What do Language Models Learn and When? The Implicit Curriculum Hypothesis
Abstract: LLMs can perform remarkably complex tasks, yet the fine-grained details of how these capabilities emerge during pretraining remain poorly understood. Scaling laws on validation loss tell us how much a model improves with additional compute, but not what skills it acquires in which order. To remedy this, we propose the Implicit Curriculum Hypothesis: pretraining follows a compositional and predictable curriculum across models and data mixtures. We test this by designing a suite of simple, composable tasks spanning retrieval, morphological transformations, coreference, logical reasoning, and mathematics. Using these tasks, we track emergence points across four model families spanning sizes from 410M-13B parameters. We find that emergence orderings of when models reach fixed accuracy thresholds are strikingly consistent ($ρ= .81$ across 45 model pairs), and that composite tasks most often emerge after their component tasks. Furthermore, we find that this structure is encoded in model representations: tasks with similar function vector representations also tend to follow similar trajectories in training. By using the space of representations derived from our task set, we can effectively predict the training trajectories of simple held-out compositional tasks throughout the course of pretraining ($R2 = .68$-$.84$ across models) without previously evaluating them. Together, these results suggest that pretraining is more structured than loss curves reveal: skills emerge in a compositional order that is consistent across models and readable from their internals.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper asks a simple question with a big payoff: as LLMs practice on lots of text (called “pretraining”), what skills do they learn first, what comes next, and is the order predictable? The authors propose the “Implicit Curriculum Hypothesis,” which says that models learn skills in a stable, step-by-step order—like a hidden curriculum—across different model sizes and training data.
The main questions in plain language
The researchers focus on three simple questions:
- Do models learn basic skills before more complicated ones that build on them?
- Is the order that skills show up mostly the same across different models and training sets?
- Can we “read” this order from what’s happening inside the model and use that to predict when new skills will appear?
How they studied it (using everyday examples)
Think of training a model like teaching a student. Before solving a word problem, the student must know how to add and read. The authors recreated this idea for LLMs.
What they did:
- Built a set of 91 tiny, clear tasks:
- Simple skills: copying text, changing to UPPERCASE, turning “run” into “running,” translating a word, or pulling a number from a sentence.
- Composite (combined) skills: chaining simple skills, like “turn ‘run’ into ‘running’ and then make it UPPERCASE,” or “translate a word and then reverse it.”
- Tracked when each skill first “clicked” during training:
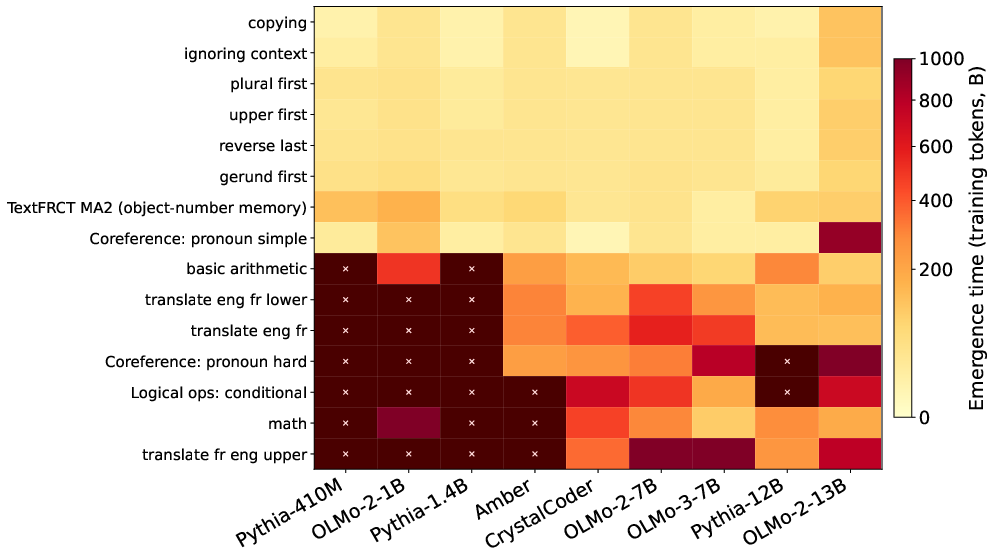
- They saved many checkpoints (snapshots) during pretraining for 9 open models (from families like OLMo, LLM360, and Pythia, ranging from 410M to 13B parameters).
- For each checkpoint, they tested each task and marked the “emergence time” as the first point the model reliably passed a fixed accuracy bar (e.g., 50% or 80% correct). Think of this like the first time a student consistently gets the right answers.
- Looked inside the models:
- They created “function vectors,” which you can think of as a fingerprint of how the model’s “internal activity” looks when it solves a particular task.
- If two tasks have similar fingerprints, the authors asked: do they also improve in a similar way over training?
- Using these fingerprints, they tried to predict the full learning curve of a new (held-out) composite task—without testing it during training—by borrowing patterns from other tasks with similar fingerprints.
Key terms in simple words:
- Pretraining: the model “reads” huge amounts of text to learn patterns.
- Emergence time: the first point in training when a skill becomes reliably usable.
- Composite task: a combination of smaller, simpler skills (like a recipe made of basic steps).
- Function vector: a summary of what the model “does inside” when it solves a task—like a task’s internal signature.
What they found and why it matters
- Skills appear in a consistent order across models
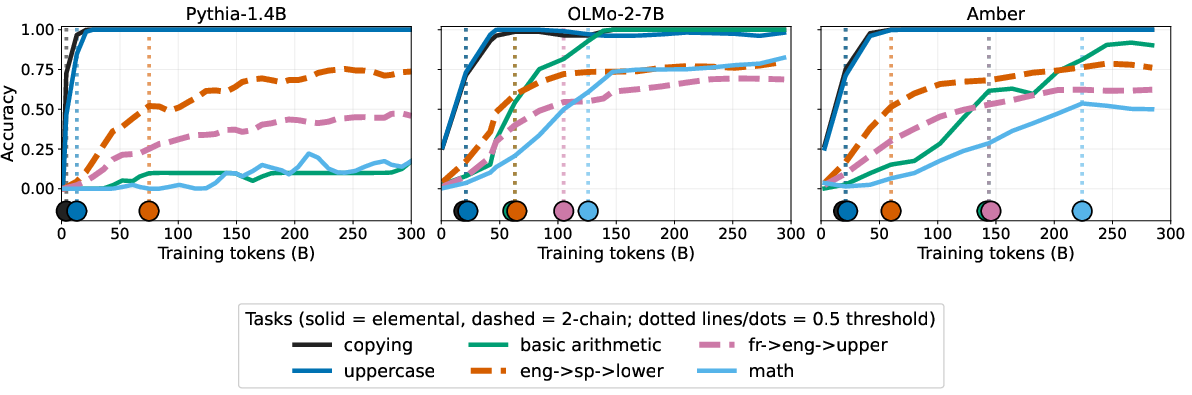
- Across 9 models from different families and sizes, the order in which skills showed up was very similar (high agreement; average Spearman correlation ≈ 0.81 across 45 model pairs).
- The order looked like this (roughly):
- First: copying and simple string edits (like UPPERCASE)
- Next: simple grammar changes (like “run → running”) and pulling facts from text
- Then: basic logical operations and simple world knowledge
- Finally: multi-step math and more complex reasoning
- Importantly, this consistency was strong when using a fixed accuracy threshold (e.g., “reach 80% correct”) rather than a relative one (e.g., “reach 80% of your own best performance”). Fixed thresholds better matched when a skill truly becomes usable.
- Combined skills usually come after their parts
- In most cases, a composite task (like “make it plural, then lowercase”) emerged after the model had learned the individual pieces (plural and lowercase).
- There were a few exceptions, showing that real training has some quirks—but the overall pattern held.
- The model’s “internals” reveal the curriculum—and can predict new skills
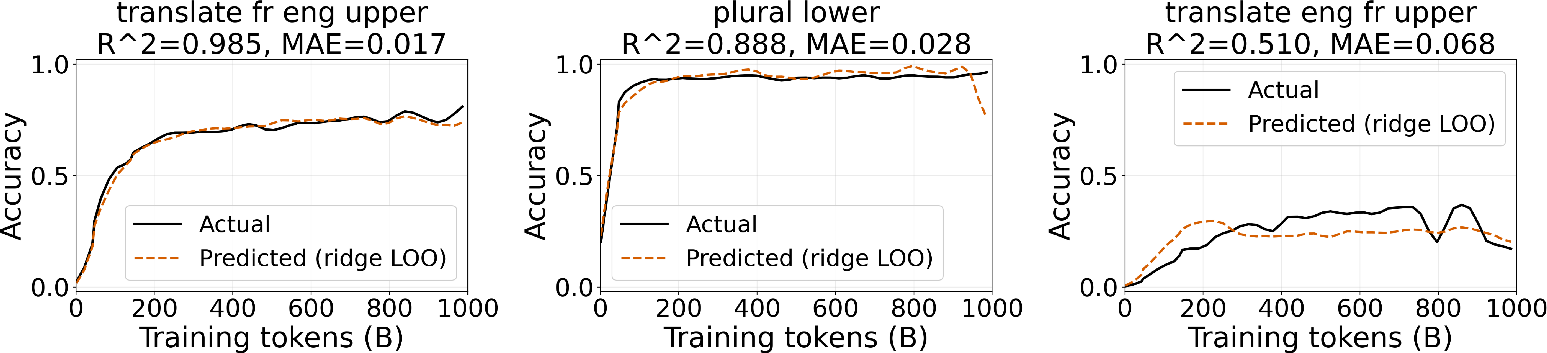
- Tasks with similar internal fingerprints also had similar training progress over time.
- Using these fingerprints, the authors could predict how well a new composite task would do at each point in training without testing it directly. The predictions were quite accurate across models (typical around 0.68–0.84).
- When they tried predicting a composite task using only simple tasks as references, the predictions got worse. This suggests composite tasks share unique patterns with each other—like a “composition bottleneck”—that aren’t fully captured by simple tasks alone.
Why this is important:
- It shows pretraining isn’t just a smooth, mysterious loss curve—it’s a structured learning process where skills unlock in a dependable order.
- If we can read and predict this order from a model’s internals, we can better monitor and steer training.
What this could change going forward
- Better training dashboards: Teams could track whether a model is “on schedule” for learning certain skills and spot when something’s off.
- Smarter data choices: If complex tasks lag, we might add data that strengthens the needed prerequisites.
- Safer, more predictable models: Predicting when a model will gain certain abilities helps with planning, evaluation, and safety reviews.
- More efficient research: If learning curves can be predicted from internals, we may need fewer full evaluations to understand progress.
In short, this paper argues that LLMs follow a hidden but reliable learning path during pretraining. That path reflects how simple skills combine into complex ones—and you can see and even predict it by looking inside the model.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, action-oriented list of what remains missing, uncertain, or unexplored in the paper.
- External validity beyond simple, synthetic tasks: The study centers on 53 simple tasks and 38 mechanical composites with unambiguous outputs; it remains unknown whether the “implicit curriculum” holds for messy, naturalistic, multi-hop tasks (e.g., long-context reasoning, open-ended QA, chain-of-thought math) where prerequisites are less clear.
- Coverage of capabilities and domains: The task suite is dominated by English string/morphological operations, basic retrieval, and short-form translation (en/fr/es). It is unclear whether the findings extend to other languages (especially morphologically rich or low-resource ones), modalities, code, or domain-specific reasoning beyond the limited code-leaning model (LLM360 Crystal).
- Confounding role of pretraining data frequency: The paper does not quantify how task emergence orders relate to the frequency and co-occurrence of supporting patterns in the pretraining data. Future work should measure and control for data availability to disentangle “curriculum” from “frequency-first” learning.
- Sensitivity to tokenizer and architecture choices: Tasks like
upper,reverse, andfirst_letterare highly tokenizer- and byte/character-handling dependent. The study does not control for tokenizer differences (e.g., BPE vs. byte vs. unigram) or architectural variants (e.g., RoPE vs. ALiBi, MoE, context length), leaving open whether the observed orderings are robust to these design choices. - Limited model scale and diversity: Results are reported for 410M–13B parameter models and only a subset of open-weight families. It is unknown whether the same compositional ordering and representational alignment hold for much larger models (e.g., 30B–>100B), sparse MoE models, or multilingual pretraining runs.
- Early vs. late training generalization: Analyses focus on the first ~1T tokens and ~20 checkpoints (≈20B-token granularity). Some capabilities may emerge later, and coarse checkpointing could misorder close-onset skills. A higher-resolution and longer-horizon study is needed to validate ordering stability.
- Ambiguity in emergence thresholding: Emergence is defined via fixed absolute accuracy thresholds ( varies across figures/tables, e.g., 50% vs. 80%). There is no sensitivity analysis across , per-task baselines/chance levels, or confidence intervals for emergence times, leaving ordering robustness unquantified.
- Relative-threshold instability remains unexplained: Cross-model ordering collapses under relative thresholds; the paper hypothesizes a cause but does not validate it. Systematic tests (e.g., calibration across different maximum-performance anchors or dynamic baselines) are needed.
- Inversions and their causes: Compositional inversions (notably involving
first_letter) are observed but not explained. Are these due to tokenization quirks, shortcut features, prompt formats, or data artifacts? A targeted mechanistic or data-frequency analysis is needed. - Dependence on in-context learning and prompt design: All evaluations use ICL with exact-match; the number and format of shots, prompt templates, and decoding settings are not detailed or ablated. It is unclear whether “emergence” reflects latent in-weights competence or prompt-sensitivity effects.
- Generalization to post-training stages: The study focuses on pretraining; it is unknown how SFT/RLHF or continued pretraining perturb the observed curriculum or the representational geometry–trajectory link.
- Representational timing and causality: Function vectors (FVs) are computed from correctly answered prompts, but the paper does not specify at which checkpoint(s) they are extracted for prediction. If final-checkpoint FVs are used to predict early training trajectories, this conflates predictive monitoring with retrospective analysis. Can early-checkpoint FVs forecast future learning? Is there causal evidence linking specific circuits to trajectory changes?
- Layer/feature selection instability: FV extraction depends on layer choice, head selection via CIE, and “best performing” extraction method per model. There is no systematic ablation on layer depth, head sparsity, or alternative representation methods (e.g., CCA/SVCCA, path-patching), leaving the stability and generality of FV-based similarity underexplored.
- Composition bottleneck interpretation: The degradation in LOO performance when excluding composite tasks might reflect limited basis diversity rather than a fundamental “composition bottleneck.” Formal tests with synthetic bases that span compositional function space, or compositional kernels, are needed.
- Unequal chance baselines across tasks: Exact-match thresholds are set “above chance,” but tasks have different chance levels (e.g.,
first_letter≈ 1/26 vs.uppercase≈ near-deterministic). Without calibrated per-task thresholds or normalized effect sizes, cross-task ordering could reflect baseline differences. - Lack of seed/reproducibility analysis: Only one run per model is used; variance across seeds and training instabilities (cf. Polypythias) are not assessed. Do emergence orders remain stable across multiple runs with identical settings?
- Data-mixture interventions are not tested: The paper posits that curriculum insights could guide data mixtures but does not perform controlled ablations (e.g., remove/augment translation data) to observe predicted shifts in emergence.
- Limited evaluation details for translation and knowledge tasks: Exact-match on translation introduces synonym/equivalence issues; the paper does not clarify normalization (e.g., detokenization, casing) or handle multiple valid outputs, raising evaluation-noise concerns.
- Potential selection bias in FV construction: FVs are averaged over correctly answered prompts only, which may bias representations toward later-stage behavior or toward easier submodes of a task. Alternative strategies (e.g., weighting by confidence, using near-miss examples) are not evaluated.
- Granularity of compositional prerequisites: The dependency graph is designer-imposed; the study does not infer learned dependencies or validate whether the same subcircuits are reused across tasks. Can data-driven or circuit-level graphs be recovered, and do they align with the designed DAG?
- Limited OOD tests for trajectory prediction: LOO predictions are done within the same task family; the ability to predict trajectories for truly out-of-distribution composites or new elemental operations is not assessed.
- No uncertainty quantification for predictions: Kernel ridge regression predictions are point estimates without confidence intervals; the practical utility for training-time monitoring would require calibrated uncertainty and detection of distribution shifts.
- Decoder strategy and evaluation variance: The decoding regime (greedy vs. sampling), temperature, and determinism settings are not specified. For tasks like translation and retrieval, these choices can affect exact-match accuracy and apparent emergence timing.
- Practical monitoring pipeline remains unvalidated: Although the paper proposes pretraining monitoring applications, it does not implement an online system that uses early FVs or partial evaluations to detect schedule slippage in real time.
- Mechanistic interpretability link is correlational: The “legibility in representations” result shows correlation in vector geometry and trajectory similarity; it does not identify or validate specific circuits across training that implement the hypothesized computations.
- Long-context and memory-dependent skills: The study does not probe how skills that require long-range dependencies (e.g., multi-document retrieval, long-context coreference) emerge or whether they follow similar compositional constraints.
Practical Applications
Summary
The paper proposes and validates the Implicit Curriculum Hypothesis: during pretraining, LLM skills emerge in a consistent, compositional order across model families, and this order is legible in internal representations. Using a curated suite of simple and composite tasks and “function vectors,” the authors show (a) stable emergence rankings under absolute accuracy thresholds, (b) composites usually follow their prerequisites, and (c) the learning trajectories of unseen composite tasks can be predicted from representational similarity (kernel ridge regression achieving –). These findings enable pragmatic tools for monitoring, forecasting, and steering pretraining.
Below are practical applications derived from these findings and methods.
Immediate Applications
The following applications can be deployed now with open-weight models and accessible activations/checkpoints.
- Pretraining monitoring dashboards for capability emergence (Industry: ML infrastructure/MLOps; Academia)
- Use the provided “ElementalTask” suite and fixed accuracy thresholds to track when key skills (e.g., copying, coreference, logic, arithmetic) emerge; set alerts for off-schedule development.
- Tools/workflows: “Capability timeline” dashboards integrated with training logs; checkpoint-by-checkpoint task sweeps; Gaussian-smoothed trajectory plotting.
- Assumptions/dependencies: Access to intermediate checkpoints; evaluation harness; thresholds set above chance; tasks relevant to target domain.
- Checkpoint selection for alignment and fine-tuning (Industry: Foundation model labs; Academia)
- Choose pretraining checkpoints where prerequisites for a downstream task are already acquired to maximize efficient SFT/RLHF.
- Tools/workflows: “Prereq gate” that verifies skill set before tuning; auto-selection of optimal checkpoint per target dataset.
- Assumptions: Stable ordering holds for your data mix/model family; availability of multiple intermediate checkpoints.
- Data-mixture diagnostics and targeted augmentation (Industry; Academia)
- When specific skills lag, adjust the pretraining data mixture to include more examples that exercise missing elementals (e.g., morphological patterns, coreference, simple logic).
- Tools: Data sampling scheduler tied to skill gap reports; curriculum-aware data curation.
- Assumptions: Access to and control over data pipeline; skill tasks reflect target competencies.
- Capability forecasting during a run via function vectors (Industry: MLOps; Academia)
- Use function-vector similarity to predict trajectories of held-out composite tasks without evaluating them at every checkpoint, saving compute.
- Tools: Lightweight “trajectory predictor” using kernel ridge regression over task embeddings; periodic FV extraction on correctly answered prompts.
- Assumptions: Activation access for FV extraction; choice of layer/heads tuned; predictions are better for tasks with close neighbors in FV space.
- Acceptance tests and skill-based SLAs for model releases (Industry: Product/QA; Policy: Transparency)
- Define “skill SLAs” (e.g., ≥80% on coreference and simple logic) as release gates; include skill-emergence curves in model cards.
- Tools: CI pipelines running elemental/composite test suite per release; automated pass/fail badges.
- Assumptions: Task suite approximates user-critical capabilities; fixed thresholds correlate with usability.
- Early anomaly and regression detection (Industry: MLOps; Academia)
- Detect deviations from expected emergence order (e.g., inversions, stalls) as signals of training bugs, data contamination, or regressions.
- Tools: Statistical monitors on rank correlations versus reference runs; root-cause analysis workflows.
- Assumptions: Reference runs exist; same token granularity and logging fidelity.
- Benchmark design and diagnosis (Academia; Standards bodies)
- Build modular benchmarks whose composites align with measured prerequisites; when a downstream metric stalls, diagnose which elemental skills are the bottleneck.
- Tools: DAGs mapping benchmark items to prerequisite tasks; per-skill ablation reports.
- Assumptions: Clear mapping from benchmark items to elemental operations.
- Sector-specific audit checklists for domain LLMs (Healthcare, Finance, Legal)
- Before domain fine-tuning, verify that language and reasoning prerequisites (e.g., entity extraction, coreference, numerical fluency) have emerged; mitigate brittle behavior on sensitive tasks.
- Tools: Domain-adapted task suites (e.g., clinical entity extraction + coref + arithmetic checks).
- Assumptions: Domain tasks can be decomposed into available elementals or close proxies; institutional evaluation policies allow such audits.
- Cost-aware training decisions (Industry)
- Use emergence checkpoints to decide early stopping, continued pretraining, or rebalancing compute when marginal returns on key skills decline.
- Tools: “Compute allocator” using slope changes in skill trajectories; alerts on plateau detection.
- Assumptions: Costs tied to pretraining tokens; business KPIs map to skill proxies.
- Open-source reproducibility and pedagogy (Academia; Community)
- Adopt the task suite and FV extraction scripts to teach and reproduce pretraining dynamics; compare model families’ curricula on shared plots.
- Tools: Public repos integrating ElementalTask, FV extraction, and prediction code.
- Assumptions: Compatible open-weight models; consistent prompt templates.
Long-Term Applications
These applications require broader validation, scaling, closed-model integration, or new infrastructure.
- Curriculum-optimized pretraining schedulers (Industry: Training platforms; Academia)
- Dynamically sample data to satisfy prerequisite DAGs and accelerate targeted skills; adaptively emphasize lagging elementals to minimize total compute for desired composites.
- Potential product: “CurriculumEngine” that jointly optimizes loss and skill acquisition order.
- Assumptions: Stable dependency graphs across scales/data; online feedback loops; task coverage of target capabilities.
- Automated skill discovery and synthetic data generation (Industry; Academia)
- Cluster tasks in function-vector space to identify missing competencies; auto-generate synthetic data (or retrieve web data) to fill gaps.
- Products: “Skill gap finder” + synthetic data generator tied to FV neighborhoods.
- Assumptions: FV geometry generalizes; synthetic data faithfully trains desired circuits; evaluation avoids shortcut learning.
- Safety gating and capability risk monitors (Policy; Industry: Safety teams)
- Define “hazardous skill” proxies (e.g., long-horizon planning, code-execution reasoning) and monitor their emergence; gate scaling or release when trajectories cross risk thresholds.
- Tools: Regulatory-grade capability dashboards; red-teaming hooks triggered by skill thresholds.
- Assumptions: Valid proxies for risky capabilities; governance frameworks that accept skill metrics.
- Cross-model skill transfer and “skill packs” (Industry; Academia)
- Transfer or distill specific circuits/skills at selected checkpoints into smaller models; compose modular “skill packs” for domain models.
- Products: Skill-level distillation pipelines; plug-in adapters aligned with function vectors.
- Assumptions: Stable, localizable circuits for skills; compatibility across architectures; IPR constraints.
- Modular architectures and routing by skill (Software; Platforms)
- Route queries to submodules specialized in elemental skills; compose outputs for composite tasks to improve reliability and latency.
- Products: Skill-aware routers; microservice-style LLM architectures.
- Assumptions: Reliable skill identification at inference time; low-latency composition.
- Compute budgeting and capability-phase forecasting (Industry; Finance/Operations)
- Predict capability milestones and marginal returns before or early in training; structure contracts and budgets around forecasted emergence timelines.
- Tools: Pretraining “capability P&L” planners; scenario simulators using FV-based forecasts.
- Assumptions: Early FV signals correlate with final trajectories at larger scale; stable ROI mappings.
- Standardized capability reporting for regulation and procurement (Policy; Enterprise IT)
- Require “capability emergence profiles” in model cards for high-risk AI; define sector-specific prerequisite checklists for compliance.
- Artifacts: Standards for absolute-threshold reporting; sector templates (e.g., clinical reasoning prerequisites).
- Assumptions: Consensus on task suites and thresholds; acceptance by regulators and auditors.
- Continual learning with curriculum awareness (Industry)
- After deployment, monitor whether further pretraining/fine-tuning preserves prerequisite structure; detect and prevent regressions or inversions (e.g., catastrophic forgetting of elementals).
- Tools: Live skill monitors integrated with continual pretraining jobs.
- Assumptions: Sufficient evaluation access in production; mapping of new data to skill impacts.
- Multimodal and robotics curriculum planning (Robotics; Autonomy; Education tech)
- Extend implicit curricula to vision-language-action models; ensure sensorimotor composites emerge after perception and grounding prerequisites.
- Products: Robot training curricula that sequence simulation tasks by measured prerequisites; multimodal skill dashboards.
- Assumptions: Findings generalize beyond text-only LMs; availability of multimodal task analogs and activation access.
- Feature-based supervision and alignment via interpretability (Academia; Safety)
- Use representational geometry to define reward proxies (“features as rewards”) and steer training toward desired skills while avoiding undesired ones.
- Tools: Reward shaping from FV-based features; contrastive activation interventions alongside curriculum.
- Assumptions: Reliable, steerable feature extraction; alignment between features and human-valued capabilities.
- Education-focused AI tutor training (Education)
- Translate prerequisite DAGs into pedagogical curricula for model-based tutors that learn/teach in human-like sequences; monitor the tutor’s internal skill acquisition for transparency.
- Products: Tutor training pipelines aligned with curricular graphs; teacher dashboards showing skill competence growth.
- Assumptions: Mapping from LM elementals to educational skills; ethical frameworks for student data.
Cross-cutting assumptions and dependencies
- Access to intermediate checkpoints and model activations is crucial for FV extraction and fine-grained monitoring; proprietary models may require alternative probes or post-hoc approximations.
- Absolute thresholds must be set above chance and calibrated per task; relative thresholds are less reliable for cross-model comparisons.
- Task coverage: the current suite focuses on simple composable operations; domain deployment may need expanded, domain-specific elementals and composites.
- Generalization beyond 13B models and across very different data mixtures requires further validation.
- Some composites showed inversions (e.g., involving first_letter), so curriculum tools should treat ordering as probabilistic, not absolute.
Glossary
- Absolute threshold: A fixed, model-agnostic accuracy cutoff used to define when a task has emerged during training. "this consistency holds only under the absolute threshold definition of emergence."
- Attention heads: Individual attention mechanisms within a transformer layer that focus on different patterns or relations in the input. "We use causal indirect effect (CIE) analysis to identify a sparse set of attention heads "
- Causal indirect effect (CIE) analysis: A causal analysis method used to estimate the contribution of intermediate components (e.g., attention heads) to an outcome. "We use causal indirect effect (CIE) analysis to identify a sparse set of attention heads"
- Composite tasks: Tasks constructed by chaining multiple simpler (elemental) operations whose dependencies are known by design. "composite tasks most often emerge after their component tasks."
- Composition bottleneck: A phenomenon where modeling or prediction quality worsens when only elemental components are used, indicating additional difficulty in composing skills. "Restricting to elementals degrades MAE for every model (mean MAE ), indicating a composition bottleneck."
- Compositional ordering: The principle that prerequisite tasks should emerge no later than tasks that depend on them. "Compositional ordering. Tasks emerge no later than the tasks constructed to depend on them:"
- Cosine similarity: A measure of angle-based similarity between vectors, used here to compare task representations. "We measure similarity between tasks via cosine similarity between their task representations."
- Cross-entropy loss: A standard loss function for probabilistic models measuring the divergence between predicted and true distributions. "Cross-entropy loss decreases smoothly even as qualitatively different skills are acquired at sudden transition points"
- Directed acyclic graphs (DAGs): Graphs with directed edges and no cycles, used to represent prerequisite relationships among skills. "represent skills as directed acyclic graphs (DAGs), where an edge from skill to skill indicates that training on data associated with reduces the amount of data needed to learn ."
- Emergence order: The relative ordering of tasks by when they cross a defined competence threshold during training. "We first test H1 and H2 by examining whether the emergence order of tasks is consistent across models"
- Emergence time: The training step at which a task first surpasses a specified performance threshold. "Let denote the emergence time of task for model "
- Function vector space: The space formed by task representation vectors capturing computations models perform for tasks. "To test the composition bottleneck, we compare two conditions for the function vector space:"
- Function vectors: Representation vectors extracted from model internals that characterize the computation used to solve a task. "we extract task representations (function vectors) from the models."
- Gaussian kernel: A smoothing or similarity function based on the Gaussian distribution, used here to smooth curves or measure similarity. "smoothed with a Gaussian kernel ()."
- Gaussian smoothing: Applying a Gaussian filter to smooth time-series or trajectories. "apply Gaussian smoothing ()"
- ICL (in-context learning): The ability of a model to learn a task from examples provided in the input context without parameter updates. "These are followed by simple ICL tasks such as uppercasing and lowercasing,"
- Kernel matrix: The matrix of pairwise kernel evaluations among training tasks used in kernel methods. "Let be the kernel matrix"
- Kernel ridge regression: A kernelized regression method combining ridge regularization with a kernel to model nonlinear relationships. "We use kernel ridge regression to learn a predictor for the held-out task performance"
- Leave-one-out (LOO) protocol: An evaluation setup where one item (e.g., a task) is held out for testing while the rest are used for training. "We operationalize H3 through a leave-one-out (LOO) protocol over composite tasks."
- MAE (mean absolute error): An error metric measuring the average absolute difference between predicted and true values. "We evaluate prediction quality via per-task Pearson and MAE"
- Pearson : The squared Pearson correlation coefficient, measuring variance explained by predictions. "We evaluate prediction quality via per-task Pearson and MAE"
- Power laws: Mathematical relationships where a quantity varies as a power of another, used to describe scaling behavior. "These relationships are well-approximated by power laws of the form "
- Quanta: Discrete units of learned skills hypothesized to explain smooth scaling behavior. "discrete skills, termed quanta."
- Quantization Hypothesis: The hypothesis that smooth improvements arise from acquiring discrete skills (quanta) in sequence. "Quantization Hypothesis \cite{michaud2023the} offers a hypothesis that these smooth scaling curves arise from the learning of discrete skills, termed quanta."
- RBF kernel: The radial basis function kernel, a similarity function used in kernel methods. "compute pairwise similarities using an RBF kernel:"
- Residual stream: The main information pathway in a transformer where residual connections carry representations across layers. "Tasks whose internal representations are nearby in the model's residual stream, measured via function vectors"
- Representational geometry: The geometric structure of representation spaces (e.g., distances/similarities) that relates to model behavior. "This further implies that trajectories of unseen tasks can be predicted from representational geometry alone, without evaluating them during training."
- Scaling laws: Empirical relationships describing how model performance scales with data and model size. "Scaling laws characterize the relationship between a model's held-out validation loss and the compute budget allocated to training"
- Simplicity bias: The tendency of gradient-based learners to acquire simpler functions before more complex ones. "tend to exhibit simplicity bias, a tendency to learn simpler functions before more complex ones"
- Spearman rank correlation: A nonparametric measure of ordinal association between two rankings. "Spearman rank correlation () of emergence orderings between model pairs"
- Unit-normalized: Scaled to have unit length (norm one), typically for comparability in similarity computations. "We extract unit-normalized residual stream representations for all tasks"
Collections
Sign up for free to add this paper to one or more collections.