fixed bin edges (calibrated on 30 days of US data) may misrepresent later regimes and other geographies. What is the sensitivity of fidelity and OOD performance to bin edge selection, re-calibration frequency, and adaptive/distribution-aware tokenizers?
- Tail risk truncation: Clipping at the 1st/99th percentiles with “out-of-range” bins may under-represent extreme events. How does this choice affect tail modeling (e.g., crash risk, gap moves), and can extreme-value-aware discretizations improve rare event fidelity?
- Composite token entanglement: Packing multiple features into a single token constrains scalability and interpretability. Would factorized heads (autoregressive over features) or product-of-experts likelihoods yield better sample efficiency, control, and extendibility to more features/bins?
- Partial observability limits: Learning from event streams without full LOB may systematically miss queue state and hidden depth. What is the marginal value of limited L2/L3 cues (top-k levels, queue lengths) and can learned latent state mitigate missing-book information?
- Mid-price estimation validity: EW-VWAP is used without quantitative benchmarking against ground-truth mid from LOB feeds. How accurate is EW-VWAP across liquidity regimes and event types, and how sensitive are downstream results to halflife/alpha selection?
- Data representativeness and reproducibility: The dataset is proprietary and US-equity centric. Can results be replicated on public feeds (e.g., LOBSTER/TAQ), and do conclusions hold across futures/FX/crypto/options with different microstructure and tick regimes?
- Geographic transfer beyond perplexity: OOD evaluation for APAC uses perplexity only; no closed-loop rollouts under APAC-specific mechanics (e.g., Itayose batch auctions, price limits). How does the model perform in simulation when auction and limit rules are faithfully implemented?
- Regime and policy invariance: The model is observational; robustness under policy changes (tick-size alterations, fee changes, circuit breakers, price limits) is untested. Does TradeFM retain structural stability under counterfactual microstructure policies?
- Baseline breadth: Comparisons omit modern neural point processes, diffusion models for event streams, normalizing-flow–enhanced Hawkes, or LOB-conditioned transformers with masked observability. How does TradeFM fare against these stronger generative baselines under matched inputs?
- Scaling laws and size ablations: The 524M size is justified via Chinchilla heuristics but no model/data scaling ablation is provided. What are returns to scale in parameters, context length, and training tokens, and is there a compute-optimal frontier for this domain?
- Decoding sensitivity and exposure bias: Rollouts use multinomial sampling with a repetition penalty; temperature, top-k/p, and scheduled sampling are not explored. How sensitive are stylized facts and order-flow metrics to decoding choices and mitigation of exposure bias?
- Conditioning space insufficiency: Conditioning is limited to liquidity tier, market vs participant flag, and price level vs open. Would adding sector, exchange/venue, tick size, volatility regime, and time-of-day tokens improve controllability and generalization?
- Participant-level realism: Participant sequences are aggregated with a coarse binary indicator. Do generated participant-level flows reproduce empirically observed trade-sign autocorrelation, order-splitting patterns, parent–child execution dynamics, and cancellation/modify ratios?
- Cross-asset structure: The model is single-asset per sequence. Can it learn cross-impact and lead–lag across correlated instruments (e.g., ETF–constituent, futures–cash) via multi-instrument conditioning or joint generation?
- Robustness over extreme regimes: Tests span Feb 2024–Sep 2025 with “heightened volatility,” but there is no evaluation on crisis-style extremes (halts, flash crashes). How does fidelity degrade under severe stress, and can counterfactual stress tests be validated against historical crises?
- Privacy and leakage: Synthetic data is proposed for privacy-preserving use, but membership inference, attribute inference, and memorization risks are unassessed. What DP or red-teaming protocols are needed to certify privacy?
- Fair attribution between model and simulator: Closed-loop results conflate model and simulator errors; only partial disentanglement is attempted. Can off-policy evaluation or simulator randomization isolate model fidelity from simulator artifacts?
- Microstructure metrics breadth: Evaluation focuses on returns, interarrival times, imbalance, and volumes; several key diagnostics are missing (trade-sign autocorrelation, order-flow long memory, resiliency, price response functions, Epps effect). Do generated flows match these broader metrics?
- Auction/open/close handling: Opening and closing auctions are not explicitly modeled. How does explicit auction conditioning and an auction-capable simulator affect realism at session boundaries?
- Generalization to other asset classes: Applicability to options (discrete strikes/maturities), futures (different tick/expiry), FX/crypto (24/7, fragmented venues) remains untested. What adaptations to features, tokenization, and simulators are required?
- Training stability and optimization: Details on curriculum, learning-rate schedules, and regularizers vis-à-vis non-stationary distributions are limited. Do curriculum learning or domain-balanced sampling improve OOD robustness?
- Adaptive or continuous-time architectures: The model encodes time via binned interarrival tokens; continuous-time attention, neural ODEs, or neural Hawkes might better capture temporal dynamics. Do such architectures reduce discretization error and improve clustering of volatility?
- Liquidity bin granularity: Using three ADV-based bins may be too coarse. What is the effect of finer-grained or continuous liquidity embeddings on generalization across assets and periods?
- Action taxonomy completeness: The action space appears limited to add/cancel; explicit marketable orders, replaces/modifies, and venue-routing decisions are not modeled. How much fidelity is gained by expanding the action taxonomy and allowing partial/iceberg fills?
Practical Applications
Immediate Applications
The following applications leverage TradeFM’s current capabilities (scale-invariant features, universal tokenization, conditional generation, and the closed-loop deterministic simulator) and can be deployed with modest integration effort in finance, academia, and software engineering contexts.
- Bold Synthetic market data generation for equities: Finance — Generate realistic, high-frequency order-flow and price dynamics that reproduce stylized facts for backtesting, feature discovery, and model prototyping without accessing sensitive tick data. Workflows: condition TradeFM on recent context, sample rollouts with configurable sampling parameters, and evaluate via K–S/Wasserstein metrics. — Assumptions/Dependencies: Quality of synthetic data depends on simulator fidelity and conditioning; coverage strongest for US equities; data governance required for any mixing of real/synthetic streams.
- Bold Stress testing and scenario analysis of execution strategies: Finance (risk, execution) — Use rollouts to create controlled episodes of volatility clustering, heavy tails, and liquidity shifts, then measure slippage, market impact, and drawdowns under alternative slicing schedules (e.g., POV, TWAP, VWAP). Tools: “TradeFM-Sim” workflow with indicator-conditioned generation (liquidity, market vs participant). — Assumptions/Dependencies: Impact estimates rely on simulator rules (price-time priority, spread emergence); extreme regimes may need scenario-specific conditioning or sampler tuning.
- Bold Short-horizon market impact estimation and TCA enhancement: Finance (buy-side/sell-side) — Estimate distributions of costs for candidate execution schedules by injecting strategy orders into the closed-loop and comparing outcomes across liquidity tiers. Produce enriched TCA reports with microstructure-aware context (interarrival times, book imbalance). — Assumptions/Dependencies: Partial observability (no full LOB input) can limit spread fidelity; hybrid modules (e.g., Hawkes for spread) may be required for certain instruments or venues.
- Bold Participant-level behavior modeling for ABM: Finance (agent-based modeling) — Generate participant-level streams by toggling the I_MP indicator to seed agent heterogeneity; run multi-agent simulations to study emergent effects and price impact. — Assumptions/Dependencies: Requires labeled participant sequences for best conditioning; simulator-agent interfaces and validation protocols need standardization.
- Bold Cross-geography feasibility studies: Finance (exchanges/market structure teams) — Evaluate strategy portability using zero-shot generalization to APAC with moderate perplexity degradation; prototype parameter changes for local regimes (e.g., price limits, auction mechanisms). — Assumptions/Dependencies: Adaptation of contextual features to local rules (e.g., Itayose batches, daily limits); additional calibration for spread norms and halts.
- Bold Data augmentation for supervised microstructure models: Finance/Software — Augment scarce training data for classifiers/regressors (e.g., imbalance prediction, anomaly detection) with synthetic sequences that retain heavy tails and clustering properties. — Assumptions/Dependencies: Careful balance to prevent synthetic-overfitting; validation via distributional distances; governance for mixing synthetic with labeled real events.
- Bold Drift monitoring and anomaly detection via perplexity dashboards: Finance/Software — Track model perplexity over time and across venues to detect regime shifts, data pipeline issues, or structural microstructure changes. Integrate with MLOps telemetry and incident response. — Assumptions/Dependencies: Stable tokenizer and conditioning features; thresholds tuned to asset/liquidity tier; complementary statistical monitors for confirmation.
- Bold Education and training in market microstructure: Academia/Education — Interactive labs that visualize LOB dynamics, stylized facts reproduction, and differences between zero-intelligence, Hawkes, and TradeFM rollouts; curricular modules for graduate finance/ML courses. — Assumptions/Dependencies: Simplified UI and curated datasets; clear learning outcomes; sandboxed compute.
- Bold Synthetic traces for systems testing: Software/Data engineering — Deterministically generate order-flow sequences to load-test ingestion, serialization, and real-time analytics pipelines; exercise edge cases via controllable generation. — Assumptions/Dependencies: Stable random seeds, reproducible sampling configurations; alignment of event schemas with downstream systems.
Long-Term Applications
These applications are enabled by TradeFM’s core innovations but require further research, scaling, regulatory alignment, or engineering to realize.
- Bold RL-driven algorithmic trading agents trained in closed loop: Finance — Train reinforcement learning policies for execution/market making within TradeFM-Sim to learn microstructure-aware tactics; transfer via domain adaptation or online learning. — Assumptions/Dependencies: Simulator-to-market gap must be quantified; model risk governance; safety constraints and guardrails; latency-sensitive inference.
- Bold Market design and regulatory impact analysis: Policy/Exchanges — Simulate counterfactual microstructure rules (tick-size changes, price limits, batch auctions) and measure effects on spreads, volatility clustering, heavy tails, and liquidity resilience. — Assumptions/Dependencies: Regulator/exchange collaboration; validated simulators and interpretability; credible calibration to local venues.
- Bold Privacy-preserving synthetic tick data products: Finance/Data vendors — Release high-fidelity synthetic datasets for research and model development, especially for illiquid or restricted assets, with differential privacy or membership-inference safeguards. — Assumptions/Dependencies: DP training/fine-tuning, formal privacy auditing, legal review; performance-privacy tradeoffs.
- Bold Cross-asset and multi-venue expansion: Finance — Extend the scale-invariant representation and universal tokenization to futures, options, FX, and crypto; enrich with venue-specific features (e.g., greeks, auction events). — Assumptions/Dependencies: New data pipelines and feature design; careful normalization across heterogeneous instruments; revalidation of stylized facts per asset class.
- Bold Anomaly and market abuse detection via rare-event synthesis: Finance/Compliance — Generate labeled synthetic patterns (spoofing, layering, momentum ignition) to train detection models robust to class imbalance; run controlled ABM scenarios to study systemic risk. — Assumptions/Dependencies: Access to labeled cases, pattern templates, and ethics oversight; simulator fidelity for manipulative behaviors; false-positive/negative cost analysis.
- Bold Hybrid generative–stochastic market simulators: Academia/Finance — Combine TradeFM order-flow generation with explicit stochastic modules (e.g., Hawkes for spread formation) and calibrated ABM agents to improve realism and controllability. — Assumptions/Dependencies: Integration of heterogeneous models; calibration protocols; standardized benchmarks and acceptance tests.
- Bold Real-time forecasting and decision support: Finance — Use next-event probabilities and conditional features to flag microstructure regime shifts, rising impact risk, or liquidity fragility; guide dynamic throttling or schedule changes. — Assumptions/Dependencies: Streaming feature engineering, low-latency inference (model distillation/quantization), robust alerting and human-in-the-loop workflows.
- Bold Microstructure sandbox SaaS: Software/Finance — Offer APIs for generation, simulation, and evaluation (distributional metrics, stylized facts, perplexity) to buy-side/sell-side teams and exchanges; support scenario DSLs and reproducible notebooks. — Assumptions/Dependencies: Secure multi-tenant cloud, cost controls for GPU inference, licensing for data and models, MLOps observability.
- Bold Academic benchmarks and curriculum standardization: Academia — Establish public benchmarks for generative microstructure models (metrics, datasets, simulators) and standardized course materials to accelerate reproducible research. — Assumptions/Dependencies: Data-sharing agreements, community governance, maintainers and funding for open-source toolchains.
- Bold Household/retail investor education apps: Daily life/Education — Simplified simulations illustrating liquidity, spreads, and execution costs to improve investor understanding of intraday risk and order placement choices. — Assumptions/Dependencies: Strong disclaimers (no investment advice), simplified models tailored for education, UX that avoids misinterpretation.
Cross-cutting assumptions and dependencies
- Data coverage and quality: Robust tick-level data and accurate EW-VWAP mid-price estimation; recalibration of tokenizer and bins when regimes shift.
- Simulator fidelity: Deterministic LOB rules capture many but not all microstructure effects; hybridization may improve spread/impact realism.
- Generalization scope: Strongest evidence in US equities; APAC transfer is promising but still shows moderate degradation; new markets require feature and tokenization audits.
- Compute and latency: 524M parameters are tractable but may need distillation/quantization for real-time use; reproducible MLOps practices are essential.
- Governance and compliance: Model risk management, privacy, and regulatory alignment are prerequisites for production deployment in financial settings.
Glossary
- ADV (Average Daily Volume): A measure of typical trading activity used to categorize an asset’s liquidity. "based on its Average Daily Volume (ADV)."
- Aggregational Gaussianity: The tendency for return distributions to become more normal as the aggregation horizon increases. "heavy tails and aggregational Gaussianity."
- Agent-Based Models (ABMs): Simulation frameworks that model markets via the behaviors of individual agents to study emergent dynamics. "Agent-based models (ABMs) simulate market dynamics by defining the behavior of individual participants and observing the emergent properties of the system"
- APAC markets: Asia-Pacific equity markets used for out-of-distribution evaluation and transfer. "generalizes zero-shot to geographically out-of-distribution APAC markets with moderate perplexity degradation."
- Autocorrelation: The correlation of a time series with its lagged values; in efficient markets, returns exhibit little autocorrelation. "Lack of Autocorrelation in Returns: Consistent with efficient markets, return autocorrelation is insignificant beyond very short lags."
- Autoregressive sequence modeling: A generative setup where the next event is modeled conditional on past events. "a generative, autoregressive sequence modeling problem."
- Basis points (bps): A unit equal to 0.01% used to express small price changes or spreads. "basis points (bps; 0.01\% of the price)."
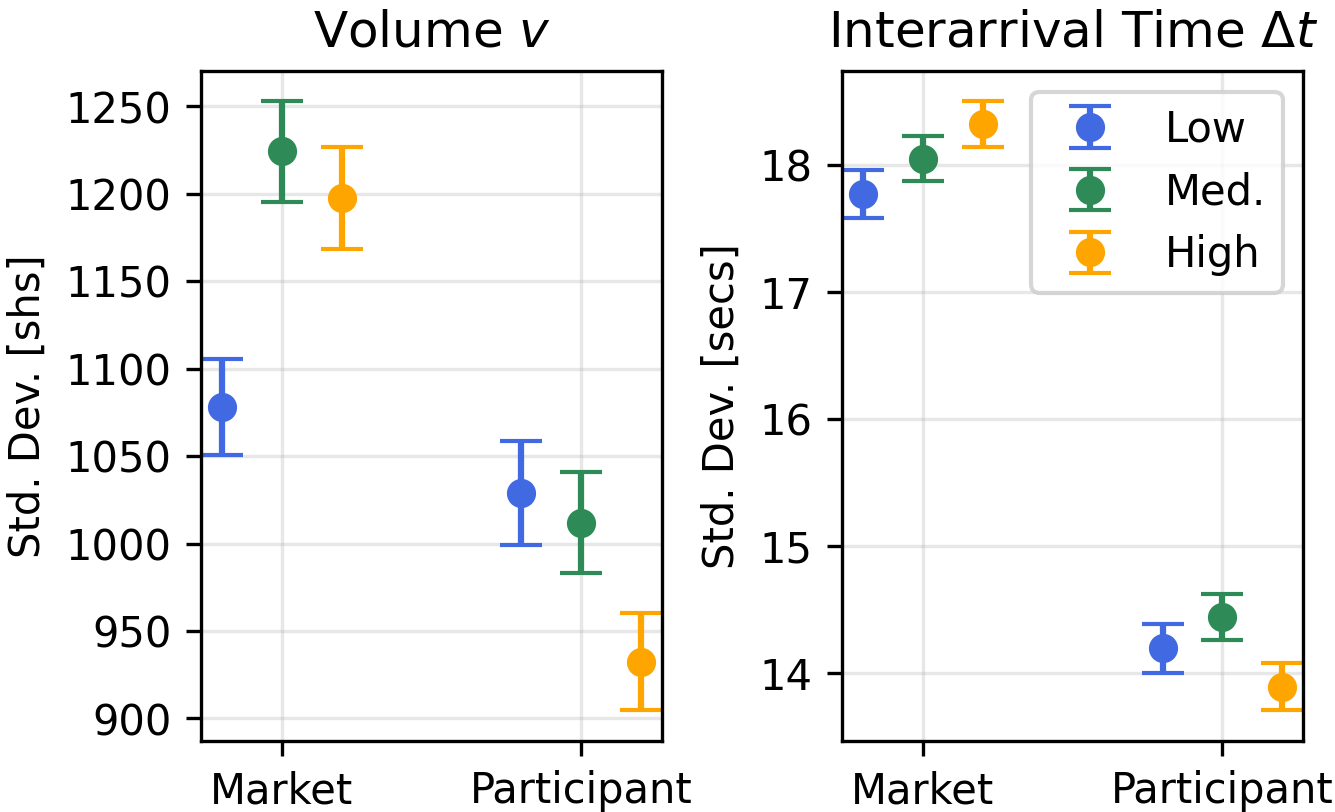
- Bid-Ask Spreads: The difference between the best available sell (ask) and buy (bid) prices. "including Order Volume, Interarrival Times, Bid-Ask Spreads, and Order Book Imbalance."
- Compound Hawkes processes: Self-exciting point-process models augmented with distributions for volumes and depths. "Compound Hawkes processes, which combine Hawkes processes to model interarrival times with other fitted empirical distributions to model additional features like volumes and price depths"
- Decoder-only Transformer: A Transformer architecture that predicts the next token using only a decoder stack. "TradeFM is a decoder-only Transformer, trained from scratch"
- Deterministic market simulator: A rule-based exchange emulator without randomness used for closed-loop evaluation. "Integrated with a deterministic market simulator"
- Distributional error: A measure of discrepancy between generated and real data distributions. "achieves 2--3 lower distributional error than Compound Hawkes baselines"
- Equal-Frequency Binning: Discretization that assigns bins by quantiles to balance token frequency. "we employ Equal-Frequency Binning (quantile-based)."
- Equal-Width Binning: Discretization that uses uniform bin widths (often applied after log-transform). "we use Equal-Width Binning."
- Event stream: The sequential record of market events (orders, trades, cancellations). "event stream of order flow"
- Exponentially-Weighted VWAP (EW-VWAP): A time- and volume-weighted mid-price estimator using exponential smoothing. "we introduce Exponentially-Weighted VWAP (EW-VWAP), a time-aware estimator that jointly accounts for trade volume and recency"
- Grouped-Query Attention (GQA): An attention variant that groups queries to improve efficiency. "grouped-query-attention (GQA)"
- Hawkes processes: Self-exciting point processes where events increase the likelihood of future events. "such as Hawkes processes, to capture the self-exciting nature of order flow"
- Heavy tails: Return distributions with more extreme events than a Gaussian predicts. "including heavy tails"
- Hidden Markov Models: Probabilistic models with latent states used to classify sequential trade activity. "Hidden Markov Models have been applied to classify sequences of trade activity"
- Interarrival Time: The elapsed time between two consecutive market events. "Interarrival Time (): Wall clock time since the previous event: , in seconds."
- Itayose batch auction mechanism: Japan’s batch auction (often at open/close) contrasting continuous trading. "including Japan's Itayose batch auction mechanism (vs.\ US continuous trading)"
- Leptokurtic: Having high kurtosis; distributions with frequent extreme outcomes. "Returns are leptokurtic -- extreme movements occur far more frequently than a Gaussian predicts."
- Level 3 trade messages: Detailed per-event market data messages (without full LOB snapshots). "learning from Level~3 trade messages rather than full LOB snapshots"
- Limit Order Book (LOB): The structured ledger of outstanding buy and sell limit orders. "Financial markets are predominantly organized around a Limit Order Book (LOB)"
- Liquidity: The ease of trading quickly at stable prices with minimal impact. "The ease with which an asset can be bought or sold quickly at a stable price is the asset's liquidity."
- Llama family: A family of Transformer models providing architectural baselines. "The architecture is based on the Llama family"
- Market microstructure: The mechanisms and rules governing trading and price formation at the event level. "These elements and mechanisms constitute market microstructure."
- Market orders: Orders to execute immediately against resting limit orders at best available prices. "They may also submit market orders for immediate execution against resting limit orders starting at the best bid/ask"
- Mid-price: The midpoint between the best bid and best ask prices. "the midpoint between the highest bid and the lowest ask is an asset's mid-price."
- Mixed base number system: An encoding scheme where each feature index acts as a digit with its own base. "digits in a mixed base number system."
- Multinomial sampling: Sampling next-token from a categorical distribution over the vocabulary. "We use multinomial sampling with a repetition penalty of 1.2 to decode the token."
- Order Book Imbalance: A measure of asymmetry between bid and ask volumes. "including Order Volume, Interarrival Times, Bid-Ask Spreads, and Order Book Imbalance."
- Order flow: The stream of submitted buy/sell orders and cancellations. "order flow: the stream of buy and sell orders submitted to the market"
- Perplexity: A language-modeling metric for predictive uncertainty and generalization. "moderate perplexity degradation."
- Price depth: The distance between an order’s price and the midprice (often expressed in ticks or bps). "The distance between the order price and the midprice is the price depth"
- Price-time priority: Matching rule that prioritizes orders first by price, then by arrival time. "price-time priority algorithm"
- Power-law: A heavy-tailed distribution where large values occur with non-negligible probability. "volume follows a heavy-tailed power-law"
- Rollouts: Generated sequences used to evaluate model behavior in closed-loop simulation. "TradeFM-generated rollouts reproduce key stylized facts of financial returns"
- Rotary Positional Encoding (RoPE): A positional encoding technique for Transformers enabling better extrapolation. "rotary positional encoding (RoPE)"
- Scale-invariant features: Normalized representations that are comparable across assets and liquidity regimes. "scale-invariant features and a universal tokenization scheme"
- Stylized facts: Robust empirical properties of financial markets observed across assets and time. "stylized facts of financial returns"
- Tick: The minimum allowable price increment for a security. "ticks (the minimum price increment, typically \$0.01)"
- Universal Price Formation: A theory positing cross-market regularities in price formation. "Universal Price Formation theory"
- Volume-Weighted Average Price (VWAP): The average price weighted by traded volume over a window. "Building on the classical Volume-Weighted Average Price"
- Wasserstein distance: An optimal-transport metric for comparing probability distributions. "via the Wasserstein distance ()"
- Zero-Intelligence (ZI) agent: A simple baseline agent that submits orders without strategic behavior. "a calibrated Zero-Intelligence (ZI) agent"
- Zero-shot geographic generalization: Transfer to unseen markets without fine-tuning. "zero-shot geographic generalization"
Collections
Sign up for free to add this paper to one or more collections.