- The paper demonstrates that transferrable task representations form at specific tokens, enhancing zero-shot task performance when appropriately injected.
- It employs various algorithmic and natural language tasks across model scales to analyze evidence accrual and the dynamics of task vector formation.
- The study reveals that task information decays over long or mixed-generation tasks, highlighting limits in representation persistence and potential areas for model improvement.
Just-in-time and Distributed Task Representations in LLMs
The paper "Just-in-time and distributed task representations in LLMs" (2509.04466) explores the formation and dynamics of task representations in LLMs during in-context learning (ICL). This investigation focuses on "transferrable" task representations, which can reinstate task contexts independently of full prompts, providing insights into how models infer and adapt to new tasks based on minimal input cues.
Introduction
In-context learning is a critical capability of LLMs, allowing them to perform new tasks by leveraging a few-shot prompt without weight updates (Gołębiewski et al., 2024). The central hypothesis of this paper is that task representations evolve in complex ways, distinct from the high-level task identity representations that persist across context (2509.04466). This study aims to understand when these transferrable task representations form, how they change across context, and their dependence on task complexity.
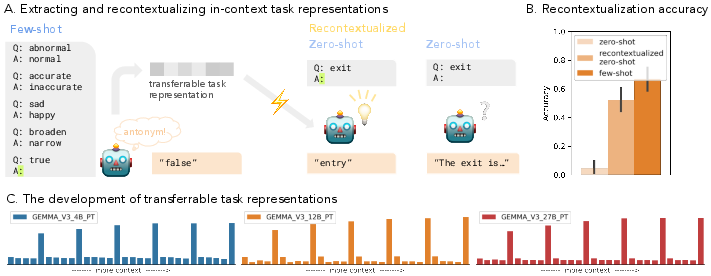
Figure 1: Understanding how task representations develop over context. A schematic of extracting transferrable task representations and restoring task contexts in zero-shot settings.
Methods
Task Selection
The tasks chosen for analysis include both simple algorithmic tasks and natural language tasks, ranging from antonym and translations to complex counting and list manipulation tasks. These tasks allow for the examination of different dynamics and complexities within task representation formation (Davidson et al., 17 May 2025).
Model Architecture
The study focuses on the Gemma V3 pre-trained models at varying scales (4B, 12B, 27B), leveraging open-weight architectures to provide accessible insights into task representation dynamics (Team et al., 25 Mar 2025).
Task vectors are extracted from key tokens within few-shot contexts, primarily from the last colon token preceding answer generation. These vectors are injected into zero-shot contexts to test their ability to restore task performance without explicit context information (2509.04466).
Evaluation Metrics
Task accuracy is evaluated in standard zero-shot, recontextualized zero-shot (with task vector intervention), and few-shot conditions. Accuracy is determined by exact string match against ground-truth answers, measured across various outputs for longer-generation tasks (Li et al., 2024).
Results
Task vectors demonstrate robust evidence accrual across examples, improving task performance in zero-shot settings when task vectors are extracted from multiple examples (Figure 2). However, this process is non-gradual, activating sporadically at certain tokens. For some tasks, transferrable task representations do not accrue evidence effectively, particularly those requiring extensive state tracking (2509.04466).
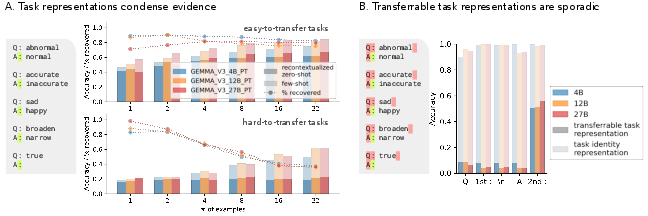
Figure 2: Sporadic, inconsistent evidence accrual in LLMs, indicating varied success in recontextualized zero-shot accuracy across different tasks.
Temporal Locality of Task Representations
The study reveals that transferrable task representations form at specific, isolated tokens rather than continuously throughout the context, demonstrating a just-in-time computational behavior. While general task identity is decodable across the entirety of the context, effective transferrable representations appear at only certain points (Gołębiewski et al., 2024).
Scope Locality and Complex Tasks
Transferrable task representations support minimal task scopes, fading over longer-generation tasks or mixed-generation tasks (Figure 3). This suggests that LLMs internally segment tasks into smaller, semantically independent units, thus limiting the effective range of transferrable task representations (Li et al., 2024).
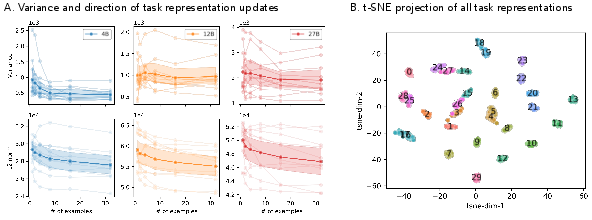
Figure 3: Reinstantiated task contexts in longer- and mixed-generation tasks often decay, highlighting the locality and limited scope support of task representations.
Discussion
This paper challenges the intuitive notion that LLMs smoothly refine task states. Instead, the computational process for task adaptation and inference is highly localized. The preference for compressing task information into discrete tokens underscores a potential inductive bias favoring efficient representation formation over temporal persistence (Gołębiewski et al., 2024).
Implications
These findings have significant implications for mechanistic interpretability and model safety, highlighting areas where task representations may fail, such as complex and state-dependent tasks. Understanding the bounds of task representation formation could guide improvements in model architectures and training methods, particularly for tasks requiring richer, distributed representations (Davidson et al., 17 May 2025).
Conclusion
The dynamics of in-context learning reveal complex, intra-token task representation formations that diverge from a continuous and stable task state model. These insights offer a nuanced view of how LLMs adapt to and infer tasks, emphasizing a just-in-time approach critical for natural language processing advancements. These findings suggest further exploration into learning mechanisms to fully harness the potential of transferrable task representations across complex linguistic tasks.

