VideoSSR: Video Self-Supervised Reinforcement Learning
Abstract: Reinforcement Learning with Verifiable Rewards (RLVR) has substantially advanced the video understanding capabilities of Multimodal LLMs (MLLMs). However, the rapid progress of MLLMs is outpacing the complexity of existing video datasets, while the manual annotation of new, high-quality data remains prohibitively expensive. This work investigates a pivotal question: Can the rich, intrinsic information within videos be harnessed to self-generate high-quality, verifiable training data? To investigate this, we introduce three self-supervised pretext tasks: Anomaly Grounding, Object Counting, and Temporal Jigsaw. We construct the Video Intrinsic Understanding Benchmark (VIUBench) to validate their difficulty, revealing that current state-of-the-art MLLMs struggle significantly on these tasks. Building upon these pretext tasks, we develop the VideoSSR-30K dataset and propose VideoSSR, a novel video self-supervised reinforcement learning framework for RLVR. Extensive experiments across 17 benchmarks, spanning four major video domains (General Video QA, Long Video QA, Temporal Grounding, and Complex Reasoning), demonstrate that VideoSSR consistently enhances model performance, yielding an average improvement of over 5\%. These results establish VideoSSR as a potent foundational framework for developing more advanced video understanding in MLLMs. The code is available at https://github.com/lcqysl/VideoSSR.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “VideoSSR: Video Self-Supervised Reinforcement Learning”
What is this paper about?
This paper is about teaching AI systems to understand videos better. It focuses on “multimodal” AI models (MLLMs), which can look at pictures and videos and also read and write text. The authors introduce a new way to train these models using videos themselves—without needing people to label or write questions for the videos. Their method is called VideoSSR, and it uses self-made tasks and rewards to improve how well AI understands what happens in videos.
What questions are the researchers trying to answer?
The paper asks a simple but important question:
- Can we use the rich information already inside videos to create high-quality training tasks and rewards, so AI can learn video understanding on its own?
They also explore:
- How to make these self-made tasks both challenging and checkable (so the model’s answers can be verified).
- Whether training on such tasks helps AI perform better across many different video-related tests.
How did they do it? (Methods explained simply)
The authors design three clever training tasks that work directly on videos. Think of them like practice games for the AI:
- Before listing them, here’s the idea: each task changes or uses parts of a video in a controlled way, so the correct answer is known and can be checked automatically—no humans needed.
- The three tasks are:
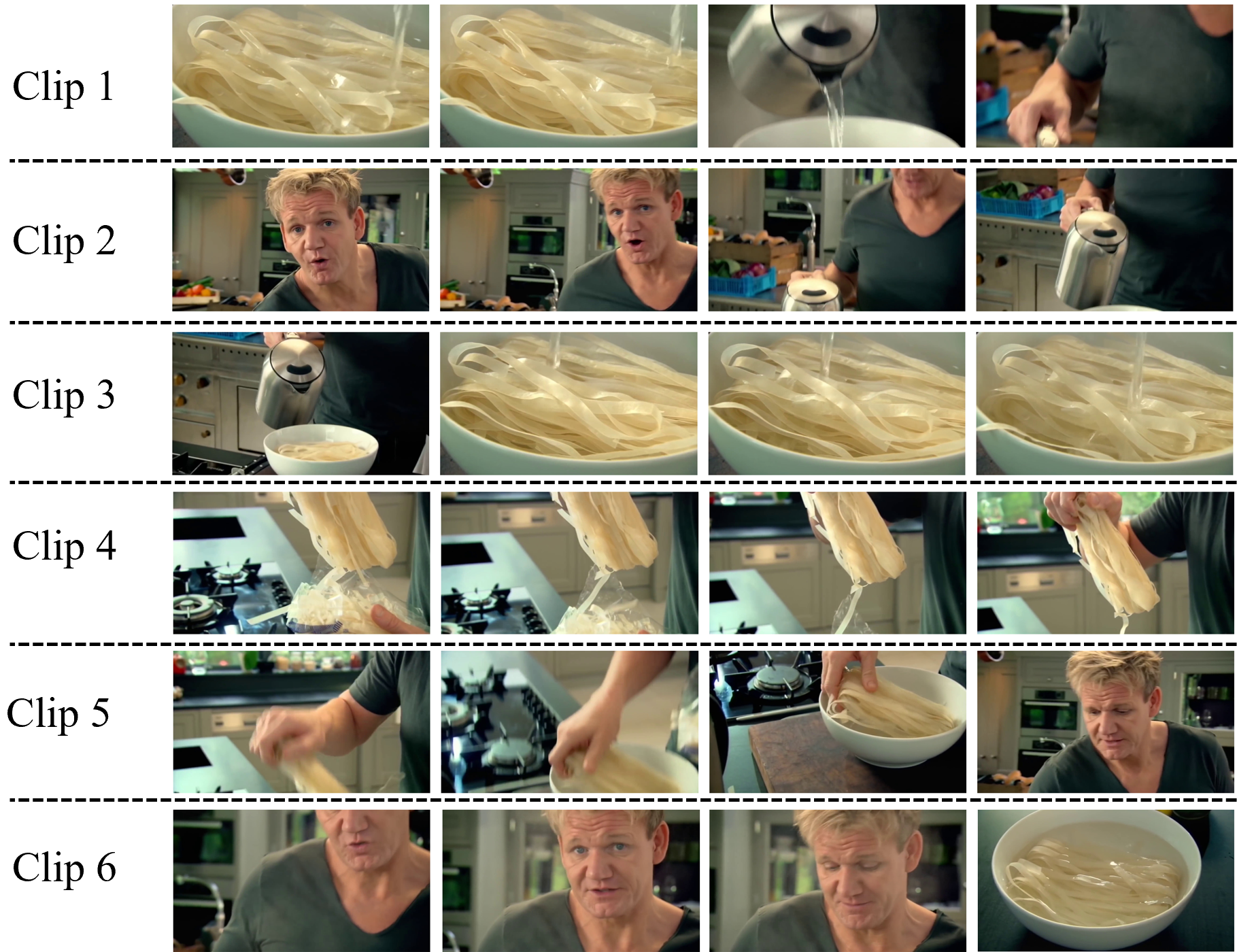
- Anomaly Grounding: Imagine someone secretly flips part of a video upside down, swaps colors, zooms out, mirrors it, or shuffles frames inside a short time window. The AI must find the exact start and end times of that “weird” segment. This teaches the model to notice when the video’s normal flow is broken.
- Object Counting: The system adds simple shapes (like circles, triangles, rectangles) onto a few frames—like placing stickers on certain scenes. The AI must count how many of each shape appear in the whole video. This trains careful, fine-grained visual attention.
- Temporal Jigsaw: The video is cut into several pieces and shuffled. The AI has to put the pieces back in the correct order—like solving a puzzle. This builds an understanding of time and sequence: what happened first, next, and last.
To make learning smoother, they give “partial credit” rewards:
- Instead of only “right” or “wrong,” they score answers on a scale.
- For Anomaly Grounding, they give a higher score when the predicted time window overlaps more with the true window (like giving points for being close).
- For Object Counting, they reward answers that are near the correct count, not just exactly correct.
- For the Jigsaw, they score how far each segment is from the correct position, rewarding near-correct orders.
They also built:
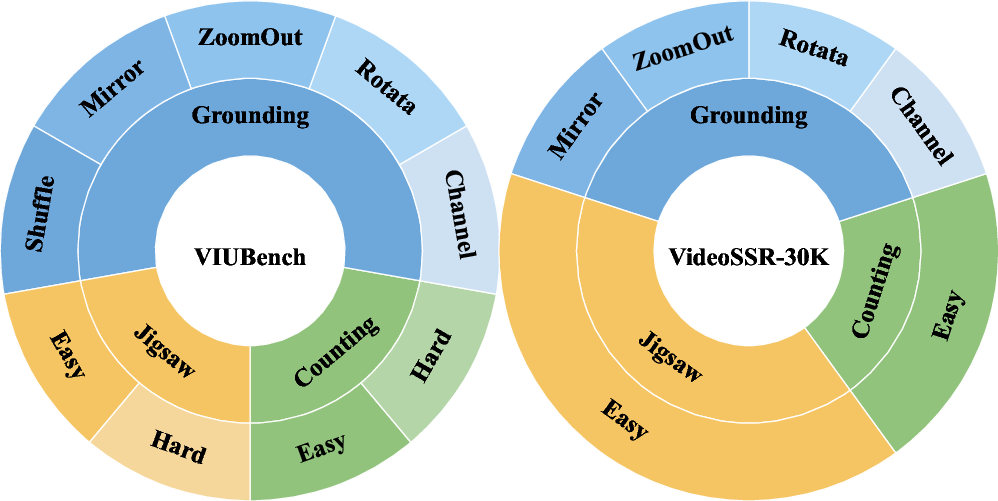
- VIUBench: A new test set to measure how hard these tasks are. It includes many examples from the three tasks.
- VideoSSR-30K: A 30,000-example training set generated automatically from videos using those tasks.
Finally, they use a reinforcement learning method (think: try answers, get rewards, adjust behavior) called RLVR with GRPO. This means the AI generates several answers, gets a reward for each based on how verifiable and close to correct they are, and then updates to improve.
What did they find, and why is it important?
- Current datasets are often too easy or too biased. Many questions produce either all correct answers or all wrong answers when asked multiple times. That’s like practicing with tests that are either trivial or broken—you don’t learn much.
- VIUBench is truly challenging. Even very advanced models struggled, showing these tasks uncover gaps in video understanding—especially in fine details and time order.
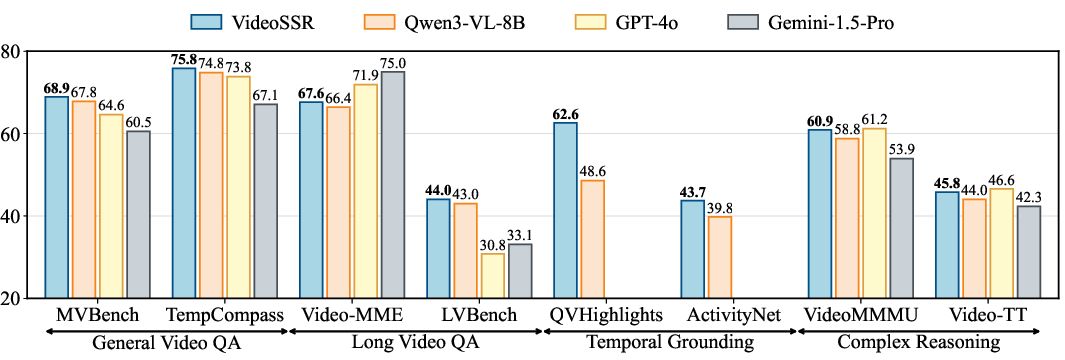
- Training with VideoSSR improved performance across 17 different benchmarks in four areas:
- General Video Q&A (answering questions about short videos),
- Long Video Q&A (handling longer stories),
- Temporal Grounding (finding the right time in a video for a described event),
- Complex Reasoning (harder, multi-step thinking).
- On average, the model improved by over 5%. In some tests, the gains were large—for example:
- Big boosts in tasks that require finding exact moments in videos (Temporal Grounding),
- Strong improvements in tests that depend on understanding event order (Complex Reasoning),
- Notable gains in time-related question answering (like VinoGround).
Why this matters:
- It shows that you can make AI better at understanding videos without hiring people to label everything.
- It avoids the biases that come from human or weaker AI annotations.
- It gives models “practice” that matches real video challenges—seeing small changes, keeping track of time, and understanding sequences.
What does this mean for the future?
- Cheaper, scalable training: Since the tasks create their own questions and answers from raw videos, we can train on huge amounts of video without the usual cost of labeling.
- Less bias, more reliability: The rewards are based on facts directly from the video edits (like where the anomaly is), so they’re fair and dependable.
- Adjustable difficulty: The tasks can be made harder or easier (for example, more shapes to count or more video pieces to reorder), so they can keep challenging future, stronger models.
- Stronger general video intelligence: These skills—spotting anomalies, counting precisely, and understanding order—are core to many real-world applications: sports highlights, security cameras, classroom recordings, and more.
In short, VideoSSR is a practical way to help AI truly learn from videos themselves, becoming better at seeing, timing, and reasoning—without needing endless human-labeled data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete list of what remains missing, uncertain, or unexplored, to guide follow-up research:
- Data scale and scaling laws
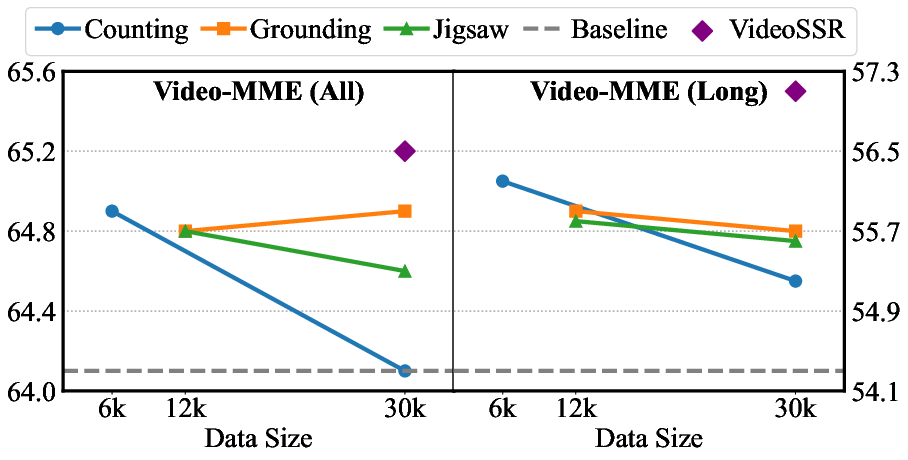
- The self-supervised dataset is capped at 30K samples; no scaling-law analysis (data size vs. performance) or saturation curves are provided.
- It is unclear whether gains continue with 100K–1M+ examples, or how benefits scale across different pretext-task mixtures and difficulties.
- Base-model generality and portability
- Experiments fine-tune only Qwen3-VL-8B; transferability to other architectures (e.g., InternVL, LLaVA-Video, Flamingo-like models) and model sizes is not tested.
- No study of whether pretraining-time vs. post-hoc RLVR fine-tuning stages interact differently with VideoSSR.
- Long-video understanding constraints
- Training and evaluation are mostly limited to ≤64 frames at 2 FPS; improvements on truly long videos (10–60+ minutes) under high frame counts or streaming settings remain untested.
- Integration with memory mechanisms, hierarchical encoders, or segment-level recurrence for long contexts is not explored.
- Dataset provenance and leakage control
- The source, licensing, and domain coverage of videos used to synthesize VIUBench and VideoSSR-30K are not detailed; potential test-set overlap with downstream benchmarks is not ruled out.
- No analysis of domain balance (egocentric vs. third-person, sports/news/UGC) or its effect on generalization.
- Artifact exploitation risk in synthetic tasks
- Models may learn to detect synthetic overlays or perturbation artifacts (e.g., compression seams, aliasing, color quantization) rather than the intended visual/temporal concepts; no adversarial or artifact-controlled evaluation is provided.
- No ablation with artifact-mitigated synthesis (e.g., photorealistic compositing, neural rendering, optical-flow-consistent overlays).
- Ambiguity in task definitions and labels
- Anomaly Grounding can be ambiguous for symmetric or static scenes where rotations/mirroring are indistinguishable; no filtering or uncertainty handling is described.
- Temporal Jigsaw assumes a single correct order; videos with repeated or periodic segments admit multiple valid permutations, but the evaluation penalizes all but one.
- Reward design limitations
- Temporal Jigsaw uses a displacement-based reward normalized by a reversed sequence; alternatives (e.g., Kendall tau, pairwise adjacency accuracy, longest increasing subsequence reward) aren’t evaluated.
- Object Counting reward normalizes by y_k; behavior when y_k=0 or small is brittle even with epsilon; alternative shaping (e.g., Huber/Poisson losses, capped penalties) is not explored.
- No analysis of reward sensitivity, reward hacking, or robustness to output formatting errors (e.g., number parsing from text).
- RL algorithm and stability analysis
- Only GRPO is used; comparisons to other RLVR variants (DAPO, GSPO, PPO/IMPALA variants), off-policy methods, or hybrid supervised+RL pipelines are absent.
- No sensitivity studies on rollout count, KL coefficient, sampling temperature, or initialization; no variance across seeds or confidence intervals.
- Curriculum and task scheduling
- Difficulty is statically parameterized; there is no adaptive curriculum (automatic difficulty adjustment, self-paced learning, or bandit-based task selection).
- The mixture proportions across pretext tasks are fixed; principled mixture optimization or online rebalancing to avoid negative transfer is not attempted.
- Prompting and format robustness
- Question/answer templates, prompt diversity, and parsing rules (for timestamps and counts) are not documented; robustness to prompt variation and formatting errors is unknown.
- The decision to avoid chain-of-thought (CoT) is motivated by hallucination concerns, but the impact of structured rationales or constrained decoding on performance and stability is not evaluated.
- Skill transfer to semantic reasoning
- Pretext tasks are largely low-level or structural; the mechanism by which they transfer to high-level semantic QA and reasoning is not dissected.
- No correlation analysis between VIUBench scores and downstream benchmark improvements to validate VIUBench as a predictor of real-world gains.
- Modalities and supervision breadth
- Audio is ignored; extensions to audio-visual pretext tasks (e.g., audio-visual synchronization anomalies, cross-modal jigsaws) are unexplored.
- Motion-specific signals (optical-flow consistency, trajectory tracking, causal temporal interventions) are not leveraged as pretext targets.
- Negative transfer and safety checks
- Some perturbation types negatively impact downstream performance; no systematic method is provided to detect and exclude harmful transformations a priori.
- No robustness evaluation under distribution shift (motion blur, occlusion, camera shake) or adversarial perturbations.
- Temporal annotation precision
- Timestamp granularity, rounding rules, and tolerance windows for Anomaly Grounding are unspecified; sensitivity to FPS and sampling strategies is not examined.
- Compute and efficiency trade-offs
- Only a single compute budget (8×H200, ~16 hours) and one-epoch RLVR are reported; sample efficiency vs. compute trade-offs, and optimal training duration, remain unknown.
- Combination with supervised or multi-agent data
- How VideoSSR interacts with (or complements) curated human/agent-annotated datasets and standard supervised fine-tuning is not studied.
- Joint training schedules (e.g., alternating self-supervised RLVR with supervised RLVR) are not investigated.
- Failure analyses and diagnostics
- There is little qualitative analysis of failure cases on VIUBench and downstream tasks; specific error modes (temporal misordering vs. spatial mislocalization vs. counting confusion) are not cataloged.
- Benchmarking scope and fairness
- Closed-source baselines are reported without standardized frame caps; a matched-frame ablation would clarify the true comparative advantage at equal input budgets.
- Some improvements are marginal; statistical significance is not reported.
- Generalization beyond vision-language QA
- Transfer to embodied decision-making, planning, or interactive video tasks (e.g., video-conditioned control) is untested.
- Extensibility of the pretext family
- The space of intrinsic-video tasks is only partially explored; open avenues include:
- Object permanence and occlusion consistency tasks.
- Temporal causal order verification (A causes B).
- Cycle-consistency under time-warping.
- Multi-object tracking consistency with synthetic but photoreal overlays.
- Data curation and quality control
- Automated detection of cases where perturbations fail (e.g., too subtle/occluded) is not implemented; no confidence scoring or quality filters for synthesized samples.
- Reproducibility details
- Seeds, exact video lists, and preprocessing pipelines (downsampling, cropping) are not fully specified; end-to-end reproducibility (including exact prompt templates and parsers) is unclear.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the open-source code, datasets, and training recipes introduced in the paper. Each item specifies relevant sectors, potential tools/workflows, and key assumptions/dependencies.
- Self-supervised data engine for video RL training (software/ML)
- What: Use the VideoSSR-30K construction pipeline to automatically generate verifiable, diverse video training tasks without human or MLLM annotation.
- Tools/workflows: “VideoSSR-30K Builder” + GRPO-based RLVR training script; CI pipeline to refresh training sets from unlabeled video lakes.
- Assumptions/dependencies: Access to large unlabeled video corpora; compatible MLLM backbone (e.g., Qwen3-VL-8B); GPU budget; organizational approval for using internal video.
- Benchmarking and capability diagnostics with VIUBench (academia, software/ML, standards)
- What: Use VIUBench to stress-test fine-grained perception, spatial perception, and temporal coherence in MLLMs and to track regressions.
- Tools/workflows: “VIUBench Runner” integrated into model eval dashboards; red/amber/green scorecards per capability axis.
- Assumptions/dependencies: Standardized evaluation metrics (mIoU, exact-match); reproducible inference settings; agreement on score thresholds.
- Stable RL training via smooth reward functions (software/ML)
- What: Drop-in “Smooth Reward Library” (IoU for anomaly grounding, relative-error for counting, displacement-normalized reward for jigsaw) to reduce sparse-reward failure in RLVR.
- Tools/workflows: GRPO training with reward adapters; ablation logging.
- Assumptions/dependencies: GRPO or similar RLVR loop; support for custom reward shaping; monitoring of KL/divergence constraints.
- Immediate performance boosts for video QA, temporal grounding, and reasoning (media tech, search, enterprise video analytics)
- What: Fine-tune existing MLLMs on VideoSSR-30K for consistent ~5% average gains across 17 benchmarks, with notable improvements on QVHighlights, ActivityNet, VCRBench, and VinoGround.
- Tools/workflows: “VideoSSR Trainer” starting from Qwen3-VL-8B; evaluation on MVBench/Video-MME/LongVideoBench.
- Assumptions/dependencies: Base model capacity; correct fps/frame limits; domain generalization from intrinsic tasks to target datasets.
- Event timestamp localization in enterprise video (security/surveillance, manufacturing, media)
- What: Use strengthened temporal grounding to locate start/end of relevant events (e.g., safety incidents, customer interactions, scene changes).
- Tools/workflows: “Temporal Locator” service consuming long video, outputting segments with confidence scores.
- Assumptions/dependencies: Domain adaptation from intrinsic tasks; precise time alignment; acceptable latency.
- Content integrity and editing QA (media production, broadcast, advertising)
- What: Flag unnatural segments (rotations/mirroring/shuffles) and detect splices or out-of-order cuts in production pipelines.
- Tools/workflows: “Edit Anomaly Checker” in NLE plugins; automated QC before distribution.
- Assumptions/dependencies: Mapping synthetic anomalies to real editorial artifacts; thresholds tuned to production norms.
- Automatic chaptering and timeline alignment in education videos (education technology)
- What: Improved temporal coherence understanding to auto-chapter lectures, reorder out-of-sequence recordings, and align slides to speech segments.
- Tools/workflows: “Lecture Chapterer” pipeline; slide-to-video alignment module.
- Assumptions/dependencies: Sufficient speech-vision alignment; clean audio/video timestamps.
- Retail/transport counting tasks through improved fine-grained perception (retail, smart city)
- What: Transfer improved counting and perception to people/vehicle/item counting in store aisles, entrances, or intersections.
- Tools/workflows: “Domain Counting Adapter” fine-tuned on labeled target domain; dashboards for occupancy and flow.
- Assumptions/dependencies: Domain-specific labeled data for adaptation; camera placement; privacy compliance.
- Sports analytics and highlight generation (media/sports tech)
- What: Segment key plays and generate highlight reels with better temporal grounding and event ordering.
- Tools/workflows: “Highlight Editor” that proposes timestamps and narrative sequences; operator-in-the-loop curation.
- Assumptions/dependencies: Access to feeds/metadata; per-sport heuristics; latency constraints.
- Reduced annotation costs for academic labs and industry R&D (academia, software/ML)
- What: Replace multi-agent/manual labeling with self-supervised task generation for continuous pretraining and RLVR fine-tuning.
- Tools/workflows: “Self-Supervised Data Lake” that regularly produces new tasks with controlled difficulty; weekly model refresh.
- Assumptions/dependencies: Sufficiently diverse unlabeled sources; governance for data use.
- Compliance and privacy-friendly training workflows (policy, enterprise)
- What: Minimize human exposure to sensitive footage by using self-generated verifiable tasks in RLVR.
- Tools/workflows: “Privacy-first RLVR” SOPs; audit trails showing no external annotation used.
- Assumptions/dependencies: Internal policy acceptance; verifiable processes; legal review of data processing.
- Lightweight deployment for camera-side analytics with 8B models (IoT/edge, security)
- What: Deploy fine-tuned smaller models for on-prem event localization or clip ordering where cloud offload is limited.
- Tools/workflows: “Edge Temporal Agent” with frame sampling controls; summary alerts.
- Assumptions/dependencies: Edge accelerators; bandwidth constraints; power budgets.
Long-Term Applications
These applications require further research, domain adaptation, scale-up, or productization to reach robust, real-world deployment.
- General-purpose video agents leveraging intrinsic self-supervision (software/ML, consumer tech)
- What: Always-on assistants that watch and understand long-form video (home, workplace, classroom) for summarization, alerts, and retrieval.
- Tools/workflows: “Video Agent Platform” combining self-supervised RLVR pretraining with user-specific calibration.
- Assumptions/dependencies: Long-context modeling; safety/consent; strong on-device performance.
- Autonomous robotics and drones with better temporal reasoning (robotics)
- What: Use VideoSSR-style training to improve temporal sequencing, anomaly detection, and action planning from raw videos and demonstrations.
- Tools/workflows: “Temporal Policy Learner” combining video jigsaw rewards with downstream imitation/RL.
- Assumptions/dependencies: Closed-loop control integration; sim-to-real transfer; safety certification.
- Healthcare video diagnostics (healthcare)
- What: Anomaly grounding for procedural videos (endoscopy, ultrasound) to flag suspicious segments and reduce miss rates.
- Tools/workflows: “Clinical Anomaly Finder” co-pilot for physicians, with explainable timestamps and confidence.
- Assumptions/dependencies: FDA/CE approvals; domain-specific pretext tasks; curated clinical datasets.
- Autonomous driving and ADAS video understanding (automotive)
- What: Temporal coherence and event ordering for incident reconstruction, cut-in detection, and sensor fusion QA.
- Tools/workflows: “Drive Timeline Auditor” for replay analysis; self-supervised pretraining on fleet data.
- Assumptions/dependencies: Scale of unlabeled fleet video; privacy policies; integration with perception stacks.
- Compliance auditing from video in industrial settings (policy, manufacturing, energy)
- What: Automated detection and timestamping of safety violations, equipment anomalies, and process deviations.
- Tools/workflows: “Compliance Video Auditor” with policy libraries and review queues.
- Assumptions/dependencies: Domain adaptation; robust false-positive control; union/regulatory acceptance.
- Standardized governance for self-supervised video training (policy, standards)
- What: Develop guidelines for using unlabeled video in AI training, including provenance, consent, and auditing of reward signals.
- Tools/workflows: “Self-Supervision Governance Toolkit” aligned with organizational AI policies.
- Assumptions/dependencies: Industry-wide coordination; regulator engagement.
- Marketplace for plug-in pretext tasks and reward shapers (software/ML ecosystem)
- What: Expand beyond three tasks to domain-specific pretexts (e.g., motion continuity checks, audio-visual sync) with modular reward functions.
- Tools/workflows: “Pretext Store” for composable task packs and evaluation adapters.
- Assumptions/dependencies: API standards; community curation; security vetting.
- Edge-first video cognition with long-context streaming (IoT/edge)
- What: Continuous understanding of multi-hour streams at the camera, including timeline construction and event forecasting.
- Tools/workflows: “Streaming Temporal Engine” with frame scheduling and incremental RL updates.
- Assumptions/dependencies: Efficient memory architectures; thermal/power constraints; hardware roadmaps.
- Personal digital memory from video (consumer tech)
- What: Automatically reorder out-of-sequence recordings, chapter personal videos, and provide “what happened when” summaries.
- Tools/workflows: “Personal Timeline Builder” integrated into photo/video apps.
- Assumptions/dependencies: User consent; on-device compute; privacy-preserving indexing.
- Reduced dataset bias and sustainable scaling of video MLLMs (academia, software/ML)
- What: Replace dependence on weaker annotators with intrinsic, parametrically challenging tasks to keep pace with model capabilities.
- Tools/workflows: “Difficulty Scheduler” that adapts pretext parameters as models improve.
- Assumptions/dependencies: Ongoing research showing transfer to diverse downstream tasks; careful monitoring for hidden biases in source video.
Cross-cutting assumptions and dependencies
- Data availability and rights: Access to large, diverse, unlabeled video datasets with clear provenance and legal permission to process.
- Compute and infrastructure: GPUs/accelerators; scalable RLVR pipelines; monitoring of KL penalties, reward sparsity, and training stability.
- Base model capacity: Benefits demonstrated with Qwen3-VL-8B; larger/smaller models may need recipe tuning.
- Domain adaptation: While intrinsic tasks improve generalization, high-stakes domains (healthcare, automotive) require targeted fine-tuning and validation.
- Evaluation rigor: Use VIUBench and downstream task suites to avoid overfitting to synthetic pretexts; maintain reproducible inference settings (fps, frames, pixels).
- Governance and safety: Privacy-first workflows; human-in-the-loop review for deployments affecting people; alignment with regulatory standards.
Glossary
- ActivityNet: A large-scale dataset for temporal action localization used in temporal grounding evaluation. "QVHighlights~\cite{lei2021detecting} and ActivityNet~\cite{caba2015activitynet}, with gains of +15.9 and +5.6, respectively."
- AoTBench: A benchmark for general video question answering. "General Video QA: MVBench~\cite{li2024mvbench}, TempCompass~\cite{liu2024tempcompass}, AoTBench~\cite{aot}, and VinoGround~\cite{zhang2024vinoground}."
- Anomaly Grounding: A self-supervised pretext task that requires localizing a perturbed temporal segment by predicting its start and end timestamps. "we introduce three self-supervised pretext tasks: Anomaly Grounding, Object Counting, and Temporal Jigsaw."
- Bimodal distribution: A distribution with two dominant modes; here, per-question correctness tends to be either all-correct or all-wrong. "The resulting bimodal distribution of scores, with most questions exhibiting zero variance, offers an ineffective learning signal for GRPO~\cite{deepseekmath,deepseekr1} training in RLVR."
- CGBench: A benchmark for long video question answering. "Long Video QA: Video-MME~\cite{fu2025video}, LVBench~\cite{wang2024lvbench}, LongVideoBench~\cite{wu2024longvideobenchbenchmark}, and CGBench~\cite{chen2024cgbench}."
- Chain of thought: A prompting/decoding approach that elicits step-by-step reasoning in model outputs. "Chain of thought~\cite{wei2022chain} is not utilized to mitigate hallucination~\cite{luo2025thinking} and ensure correct output formatting, therefore enhancing performance."
- CharadesSTA: A dataset for temporal grounding (localizing activities aligned to text queries). "Temporal Grounding: QVHighlights~\cite{lei2021detecting}, ActivityNet~\cite{caba2015activitynet}, CharadesSTA~\cite{gao2017tall}, and TACoS~\cite{regneri2013grounding}."
- Complex Reasoning: A category of tasks requiring multi-step reasoning over video content beyond low-level perception. "Performance comparison on Temporal Grounding and Complex Reasoning tasks."
- CVBench: A benchmark focused on complex video reasoning. "Complex Reasoning: VideoMMMU~\cite{hu2025video}, Video-TT~\cite{zhang2025towards}, VCRBench~\cite{sarkar2025vcrbench}, and CVBench~\cite{zhu2025cvbench}."
- Greedy decoding: A generation strategy selecting the highest-probability token at each step to ensure reproducibility. "Greedy decoding is used to ensure reproducibility."
- GRPO: A reinforcement learning method for optimizing LLMs via group-based rollouts and policy updates. "For training, we employ RLVR using GRPO~\cite{deepseekmath,deepseekr1}."
- Ground truth: The reference labels or correct answers used for evaluation or supervision. "The ground truth is a vector of counts"
- KL divergence penalty: A regularization term that penalizes divergence from a reference policy during RL fine-tuning. "a KL divergence penalty with a coefficient of ."
- LongVideoReason: A dataset built via multi-agent collaboration that provides verifiable answers for long-video reasoning. "existing datasets, such as LongVideoReason~\cite{chen2025longvila-r1} and ReWatch~\cite{rewatch-r1}, utilize multi-agent collaboration to construct high-quality datasets with verifiable answers."
- LVBench: An extreme long video understanding benchmark. "Long Video QA: Video-MME~\cite{fu2025video}, LVBench~\cite{wang2024lvbench}, LongVideoBench~\cite{wu2024longvideobenchbenchmark}, and CGBench~\cite{chen2024cgbench}."
- Mean Intersection over Union (mIoU): The average IoU used to measure overlap between predicted and true temporal intervals. "We compute the Mean Intersection over Union (mIoU) between the predicted and ground-truth temporal intervals as the performance score."
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities, such as text and video. "In past years, Multimodal LLMs (MLLMs) have achieved remarkable progress in the field of video understanding~\cite{Qwen2.5VL,gpt4o,Gemini2.5,gemini1.5,OpenAI2025-GPT5,bai2025intern,wang2025internvl3,qwen3vl}."
- Object Counting: A pretext task requiring models to count the number of procedurally overlaid shapes by type across frames. "Object Counting: Procedurally generated shapes are overlaid onto selected frames, and the task is to count the total number of each shape type."
- Procedurally generated shapes: Synthetic geometric objects created through programmatic rules to augment video frames. "Procedurally generated shapes are overlaid onto selected frames"
- QVHighlights: A temporal grounding benchmark focusing on highlight detection in videos. "Temporal Grounding: QVHighlights~\cite{lei2021detecting}, ActivityNet~\cite{caba2015activitynet}, CharadesSTA~\cite{gao2017tall}, and TACoS~\cite{regneri2013grounding}."
- Qwen3-VL: An open-source family of vision–LLMs used as the base system in experiments. "more pronounced for the more powerful Qwen3-VL model."
- Reinforcement Learning with Verifiable Reward (RLVR): An RL paradigm where rewards are derived from automatically verifiable answers, improving model reasoning. "Reinforcement Learning with Verifiable Reward (RLVR)~\cite{deepseekmath,deepseekr1} has been shown to significantly enhance the reasoning capabilities of LLMs"
- ReWatch: A dataset constructed via multi-agent collaboration to provide high-quality, verifiable video reasoning data. "existing datasets, such as LongVideoReason~\cite{chen2025longvila-r1} and ReWatch~\cite{rewatch-r1}, utilize multi-agent collaboration to construct high-quality datasets with verifiable answers."
- Reward signal: The scalar feedback used in RL to guide model optimization. "flawed or spurious reward signals for RLVR"
- Smooth reward function: A dense and continuous reward design that reduces sparsity and stabilizes RL training. "we design corresponding smooth reward functions for each pretext task to ensure efficient and stable RLVR training."
- TACoS: A temporal grounding dataset centered on cooking activities and natural language descriptions. "Temporal Grounding: QVHighlights~\cite{lei2021detecting}, ActivityNet~\cite{caba2015activitynet}, CharadesSTA~\cite{gao2017tall}, and TACoS~\cite{regneri2013grounding}."
- Temporal coherence: The consistent ordering and flow of events across time in a video. "specifically its understanding of temporal coherence and event ordering."
- Temporal Grounding: The task of localizing time intervals in a video that correspond to a textual query. "Performance comparison on Temporal Grounding and Complex Reasoning tasks."
- Temporal Jigsaw: A self-supervised pretext task where shuffled video segments must be reordered to recover the original timeline. "Temporal Jigsaw: The video is divided into clips which are then shuffled. The task is to predict the original temporal order of the segments."
- VCRBench: A benchmark targeting complex, multi-step video reasoning. "Complex Reasoning: VideoMMMU~\cite{hu2025video}, Video-TT~\cite{zhang2025towards}, VCRBench~\cite{sarkar2025vcrbench}, and CVBench~\cite{zhu2025cvbench}."
- Video-MME: A benchmark for general and long video understanding and question answering. "Long Video QA: Video-MME~\cite{fu2025video}, LVBench~\cite{wang2024lvbench}, LongVideoBench~\cite{wu2024longvideobenchbenchmark}, and CGBench~\cite{chen2024cgbench}."
- VideoMMMU: A complex reasoning benchmark spanning multi-disciplinary video tasks. "Complex Reasoning: VideoMMMU~\cite{hu2025video}, Video-TT~\cite{zhang2025towards}, VCRBench~\cite{sarkar2025vcrbench}, and CVBench~\cite{zhu2025cvbench}."
- VideoSSR: The proposed self-supervised reinforcement learning framework that trains MLLMs using intrinsic video signals. "We introduce VideoSSR, a new Video Self-Supervised Reinforcement learning framework to enhance the video understanding of MLLM."
- VideoSSR-30K: A self-supervised dataset of 30,000 samples generated from the pretext tasks for RL training. "We construct the VideoSSR-30K dataset using the aforementioned pretext tasks"
- VinoGround: A general video QA benchmark emphasizing temporal relations and grounding. "General Video QA: MVBench~\cite{li2024mvbench}, TempCompass~\cite{liu2024tempcompass}, AoTBench~\cite{aot}, and VinoGround~\cite{zhang2024vinoground}."
- VIUBench: The Video Intrinsic Understanding Benchmark assessing fine-grained, spatial, and temporal perception via the pretext tasks. "We construct the Video Intrinsic Understanding Bench (VIUBench) to validate their difficulty"
Collections
Sign up for free to add this paper to one or more collections.