- The paper demonstrates that LLM in-context learning emerges from compositional data structures and implicit grammar induction.
- It derives learnability bounds that link the grammar description length to error rates in next-token prediction tasks.
- Experimental validation with synthetic datasets confirms that chain-of-thought prompting effectively reduces errors in complex reasoning.
A Theory of Emergent In-Context Learning as Implicit Structure Induction
Introduction
The paper "A Theory of Emergent In-Context Learning as Implicit Structure Induction" presents a theoretical framework to explain how LLMs exhibit in-context learning (ICL) capabilities. It posits that these capabilities arise from the inherent compositional structure of natural language data, which allows models to learn tasks in-context through the recombination of observed patterns. The analysis provides an information-theoretic bound demonstrating how these abilities manifest purely from next-token prediction tasks when pretrained on sufficiently compositional data. The authors introduce a controlled setup to empirically validate their theoretical predictions, focusing on the representation and emergence of ICL and proposing explanations for phenomena such as chain-of-thought prompting.
Compositionality in LLMs
The paper theorizes that the ability of LLMs to learn tasks in-context stems from their exposure to data with rich compositional structures. It defines a mechanism by which LLMs can infer and reconcile the latent structures of prompts based on probabilistic grammars and derivation trees. The authors argue that when language data is treated as being generated from a probabilistic context-free grammar (PCFG), extended with shared variables and iterative subtrees, it allows models to develop parsimonious explanations for task prompts (Figure 1).
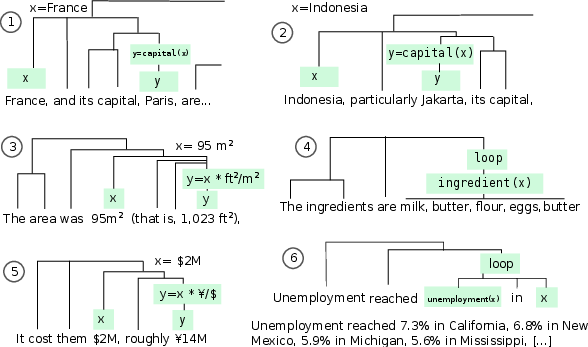
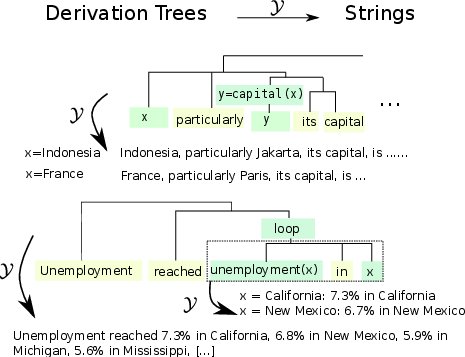
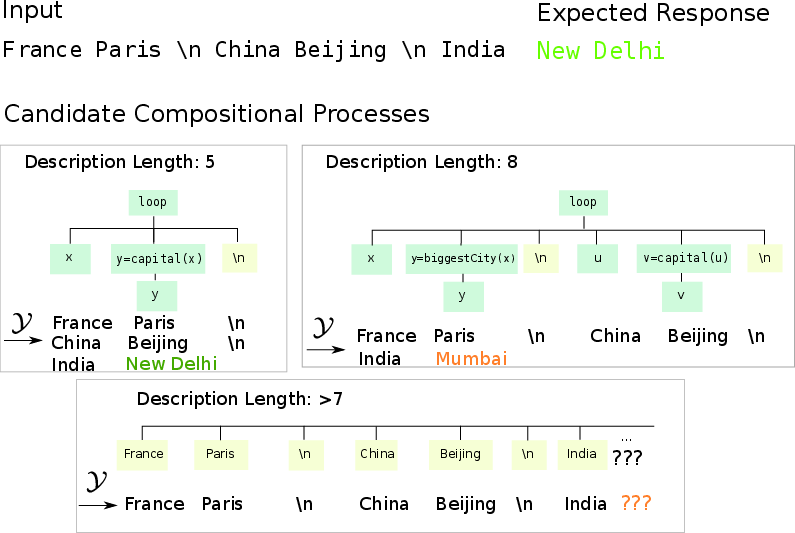
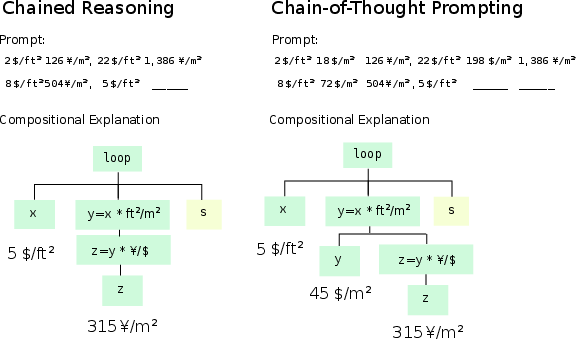
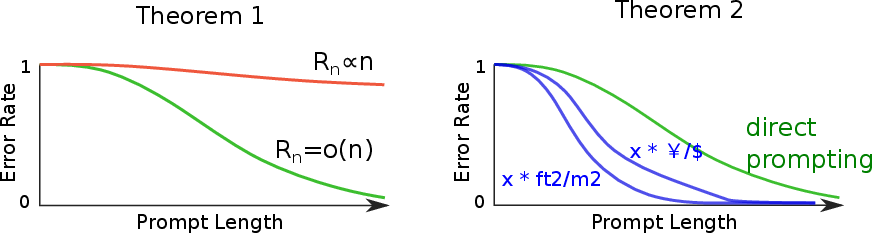
Figure 1: A depiction of natural language generation as a compositional process with derivation trees and yield operations.
Theoretical Framework
The core contribution of this work is the establishment of a theoretical analysis that provides conditions under which generic next-token prediction gives rise to ICL:
- World Model Assumptions: The pretraining data and few-shot tasks are modeled as being generated from finite universes of objects, using a grammar formalism that reflects linguistic principles of compositionality and attribute sharing.
- Learnability Bounds: Through Theorem 1, the authors derive an error bound that connects the description length of defining functions within a structured grammar to ICL capabilities. This establishes that errors in learning can be bounded by the complexity of the grammar underlying the pretraining distribution, promoting parsimonious derivations as observed input structures increase in complexity.
Empirical Validation
The paper introduces a comprehensive experimental framework involving synthetic data to validate theoretical claims:
Chain-of-Thought and Prompting
Another significant insight from the study is the affirmation of chain-of-thought prompting as a mechanism to enhance ICL proficiency. The authors theoretically demonstrate, via Theorem 2, that revealing intermediate steps in a reasoning chain minimizes errors and accelerates learning. This is further substantiated by empirical results showing improved performance when models are prompted to output intermediate reasoning steps before answers (Figure 3).
Figure 3: Demonstrating how chain-of-thought transforms complex tasks into simpler stepwise reasoning processes.
Implications and Future Directions
- Scaling Impacts: The results underscore that increasing model size and the magnitude of compositional training data correlates with more profound emergent ICL capabilities, suggesting pathways for scaling model and data complexity in pursuit of enhanced language understanding.
- Recombination: The ability for LLMs to recombine skills not explicitly seen together during pretraining highlights a potential for leveraging latent structures in data more effectively.
- Real-World LLMs: Though the study is primarily theoretical and synthetic, its findings offer explanations for behaviors observed in state-of-the-art LLMs like GPT-3, particularly concerning emergent abilities and task performance variability based on prompt construction.
Conclusion
The paper presents a compelling theoretical framework tying in-context learning to the implicit structural induction capabilities of LLMs, supported by empirical validation. It advances the understanding of how compositional data structures underpin the emergence of sophisticated reasoning tasks in LLMs and proposes methodologies to foster these abilities further. The insight into chain-of-thought processes as a tool for reducing error rates in complex task completion provides a practical approach to designing better interaction strategies with LLMs, paving the way for more generalizable and robust AI systems.


