How Do Language Models Compose Functions?
Abstract: While LLMs appear to be increasingly capable of solving compositional tasks, it is an open question whether they do so using compositional mechanisms. In this work, we investigate how feedforward LLMs solve two-hop factual recall tasks, which can be expressed compositionally as $g(f(x))$. We first confirm that modern LLMs continue to suffer from the "compositionality gap": i.e. their ability to compute both $z = f(x)$ and $y = g(z)$ does not entail their ability to compute the composition $y = g(f(x))$. Then, using logit lens on their residual stream activations, we identify two processing mechanisms, one which solves tasks $\textit{compositionally}$, computing $f(x)$ along the way to computing $g(f(x))$, and one which solves them $\textit{directly}$, without any detectable signature of the intermediate variable $f(x)$. Finally, we find that which mechanism is employed appears to be related to the embedding space geometry, with the idiomatic mechanism being dominant in cases where there exists a linear mapping from $x$ to $g(f(x))$ in the embedding spaces. We fully release our data and code at: https://github.com/apoorvkh/composing-functions .
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1. Brief overview of the paper
This paper asks a simple question: when LLMs solve problems that need two steps, do they actually do step 1 and then step 2, or do they jump straight to the final answer? The authors study tasks that can be written like (do first, then do ). For example: given a book title (), find the author (), then find the author’s birth year ().
They find that LLMs often know the pieces (step 1 and step 2) but still struggle to combine them. And when models do succeed, they sometimes follow the two-step path, but other times they skip showing any trace of the middle step and go directly to the result.
2. Key objectives and questions
The paper explores three main questions in plain language:
- Can LLMs reliably handle two-step problems (like “first look up A, then look up something about A”)? Or do they have a “compositionality gap,” where they can do each step alone but fail at combining them?
- When LLMs succeed, do they solve the problem in a truly two-step way (compute the middle answer on the way to ), or do they jump straight to the final answer?
- What makes a model choose one way or the other? Does it depend on how information is stored inside the model (like the “map” of word meanings in its internal space)?
3. How they studied it (methods explained simply)
Think of the model’s brain as a stack of layers, each passing messages along. The authors did three things:
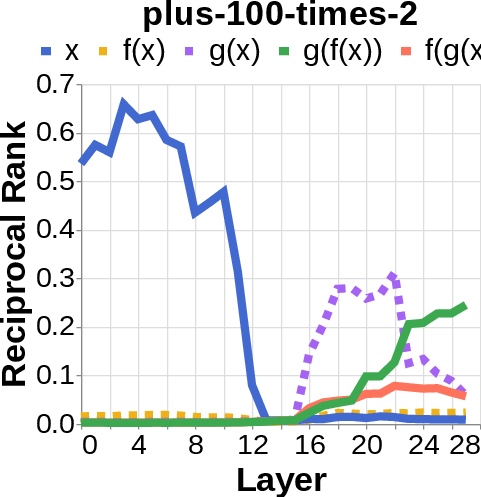
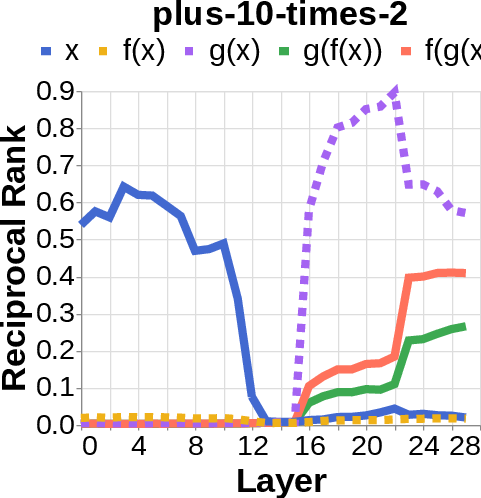
- They tested many two-step tasks. Examples include:
- Word tasks: “find the antonym of a word, then translate it to Spanish.”
- Facts: “movie title → director → director’s birth year,” “park → country → capital.”
- Simple math: “add 100, then multiply by 2.”
- They used in-context learning (ICL): This means they showed the model a few Q&A examples before asking a new, similar question. It’s like giving a model a mini study guide right before the test.
- They “peeked” inside the model while it was thinking:
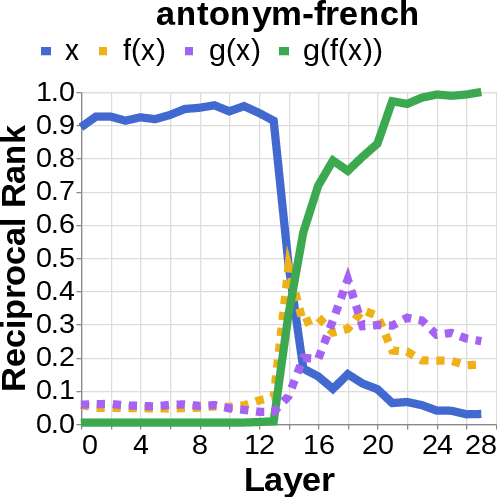
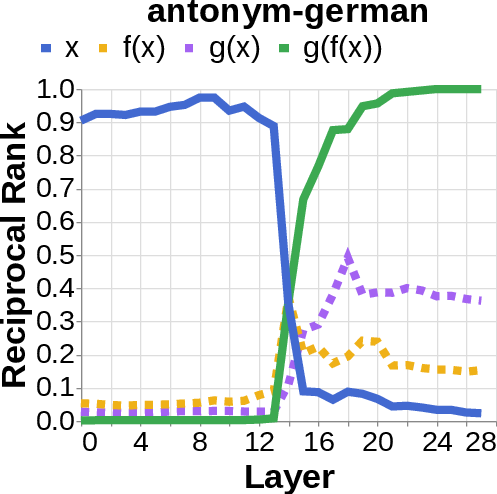
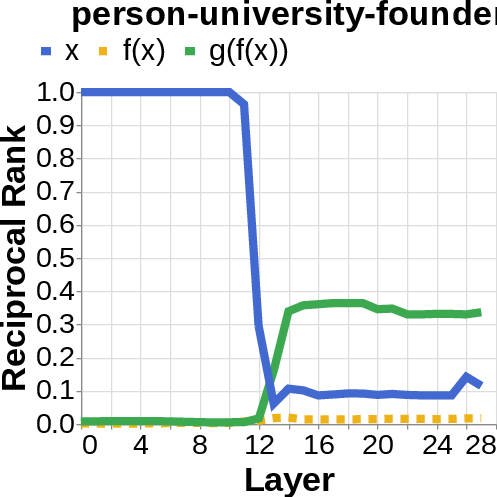
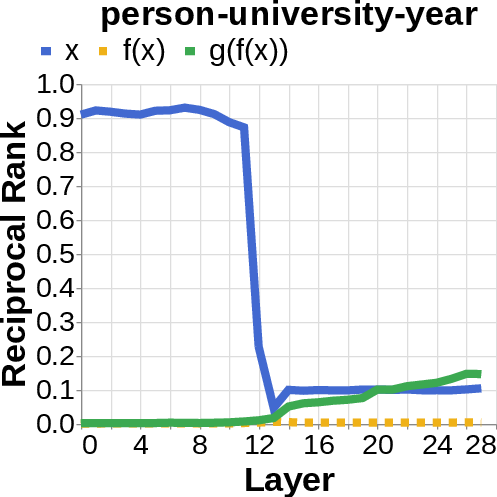
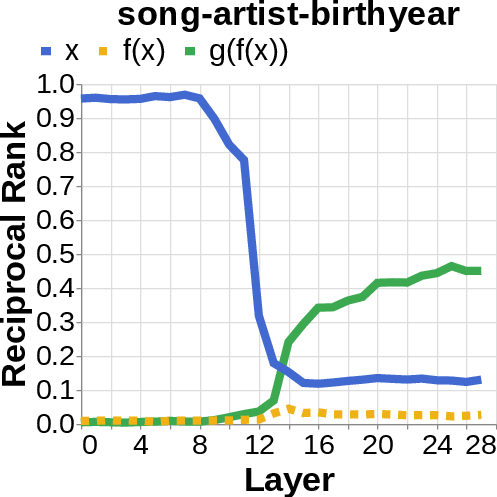
- Logit lens: Imagine reading the model’s scratchpad as it works—this tool projects the model’s inner signals back into words, so you can see which words (like the author’s name or the birth year) are appearing strongly in different layers.
- Residual stream: This is the model’s main “scratchpad” that passes running information forward through the layers.
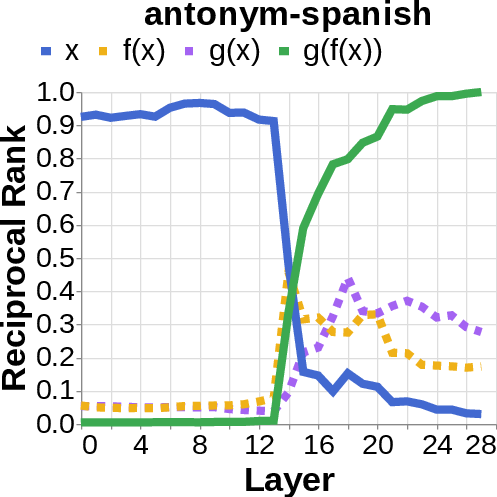
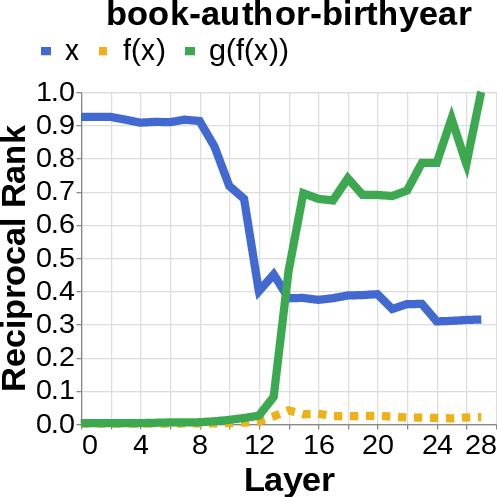
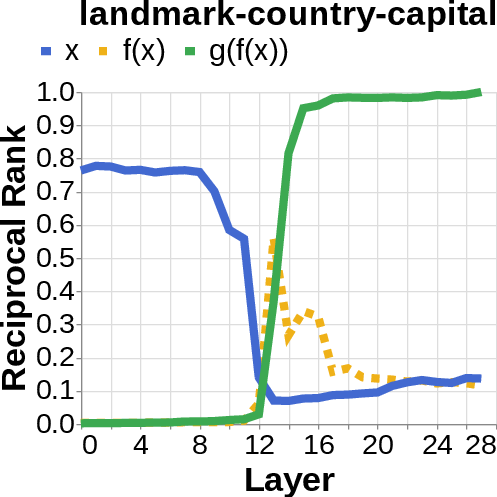
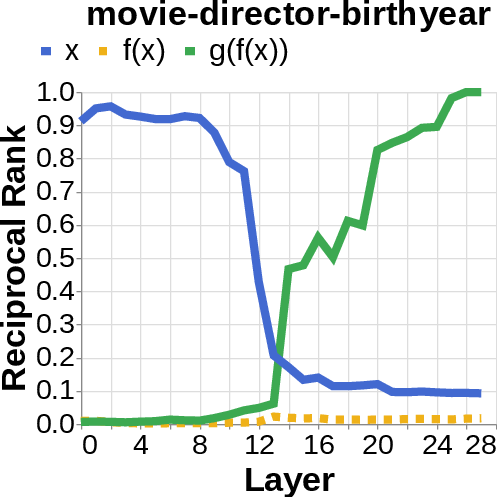
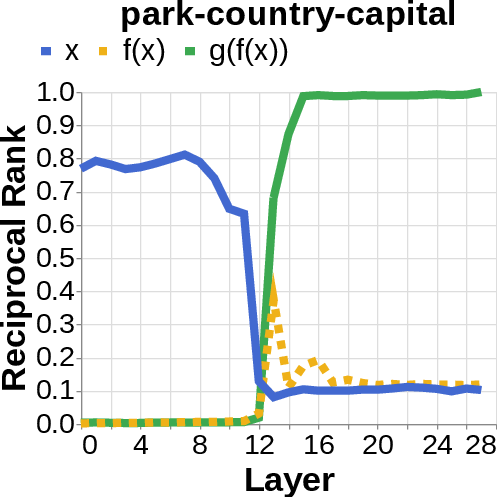
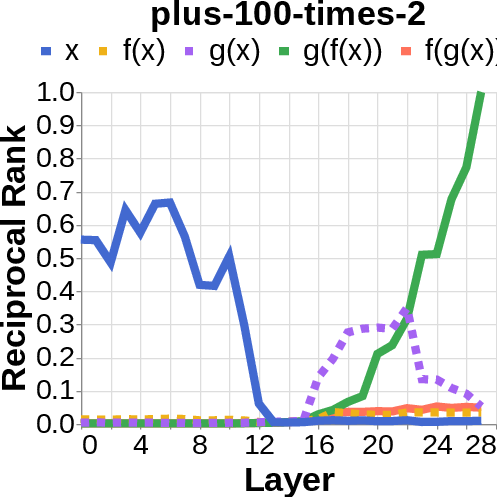
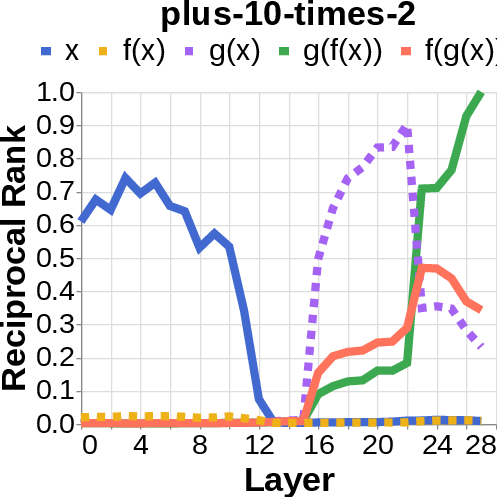
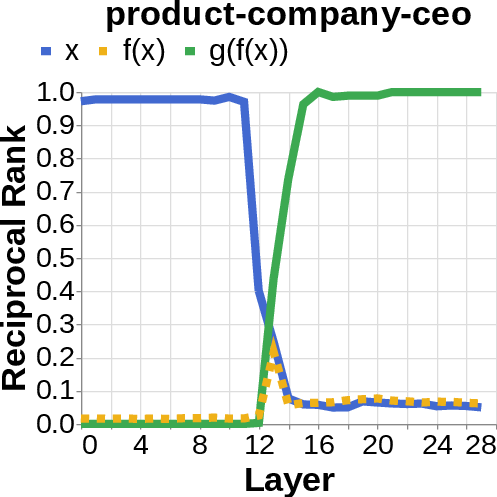
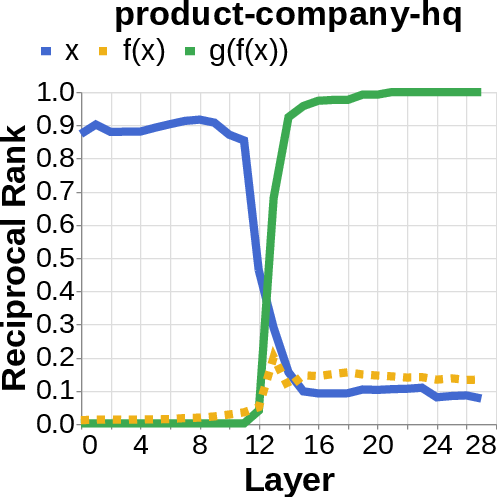
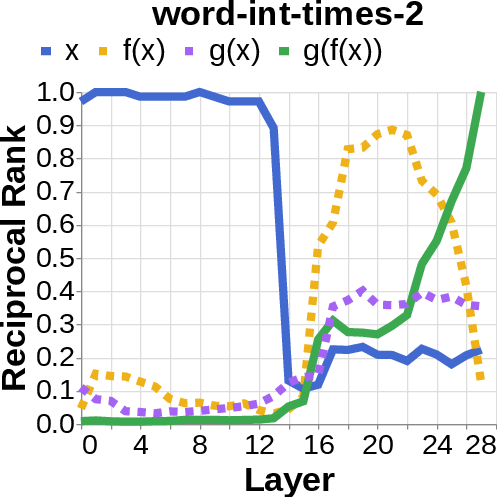
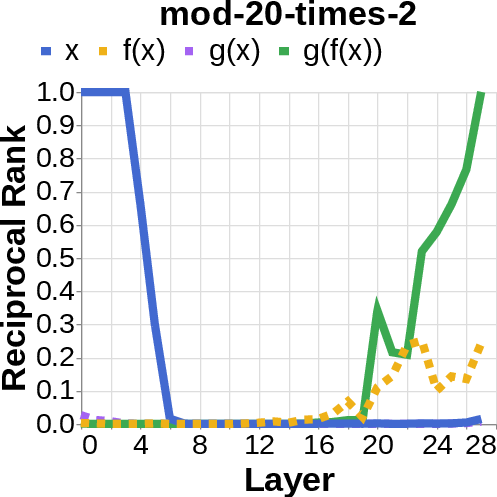
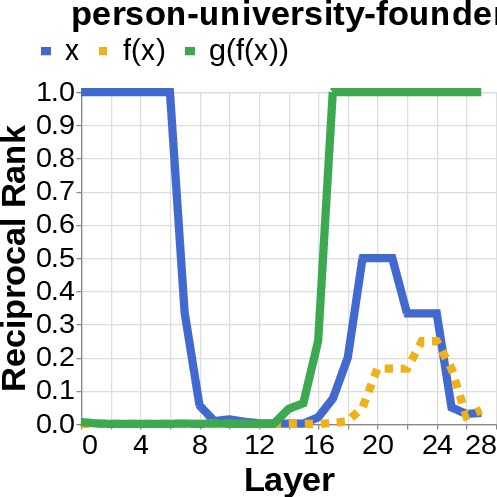
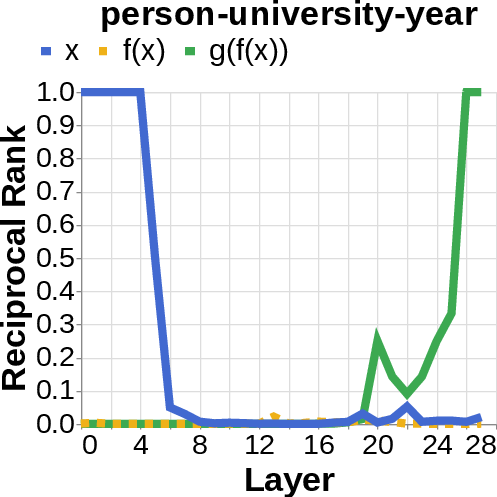
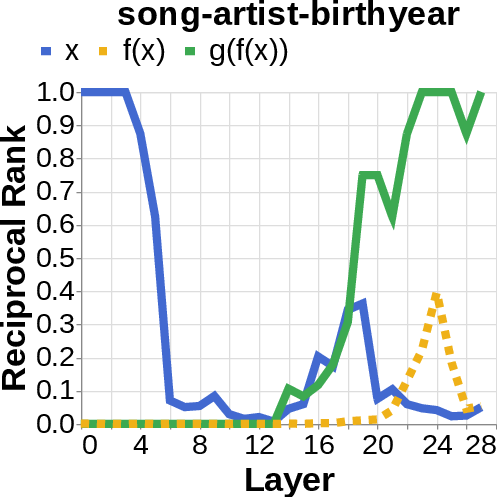
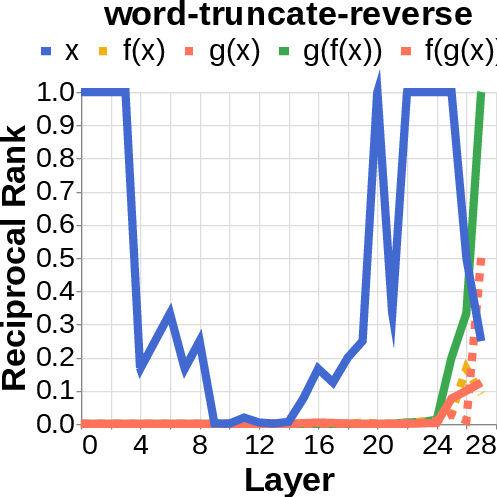
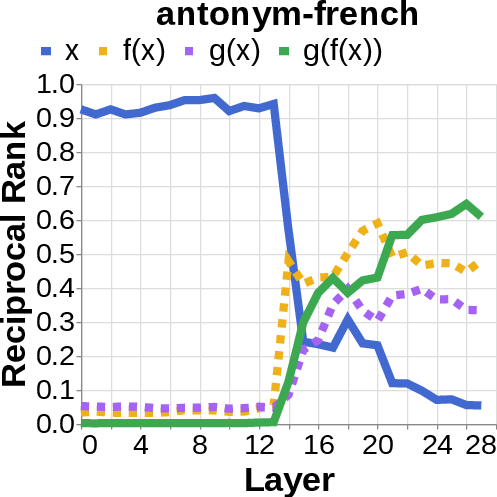
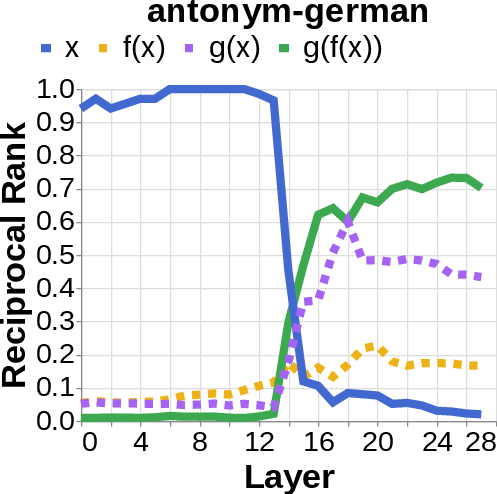
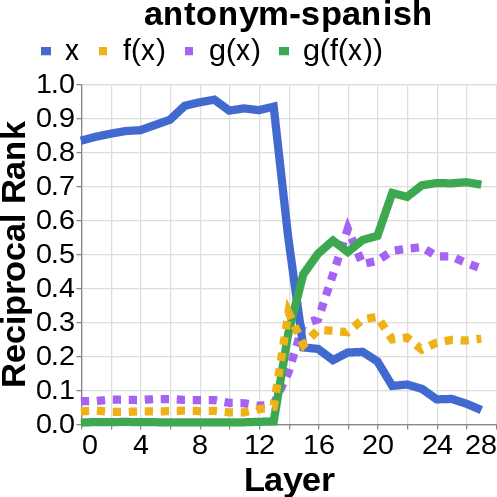
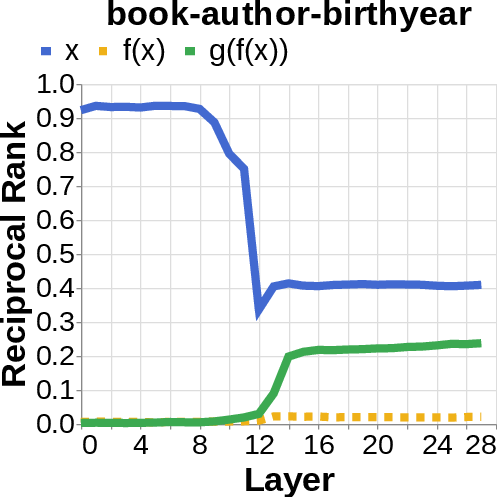
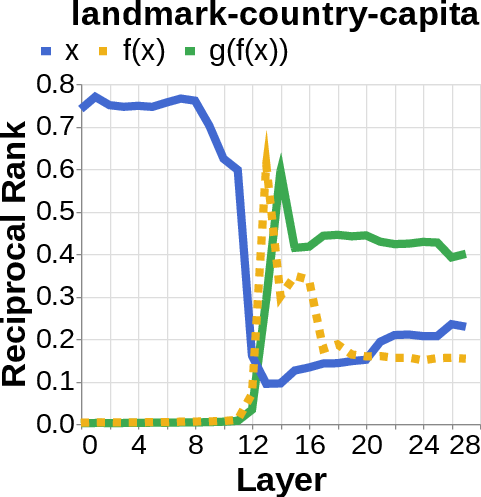
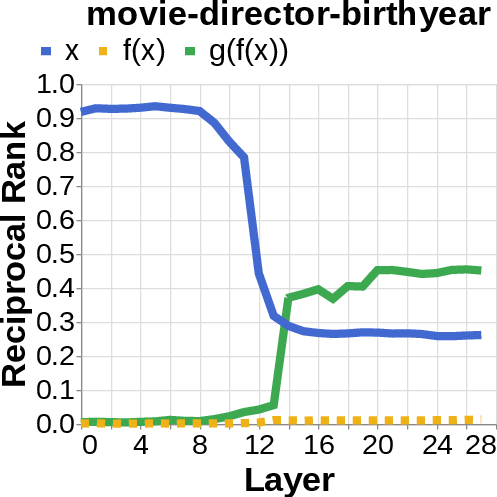
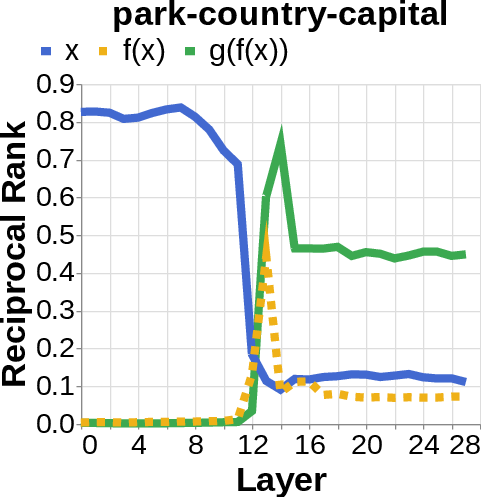
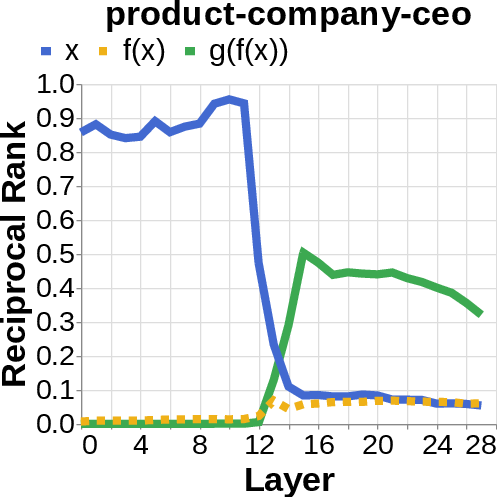
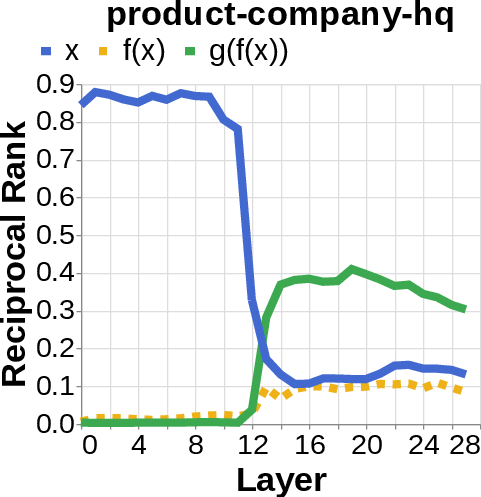
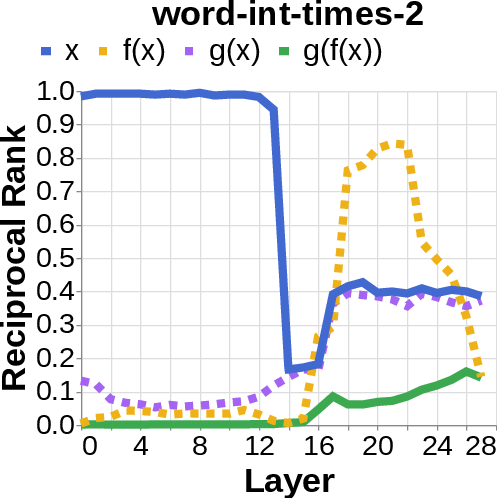
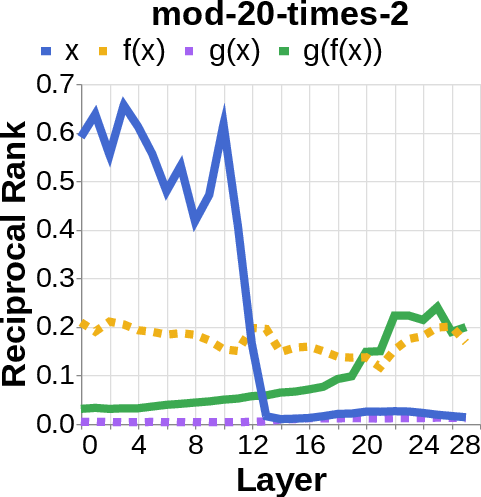
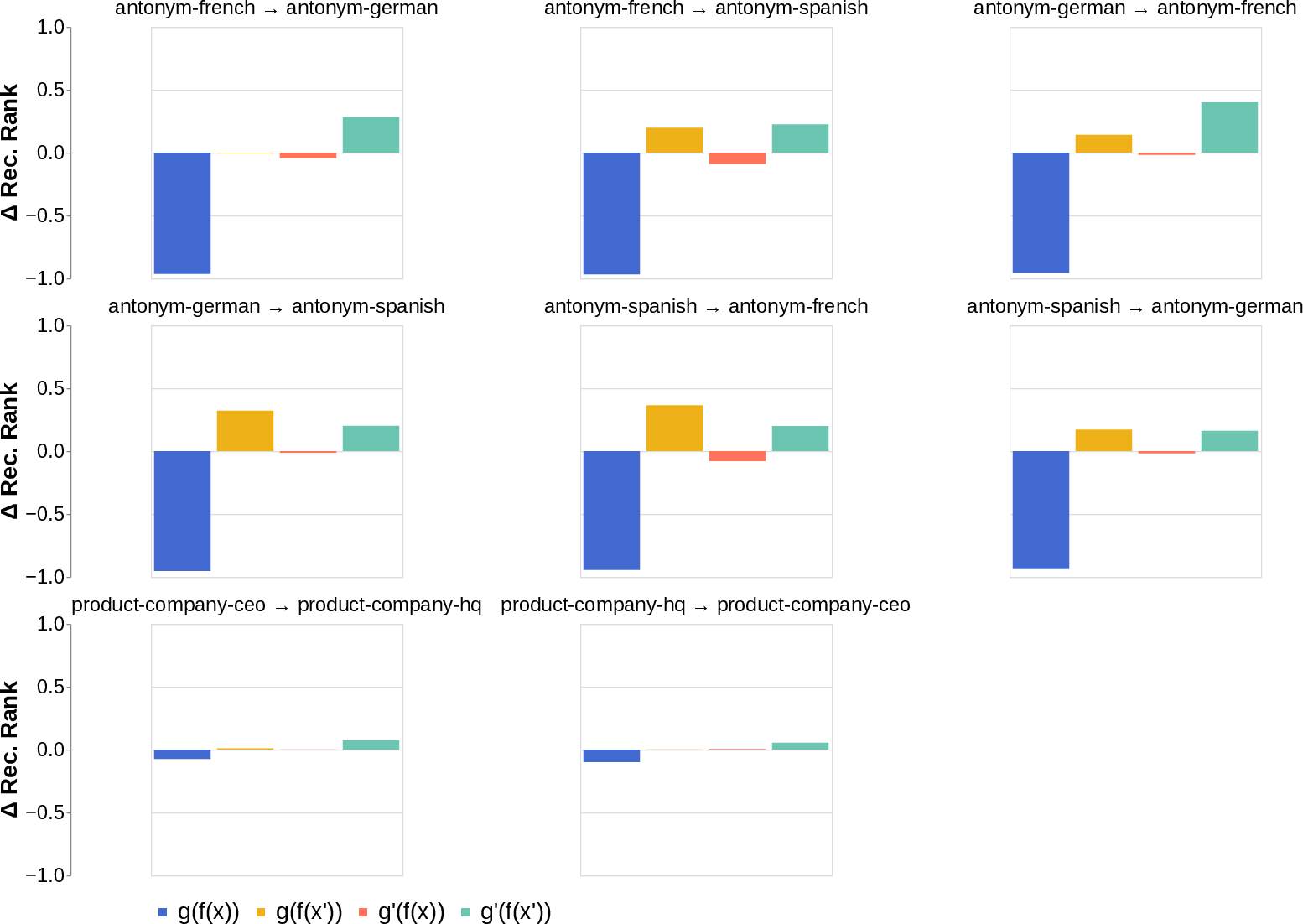
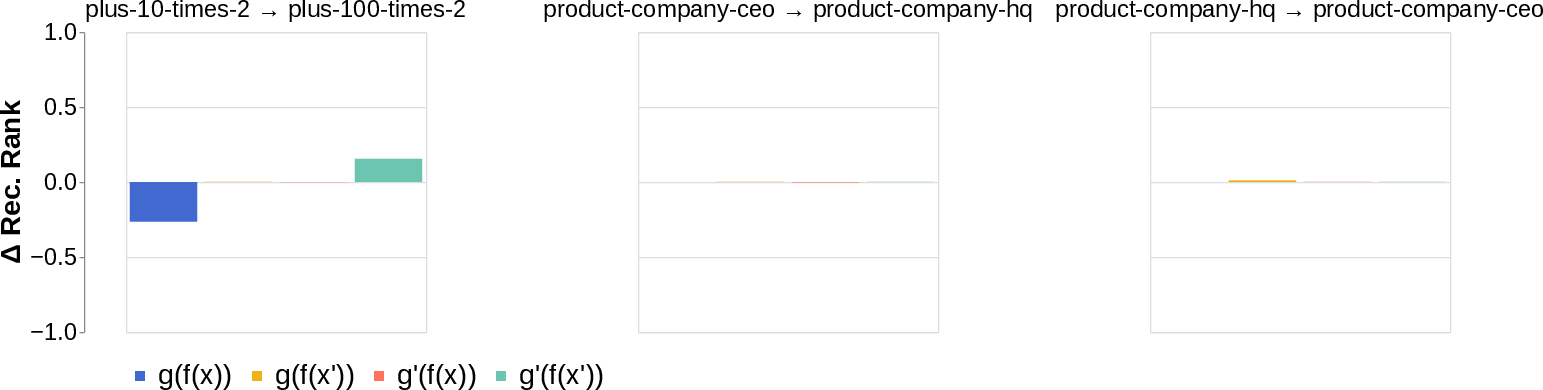
- They looked for the middle answer (like ) appearing inside the model before the final answer . If they saw the middle answer show up, that’s evidence of true two-step (compositional) thinking. If they didn’t, that suggests a direct “shortcut.”
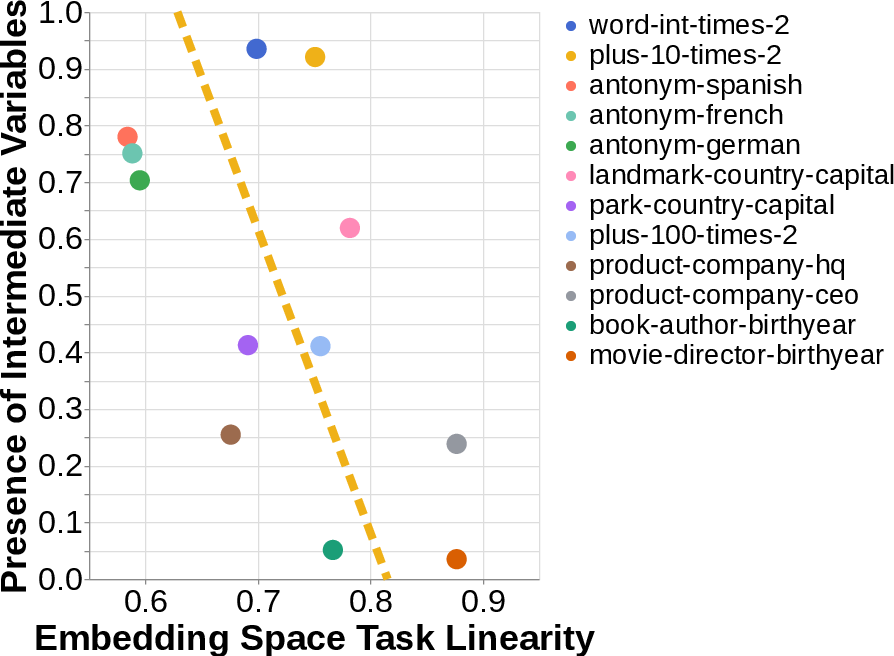
They also studied the model’s “embedding space.” Picture every word or item as a point in a big map. A “linear mapping” is like a straight rule that takes you from one point to another without curves. They checked whether the two-step relation could be represented by a simple straight rule from input to final output. If it could, the model might be more likely to jump directly to the final answer.
4. Main findings and why they matter
Here are the core findings:
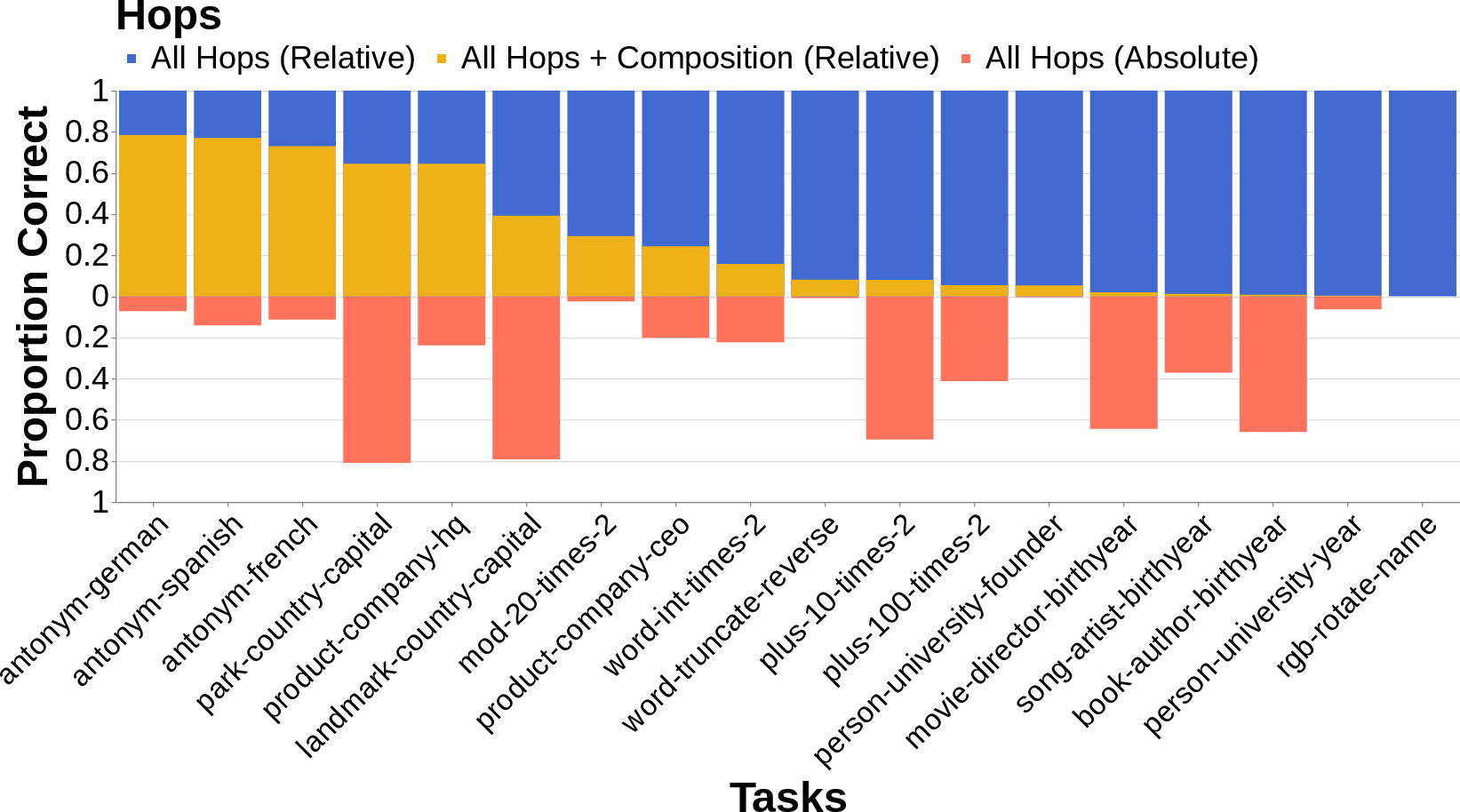
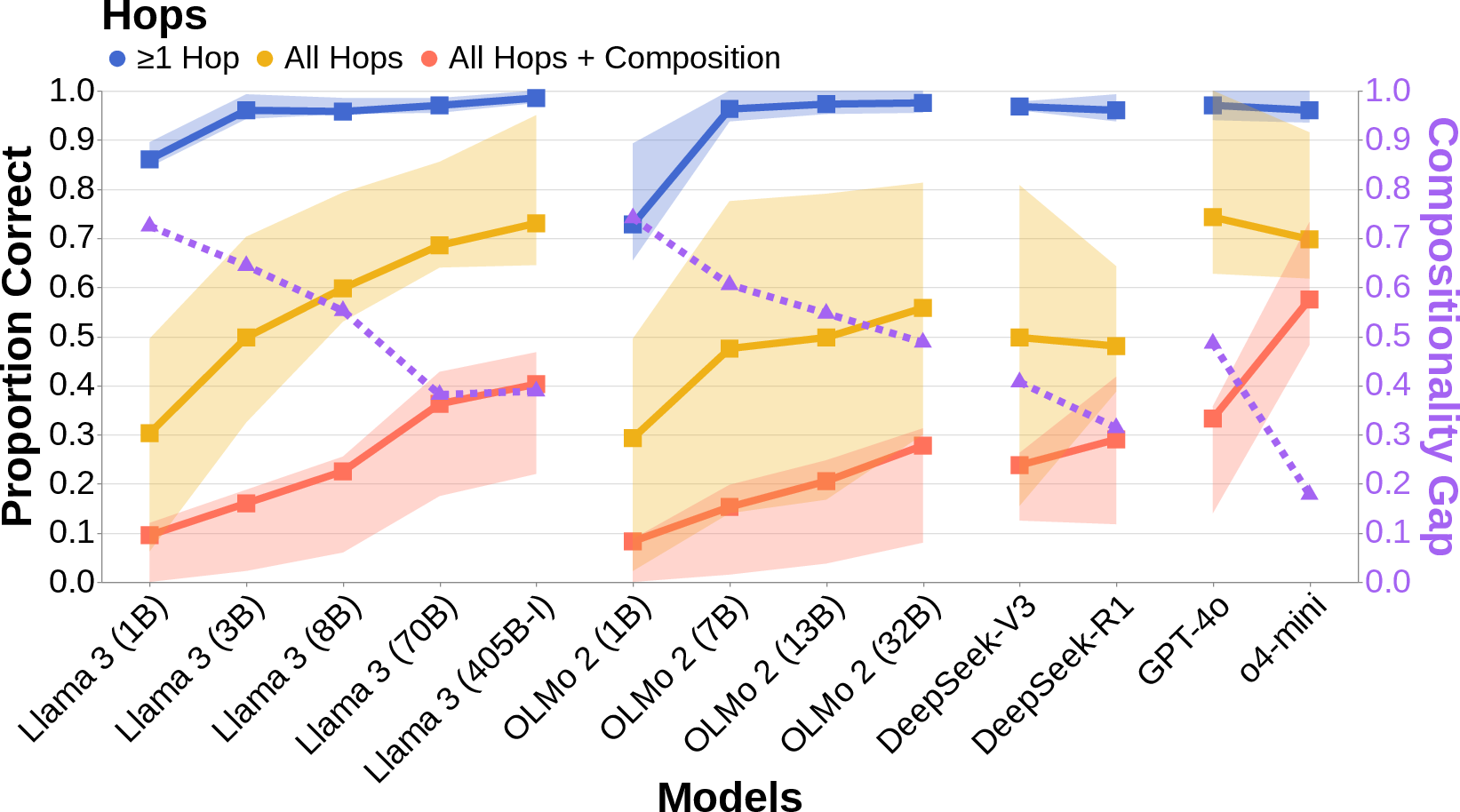
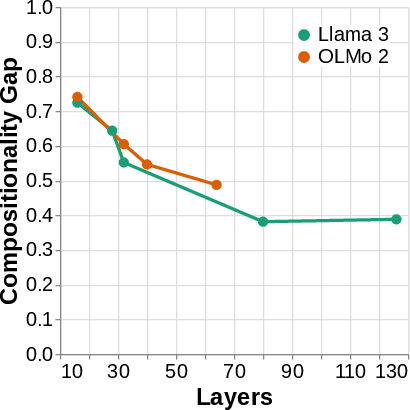
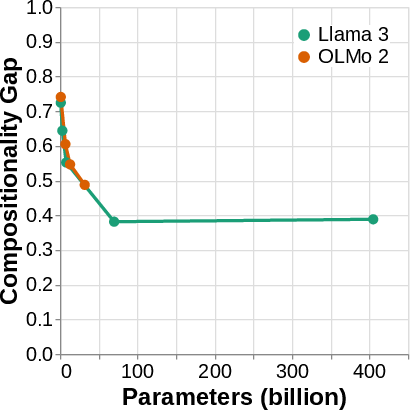
- The compositionality gap is real: Models often can do step 1 () and step 2 () separately, but still fail to do both together (). This gap appears across many tasks and models, and doesn’t just disappear by using bigger models. Some “reasoning” models help reduce the gap, but it still often remains.
- Two different solving styles exist:
- Compositional style: The model shows a detectable middle answer () internally before producing the final answer .
- Direct style: The model outputs the final answer without any visible trace of the middle step. It’s as if it “knows” the final result directly.
- Importantly, both styles can produce correct answers; accuracy doesn’t strongly tell you which style the model used.
- The choice between styles depends on the model’s internal geometry:
- If there’s a simple, straight-line rule (a linear mapping) from input to the final output inside the model’s embedding space, the model tends to use the direct style.
- If that straight-line shortcut isn’t there, the model is more likely to show the middle step and use compositional processing.
Why this matters: It shows that even when tasks look like they require two steps, LLMs don’t have to think that way. Sometimes they truly “do the steps”; other times they use shortcuts that come from how their knowledge is stored.
5. What this means going forward (implications)
- Training and design: If we want models to generalize better (handle new combinations they haven’t seen), encouraging true two-step processing could help. Direct shortcuts may work on familiar data but might break on new cases.
- Interpretability and trust: Knowing whether a model uses intermediate steps helps us understand and debug mistakes. It also helps us design tests that reveal when a model is relying on a fragile shortcut.
- Theory of intelligence: The results support a mixed picture: models (and perhaps people) sometimes use clean step-by-step reasoning and other times rely on “idiomatic” shortcuts. Which one shows up can depend on how well the knowledge is represented inside the model.
- Practical takeaway: Simply making a model bigger doesn’t guarantee strong compositional reasoning. Better training methods, prompts, or architectures that promote intermediate steps might be needed.
The authors also share their data and code so others can test and build on these ideas.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed as concrete directions future researchers can act on.
- Multi-token outputs: The study restricts generation to one token; it is unknown whether the same mechanistic patterns hold when , , or are multi-token (e.g., names, dates split across tokens). Evaluate compositions requiring multi-token outputs and adapt decoding/metrics accordingly.
- Beyond two hops: Only two-hop compositions are analyzed. Do the “compositional” vs “direct” mechanisms persist, interact, or shift with 3+ hop functions, nested compositions, or deeper pipelines?
- Causal status of intermediate variables: The presence/absence of via logit-lens/patchscope is correlational. Systematically test causality by targeted activation patching, head/MLP ablations, and causal scrubbing across layers and token positions.
- Token-position coverage: Analysis focuses on a limited set of residual streams. Probe whether (or ) is represented at other token positions (e.g., within in-context examples, separators, or earlier prompt tokens) or stored in KV-cache rather than the final-step residual.
- Decoder limitations: Logit lens and token-identity patchscopes may miss nonlinear/subspace encodings. Train alternative probes (e.g., sparse autoencoders, linear/nonlinear probes per layer, feature dictionary methods) to detect masked/superposed intermediate features.
- Mechanism localization: The study does not identify specific attention heads/MLPs implementing and . Map and ablate circuits for each hop; test necessity/sufficiency via component-level interventions.
- Prompt design sensitivity: Only a fixed Q/A format with 10 shots is used. Measure how prompt wording, number/order of shots, presence of distractors/anti-examples, and explicit function annotations (naming ) affect both accuracy and mechanism choice.
- Decoding strategy: Results use greedy decoding. Assess whether sampling, temperature, or nucleus settings change the observed mechanisms and the compositionality gap.
- Model coverage: Most mechanistic analyses use Llama 3 (3B). Replicate across sizes, tokenizers, tied/untied embeddings, training regimes (instruction-tuned vs base), and architectures (e.g., mixture-of-experts, long-context, retrieval-augmented, reasoning models) to test mechanism robustness.
- Reasoning models: The compositionality gap decreases for some “reasoning” models, but mechanisms are not analyzed. Inspect their internal traces to see whether they actually compute more often, or exploit different direct paths.
- Embedding linearity hypothesis — causality: The link between embedding-space linearity and mechanism choice is correlational. Establish causality by manipulating linearity (e.g., controlled finetuning, counterfactual pretraining curricula) and observing mechanism shifts.
- Linearity measurement choices: Linearity is estimated with an average input embedding mapped to the first-token unembedding. Evaluate per-layer/per-position linear maps, multi-token targets, cross-validation robustness, and alternative linear/affine parametrizations.
- Data frequency and confounds: The study posits a relation to pretraining frequency but does not measure it. Quantify and control for entity/fact frequency, co-occurrence, and lexical confounds to disentangle representation linearity from data popularity.
- Alternative hop order: Some tasks permit . It remains unclear when models choose this path vs . Design disambiguating tasks and analyze path selection and switching conditions.
- Generalization link: The paper does not test whether compositional processing yields better systematic/OOD generalization. Create splits where and are seen but their compositions are withheld, and correlate mechanism usage with generalization.
- Robustness to distractors: The study does not probe robustness to misleading or conflicting in-context examples. Test whether distractors preferentially break direct mechanisms or induce shifts toward compositional processing.
- Mechanism predictability at the instance level: Compositionality signals appear bimodal across examples, but predictors are unknown. Build instance-level predictors (e.g., embedding norms, nearest-neighbor structure, lexical category) for mechanism choice and validate with interventions.
- Timing and “hopping too late”: Although layerwise signatures are presented, the paper does not formalize how hop timing relates to failures. Quantify a “hop timing” metric and test whether earlier resolution prevents errors.
- Span-level intermediate variables: Detection focuses on token-level variables. Develop methods to detect multi-token intermediate representations (e.g., span probes, sequence-level decoders) and reassess “direct” vs “compositional” judgments.
- Copying vs parametric recall: It is unclear whether success relies on copying from in-context examples vs parametric memory. Separate these by using out-of-context entities, adversarial ICL examples, or zero-shot settings and compare mechanisms.
- Chain-of-thought and intermediate supervision: The study does not test whether prompting for intermediate or adding auxiliary losses shifts mechanisms and reduces the gap. Evaluate explicit intermediate supervision and its impact on both behavior and internal processing.
- Alternative algorithms for arithmetic-like tasks: Arithmetic might be solved by algorithmic circuits not captured by the current analyses. Use mechanistic arithmetic benchmarks to differentiate algorithmic computation from direct linear mappings.
- Tokenization effects: The one-token constraint interacts with specific tokenizations (e.g., numbers, names). Compare across tokenizers and detokenization schemes to see whether observed mechanisms persist.
- Evaluation metric scope: Exact-match may undercount partially correct or compositional intermediate successes. Add graded metrics (e.g., logit margins, edit distance, partial-credit for correct ) to more precisely link mechanism to performance.
- KV-cache and attention dynamics: The role of attention patterns and KV-cache states in storing/transforming is not addressed. Analyze attention head routing, query-key interactions, and cache-level interventions during hop transitions.
- Distribution shift sensitivity: It remains unknown whether mechanism choice is stable under domain shift (e.g., rare entities, different languages, code). Test across domains and languages to probe the hypothesized link to representation linearity.
- Training-time interventions to close the gap: The paper identifies the gap but does not propose/train methods to reduce it. Explore pretraining/finetuning strategies (e.g., curriculum on compositions, auxiliary hop-prediction losses) and measure resultant mechanism changes.
- Reproducibility across seeds and contexts: Layerwise logit-lens signatures could vary with stochasticity or small prompt changes. Quantify variance across random seeds, example orderings, and alternative few-shot selections.
- Disentangling “direct” from “undetected”: The operationalization of “direct mechanism” is the absence of a decodable . Validate this by stronger detection pipelines and by actively suppressing potential channels to confirm true direct computation.
Practical Applications
Immediate Applications
Below is a set of actionable, sector-linked uses that can be deployed with current models and tooling, drawing directly on the paper’s findings (compositionality gap, dual mechanisms, and embedding-space linearity) and methods (logit lens, patchscopes, residual stream analysis). Each item includes assumptions and dependencies that affect feasibility.
- Compositionality Gap Audit and Risk Scoring for LLM Deployments (Software, Finance, Healthcare)
- Use the paper’s evaluation protocol to quantify a model’s “compositionality gap” on domain-specific two-hop tasks (e.g., transaction → compliance rule → risk, symptom → diagnosis → treatment dose). Integrate the resulting score into model acceptance gates and reliability dashboards.
- Assumptions/Dependencies: Access to representative two-hop task datasets; ability to run inference in controlled settings; willingness to incorporate new reliability KPIs into product governance.
- Mechanism-Aware Routing: Switch to “reasoning” models when intermediate signals are weak (Software, Education, Customer Support)
- Apply the heuristic from the paper (reciprocal rank of intermediate variables via logit lens or token-identity patchscope) to detect low compositional processing. If the signal is weak or absent, route the query to a higher-accuracy, slower “reasoning” model; otherwise, use a fast base model.
- Assumptions/Dependencies: Access to residual streams/unembedding for open models (closed APIs may limit visibility); latency and cost budget for routing; model diversity in the stack.
- Intermediate-Variable Verification in High-Stakes Workflows (Healthcare: Clinical Decision Support; Finance: Compliance; Legal: Policy Drafting)
- Require the model (or the surrounding system) to explicitly compute and log the intermediate variable f(x) before producing g(f(x)), and compare intermediate outputs to authoritative sources (e.g., EHRs, knowledge bases). Flag answers lacking strong intermediate representation for manual review.
- Assumptions/Dependencies: Integrations with external data sources; operational processes to review/override outputs; privacy controls for logs.
- Embedding Linearity Scanner to Predict Shortcut Risk (Software, Data Science)
- Fit the linear map from input embeddings to output unembeddings for domain tasks (as in the paper) to estimate whether relations are decodable via a direct mapping. High linearity suggests a tendency toward “direct” processing (shortcut use). Use this to prioritize tasks that need explicit reasoning scaffolds.
- Assumptions/Dependencies: Access to model internals for embeddings/unembeddings; domain datasets labeled for f(x) and g(f(x)); statistical expertise to manage overfitting and distribution shift.
- Prompt and ICL Template Design to Encourage Compositional Processing (Education, Customer Support, Enterprise Knowledge)
- Apply prompting patterns that surface f(x) explicitly (e.g., “Step 1: find the director; Step 2: output the birth year”), especially for tasks where the paper shows direct processing dominates. Use Q/A templates proven in the study to obtain consistent inputs for interpretability tools.
- Assumptions/Dependencies: Prompting may not overcome all shortcut behavior; needs A/B testing and telemetry; some proprietary models may compress internal steps even with structured prompts.
- Mechanistic Monitoring Library (“Compositionality Monitor”) using the released code (Software Tooling)
- Package logit-lens-based monitors into a lightweight library that runs alongside inference for open-source models, reporting intermediate-variable presence, layer localization, and residual-stream crossover points. Trigger alerts on low compositionality for selected task types.
- Assumptions/Dependencies: Works best with self-hosted/open models; adds computational overhead; requires maintaining compatibility with different model architectures.
- Domain-Specific Two-Hop Benchmarks and Gates (Finance, Healthcare, Government Services)
- Create small, curated two-hop test sets per domain (e.g., ICD code → guideline → dose; KYC rule → exception → approval) and require passing thresholds on both hops and the composition before rollouts.
- Assumptions/Dependencies: Ongoing dataset curation; internal agreement on thresholds; periodic refresh to reflect changing rules and guidelines.
- Knowledge-Retrieval First, Then Compute g(f(x)) (Software, Search/QA)
- When the intermediate-variable signal is weak, call an external retrieval agent (for f(x)) and feed the retrieved intermediate explicitly to compute g(f(x)) (e.g., “movie → director” from a KB, then “director → birth year”).
- Assumptions/Dependencies: Reliable KBs with coverage and freshness; engineering for orchestration; careful UX to expose intermediate steps to users.
Long-Term Applications
These opportunities require further research, scaling, architectural changes, or standardization and are inspired by the paper’s core insights on mechanism duality and the role of embedding-space geometry.
- Training Objectives and Curricula that Reward Compositional Mechanisms (Software, Education)
- Introduce regularizers or curricula that penalize over-reliance on direct linear shortcuts and reward correct intermediate-variable computation, improving generalization on unseen compositions.
- Assumptions/Dependencies: Access to training loops and data; robust proxies for mechanism use (beyond logit lens); careful prevention of degradation on tasks where direct mappings are beneficial.
- Neuro-Symbolic Subtask Heads / Architecture Modifications (Robotics, Healthcare, Finance)
- Build architectures with explicit intermediate heads that compute f(x) and gate g computation, maintaining logs for audits. Integrate with tool-use interfaces so intermediate outputs can be validated or fused with external systems.
- Assumptions/Dependencies: Model re-training; inference overhead; potential loss in throughput; need for careful evaluation against baseline performance.
- Standardized Compositionality Reporting and Auditing for Regulated Sectors (Policy, Healthcare, Finance)
- Define compliance requirements that mandate disclosure of compositionality gap metrics and mechanism evidence (e.g., intermediate-variable attestations) for high-stakes multi-hop decisions.
- Assumptions/Dependencies: Cross-stakeholder agreement; standard benchmarks; auditors need training and tools; potential tension with model IP for closed providers.
- Mechanism-Aware Data Curation and Pretraining Strategies (Software, Foundation Model Providers)
- Shape pretraining corpora to reduce spurious linear shortcuts for target domains and augment with synthetic multi-hop data that demands intermediate computation and discourages shallow mappings.
- Assumptions/Dependencies: Control of large-scale data pipelines; risks of unintended side effects on other capabilities; evaluation across diverse downstream tasks.
- Automated Representational Interventions (“Backpatching”-Style) in Production (Software)
- Generalize and harden interventions that inject or amplify intermediate representations when the model “hops too late” or not at all, correcting failures in multi-hop tasks without retraining.
- Assumptions/Dependencies: Reliable causal localization; stability across updates; controlled deployment frameworks to avoid regressions and brittleness.
- Sector-Specific Mechanism Guarantees (Healthcare, Finance, Public Sector)
- Design certified workflows where the system guarantees computing and logging intermediate variables (f(x)) for classes of tasks (e.g., medication dosing) before producing outputs (g(f(x))). Establish third-party certification bodies.
- Assumptions/Dependencies: Interoperability standards; trusted log storage with privacy safeguards; cost and complexity of certification.
- Generalization Studies Linking Mechanism Use to Robustness Under Shift (Academia, Industry R&D)
- Systematically test whether compositional processing (versus direct processing) yields better generalization under distribution shifts. Develop causal probes and interventions that scale beyond case studies.
- Assumptions/Dependencies: Access to diverse tasks and controlled shifts; open models or tooling from vendors; reproducibility standards and shared datasets.
- Cross-Modal Compositional Monitoring (Vision+Language, Robotics)
- Extend residual-stream decoding and intermediate-variable verification to multimodal models to ensure multi-hop steps (e.g., image region → entity → instruction) are computed and auditable.
- Assumptions/Dependencies: Mechanistic interpretability tools for multimodal architectures; standardized representations; higher compute costs.
- End-User Experiences that Surface Mechanisms (Daily Life, Education)
- Build interfaces that automatically expose intermediate steps (f(x)) and provide confidence signals based on the presence/strength of intermediate representations. Warn users when the model appears to shortcut.
- Assumptions/Dependencies: UX research to avoid cognitive overload; explainability that remains truthful despite internal complexity; alignment with privacy policies.
Notes on Feasibility and Dependencies
- Access to internals: Many immediate applications rely on residual stream and unembedding access; closed APIs may limit these, requiring vendor cooperation or proxy signals.
- Interpretability signal validity: Logit lens and token-identity decoding are correlational and may miss features or conflate them; mechanism claims should be paired with causal tests where feasible.
- Latency and cost: Mechanistic monitoring adds compute overhead; productionization needs caching, sampling strategies, or selective monitoring on high-risk tasks.
- Data availability: Domain-specific two-hop datasets must be curated and maintained; shifts in policies and guidelines demand regular updates.
- Privacy and compliance: Logging intermediate variables in healthcare/finance requires strict controls, redaction, and governance.
These applications leverage the paper’s key insights: (1) the compositionality gap persists in modern models, (2) models toggle between compositional and direct mechanisms, and (3) embedding-space linearity predicts mechanism choice. The proposed tools and workflows help detect, route, verify, and eventually shape model behavior toward safer and more generalizable multi-hop reasoning.
Glossary
- autoregressive forward pass: A single left-to-right inference step where each token’s prediction conditions on previously processed tokens. "and a single autoregressive forward pass."
- autoregressive LLMs: Models that generate text token-by-token, each conditioned on prior tokens. "autoregressive LLMs permitted one token for generation"
- backpatching: A representational intervention that edits internal activations to fix reasoning failures. "They propose a representational intervention ("backpatching") to correct failures based on this finding."
- bimodal: Having two distinct peaks in a distribution. "This distribution appears to be bimodal across all examples:"
- causal hops: The sequential intermediate steps in a multi-step computation from input to output. "yielding the causal hops ."
- commutative tasks: Tasks where applying functions in different orders yields the same result. "Some tasks (e.g. commutative tasks) can also be computed through the hops "
- compositional generalization: The ability to generalize by recombining known parts or functions in new ways. "The majority of work on compositionality in neural networks (and LLMs) concerns compositional generalization"
- compositionality gap: The phenomenon where models can solve individual steps but fail to solve their composition. "documented a "compositionality gap" in LLMs,"
- cosine similarity: A metric that measures the angle-based similarity between vectors. "measured via cosine similarity"
- embedding space geometry: The structural relationships among representations in the model’s embedding space. "related to the embedding space geometry"
- entity description patchscope: A decoding method to inspect intermediate representations via descriptions of entities. "employ the entity description patchscope \citep{ghandeharioun2024:patchscopes}"
- exact match evaluation metric: An accuracy metric that requires predictions to match gold outputs exactly. "and the exact match evaluation metric."
- greedy sampling: Decoding by selecting the highest-probability token at each step. "greedy sampling"
- idiomatic mechanism: A direct, non-compositional processing strategy that maps inputs to outputs without explicit intermediate variables. "with the idiomatic mechanism being dominant in cases where there exists a linear mapping from to in the embedding spaces."
- in-context learning (ICL): Conditioning a model on examples within the prompt to perform a task without parameter updates. "using in-context learning (ICL)"
- input embedding space: The vector space where input tokens are represented before processing. "from in the input embedding space to in the output unembedding space"
- instruction-tuned: A model variant fine-tuned to follow task instructions and user prompts. "“-I” indicates the instruction-tuned variant of Llama 3 (405B)."
- language modeling head: The final projection layer mapping hidden states to vocabulary logits. "using the language modeling head."
- least squares regression: A linear fitting method minimizing the sum of squared errors. "using least squares regression"
- linear mapping: A single linear transformation that directly relates inputs to outputs in representation space. "there exists a linear mapping from to in the embedding spaces."
- logit lens: An interpretability method that projects hidden activations into vocabulary space using the LM head. "We specifically use logit lens"
- MLPs: Transformer feed-forward sublayers that perform learned nonlinear transformations on token states. "was localized to specific computations in the MLPs."
- reciprocal rank: The inverse of the rank position, used to quantify how prominently a target appears in a decoded list. "measure the reciprocal rank of our variables at each layer"
- residual stream activations: The running hidden representation updated by residual connections across layers. "using logit lens on their residual stream activations"
- token identity patchscope: A decoding method that reveals which token identity is represented in a hidden state. "using the token identity patchscope \citep{ghandeharioun2024:patchscopes}"
- unembedding space: The output space where hidden states are mapped back to vocabulary logits. "to its unembedding space."
Collections
Sign up for free to add this paper to one or more collections.

